原文链接:http://tecdat.cn/?p=24162
原文出处:拓端数据部落公众号
在这个例子中,我们考虑马尔可夫转换随机波动率模型。
统计模型
设 yt为因变量,xt 为 yt 未观察到的对数波动率。对于 t≤tmax,随机波动率模型定义如下
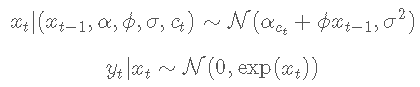
状态变量 ct 遵循具有转移概率的二状态马尔可夫过程
![]()
N(m,σ2)表示均值 m 和方差 σ2的正态分布。
BUGS语言统计模型
文件内容 'vol.bug':
dlfie = 'vol.bug' #BUGS模型文件名
设置
设置随机数生成器种子以实现可重复性
set.seed(0)加载模型和数据
模型参数
-
-
dt = lst(t_mx=t_mx, sa=sima,
-
alha=alpa, phi=pi, pi=pi, c0=c0, x0=x0)
解析编译BUGS模型,以及样本数据
modl(mol_le, ata,sl_da=T)
绘制数据
plot(1:tmx, y, tpe='l',xx = 'n')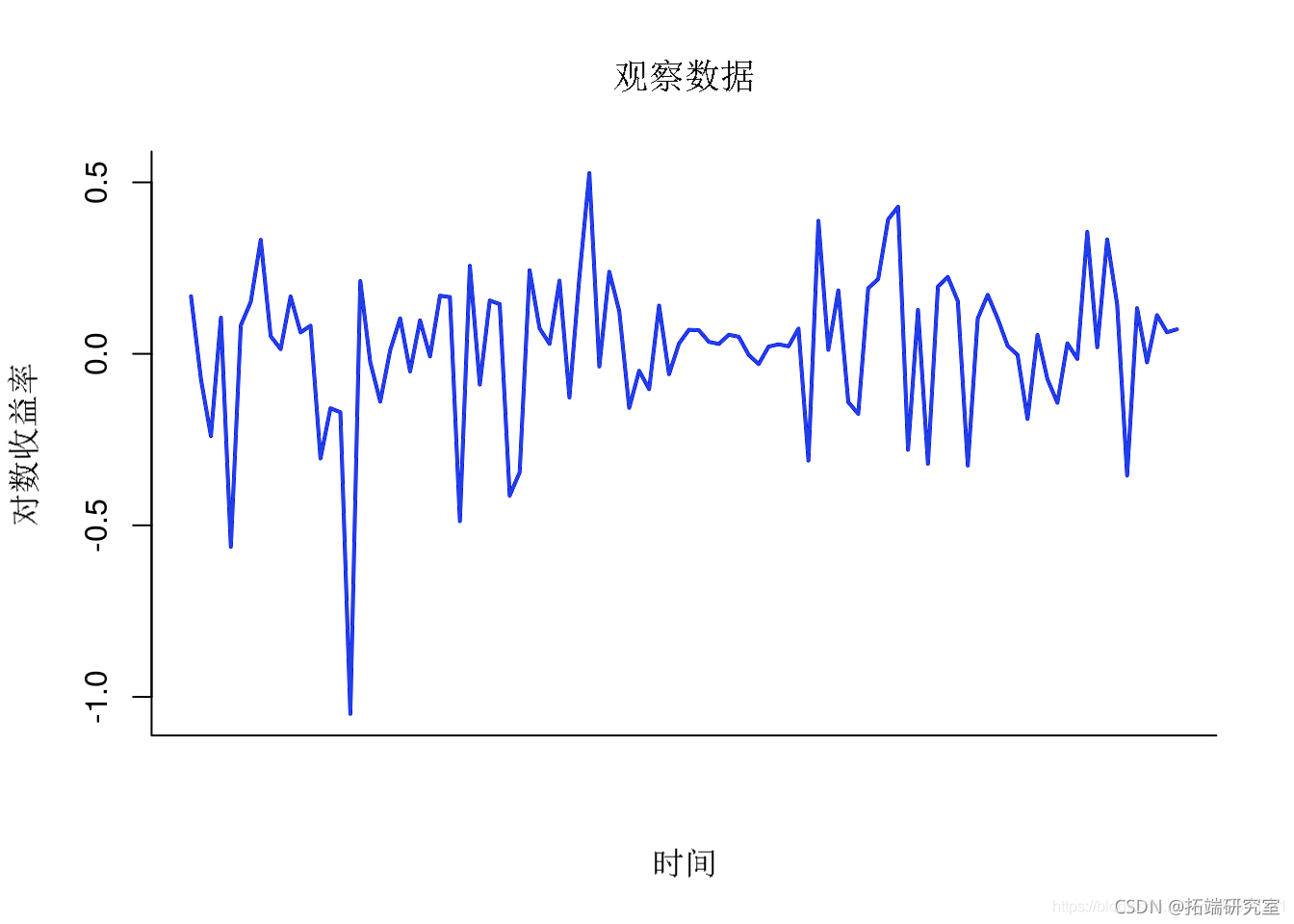
对数收益率
序列蒙特卡罗Sequential Monte Carlo
运行
-
n= 5000 # 粒子的数量
-
var= c('x') # 要监测的变量
-
out = smc(moe, vra, n)

模型诊断
diagnosis(out)
绘图平滑 ESS
-
plt(ess, tpe='l')
-
lins(1:ta, ep(0,tmx))

SMC:SESS
绘制加权粒子
-
plt(1:tax, out,)
-
for (t in 1:_ax) {
-
vl = uiq(valest,])
-
wit = sply(vl, UN=(x) {
-
id = utm$$sles[t,] == x
-
rtrn(sm(wiht[t,ind]))
-
})
-
pints(va)
-
}
-
lies(1t_x, at$xue)
-
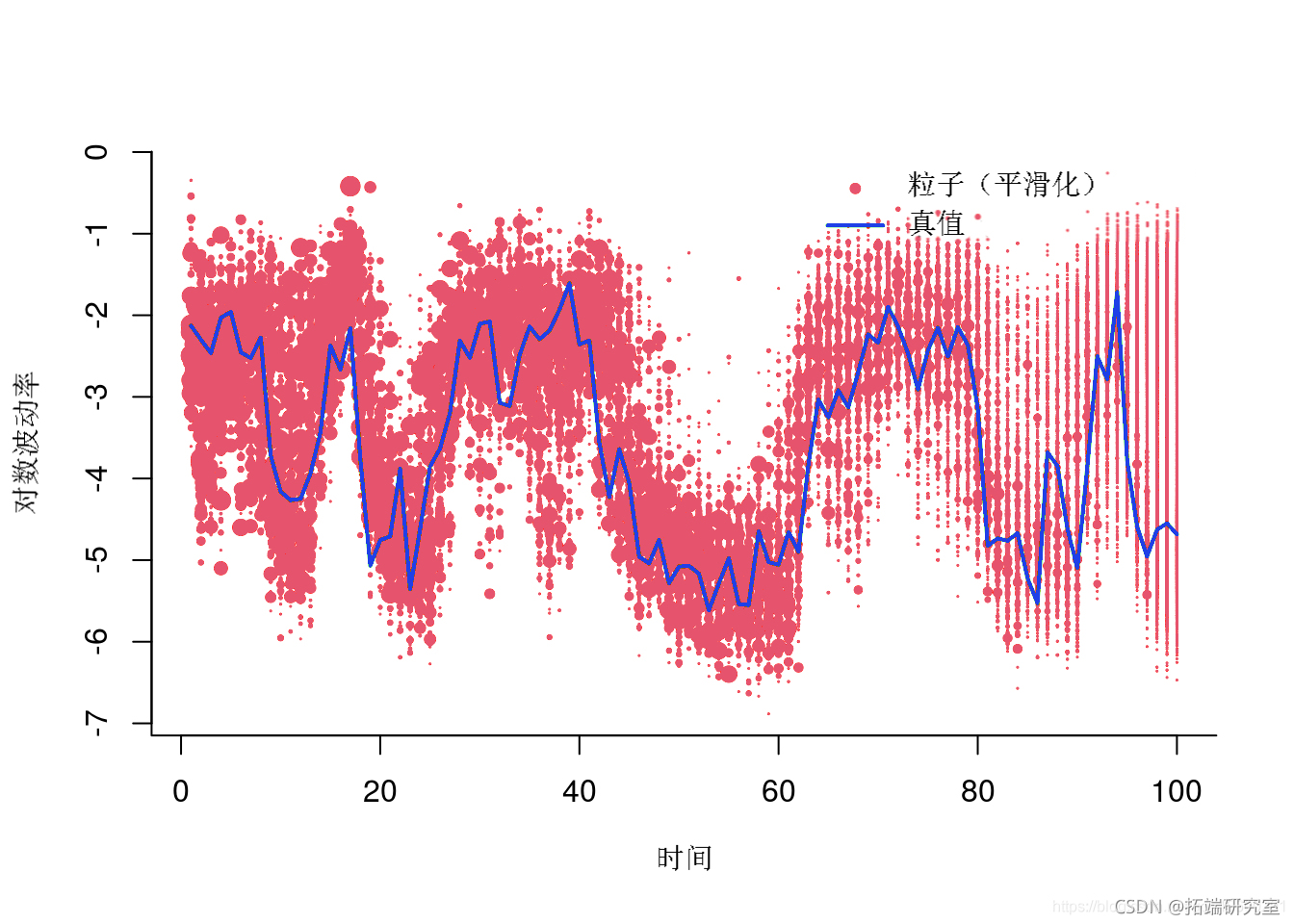
粒子(平滑)
汇总统计
summary(out)绘图滤波估计
-
men = mean
-
qan = quant
-
-
x = c(1:tmx, _a:1)
-
y = c(fnt, ev(x__qat))
-
plot(x, y)
-
pln(x, y, col)
-
lines(1:tma,x_ean)
-
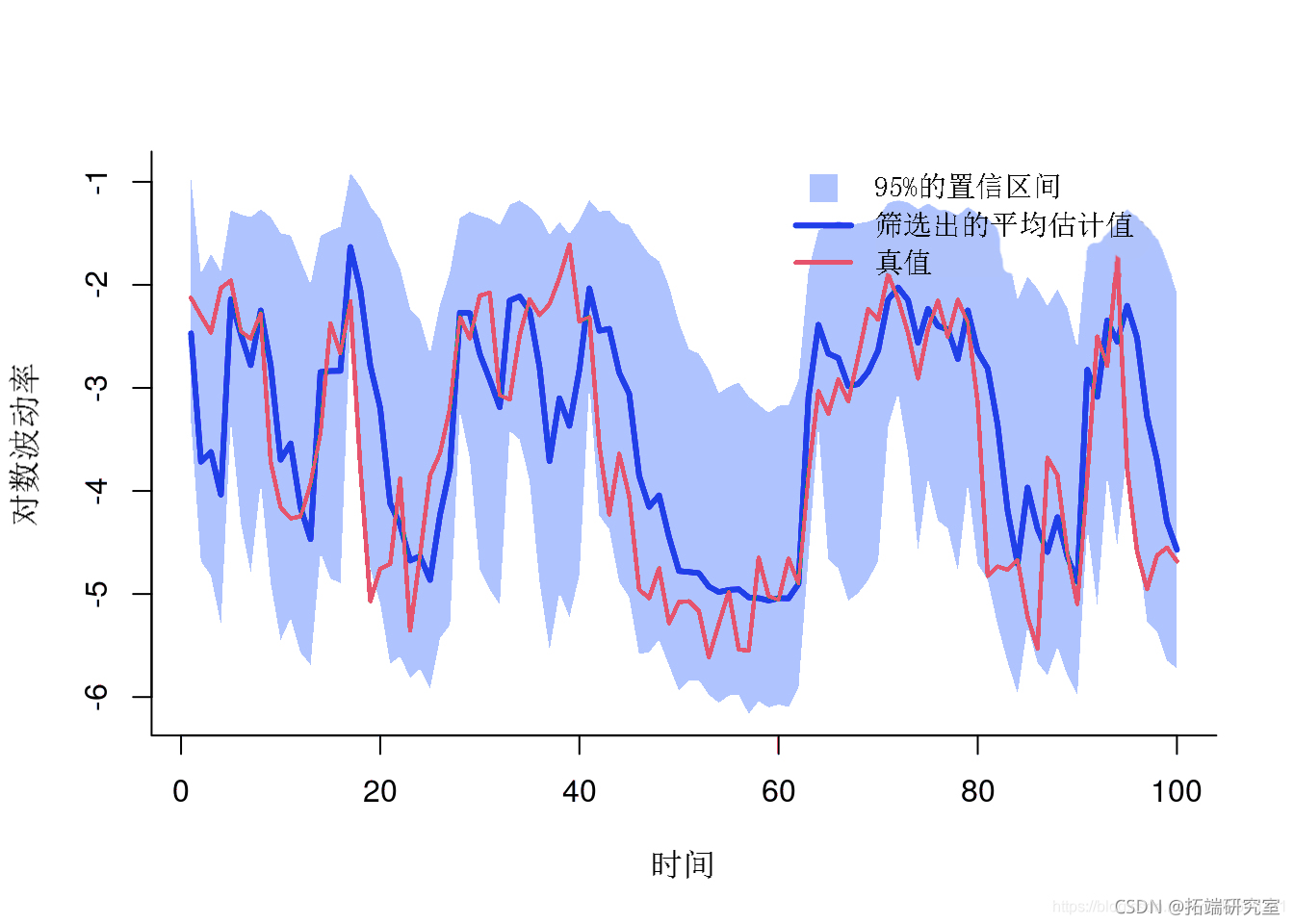
滤波估计
绘图平滑估计
-
-
plt(x,y, type='')
-
-
polgon(x, y)
-
lins(1:tmx, mean)
-
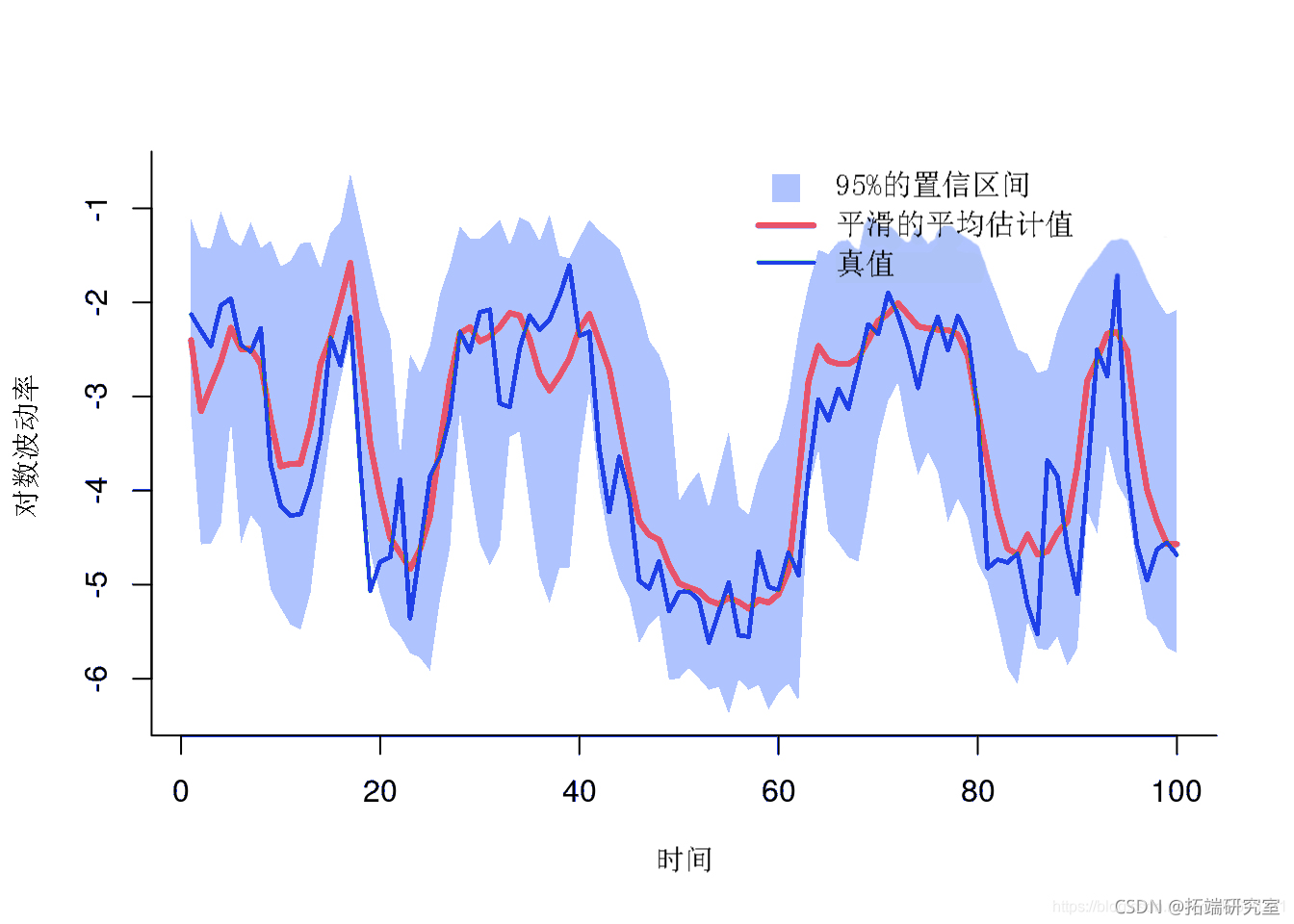
平滑估计
边缘滤波和平滑密度
-
denty(out)
-
indx = c(5, 10, 15)
-
-
for (k in 1:legh) {
-
inex
-
plt(x)
-
pints(xtrue[k])
-
}
-
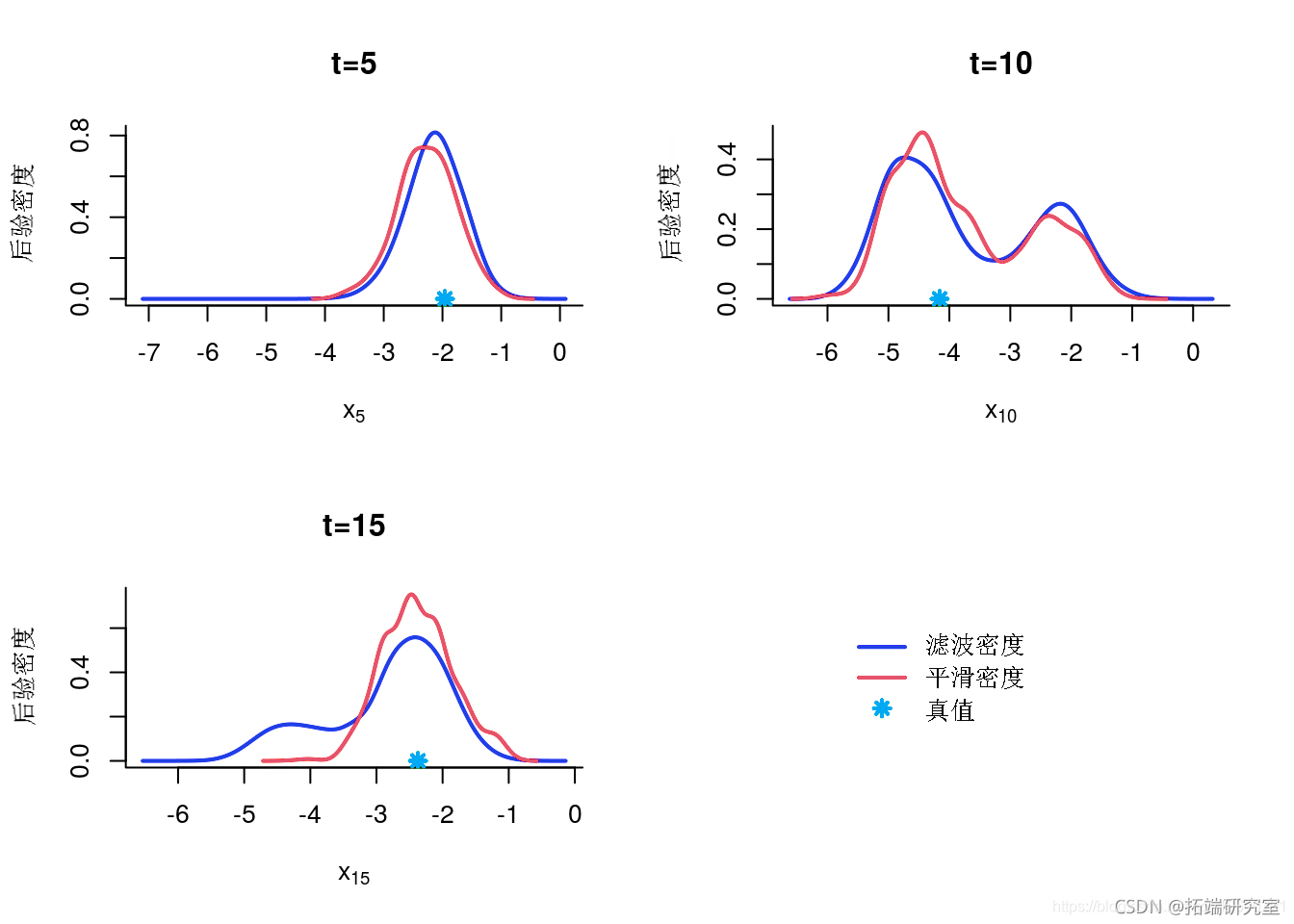
边缘后验
粒子独立 Metropolis-Hastings
运行
mh = mit(mol, vre)![]()
mh(bm, brn, prt) # 预烧迭代
mh(bh, ni, n_at, hn=tn) # 返回样本
一些汇总统计
smay(otmh, pro=c(.025, .975))后验均值和分位数
-
mean
-
quant
-
plot(x, y)
-
-
polo(x, y, border=NA)
-
lis(1:tax, mean)
-
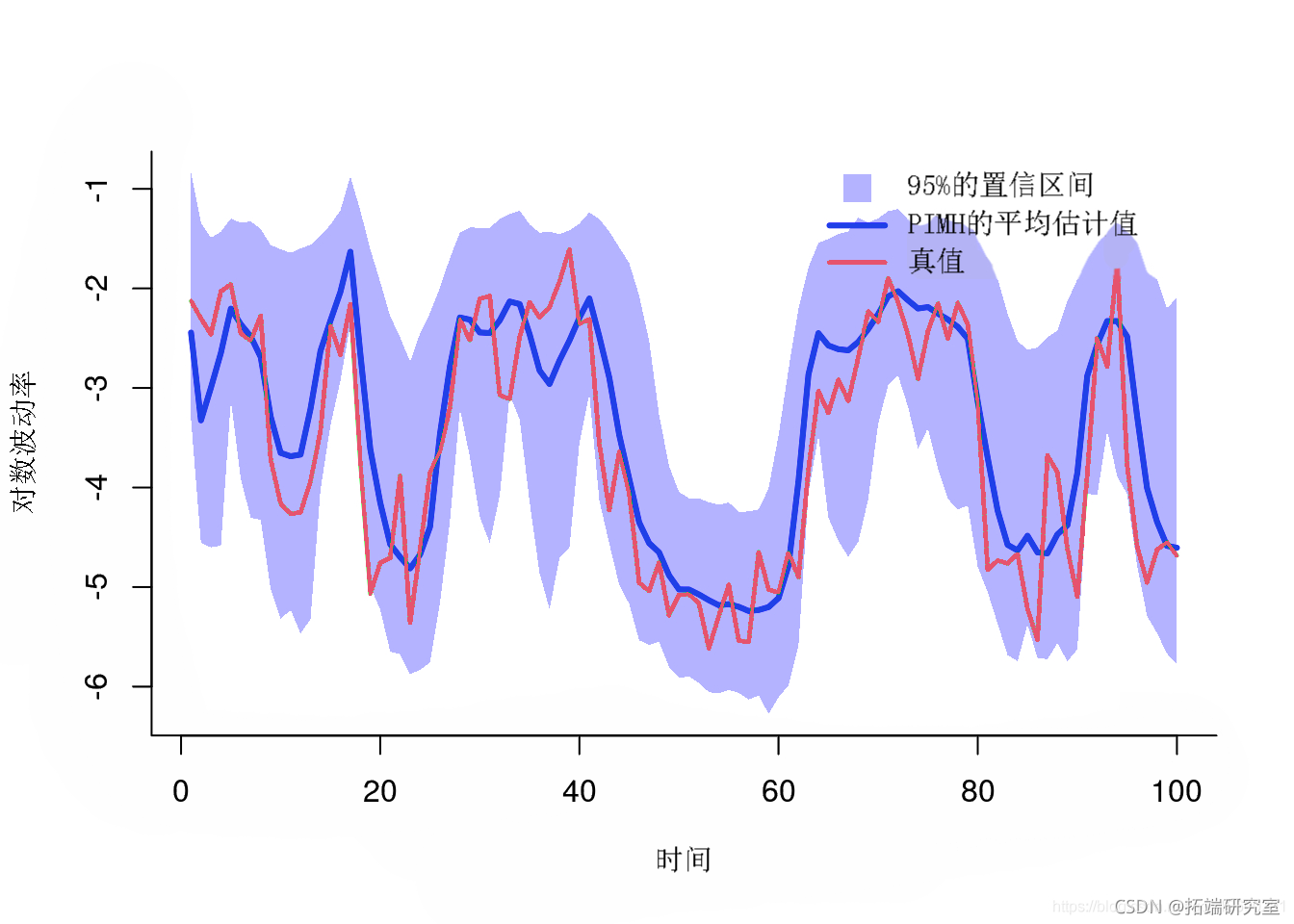
后验均值和分位数
MCMC 样本的踪迹图
-
-
for (k in 1:length {
-
tk = idx[k]
-
plot(out[tk,]
-
)
-
points(0, xtetk)
-
}
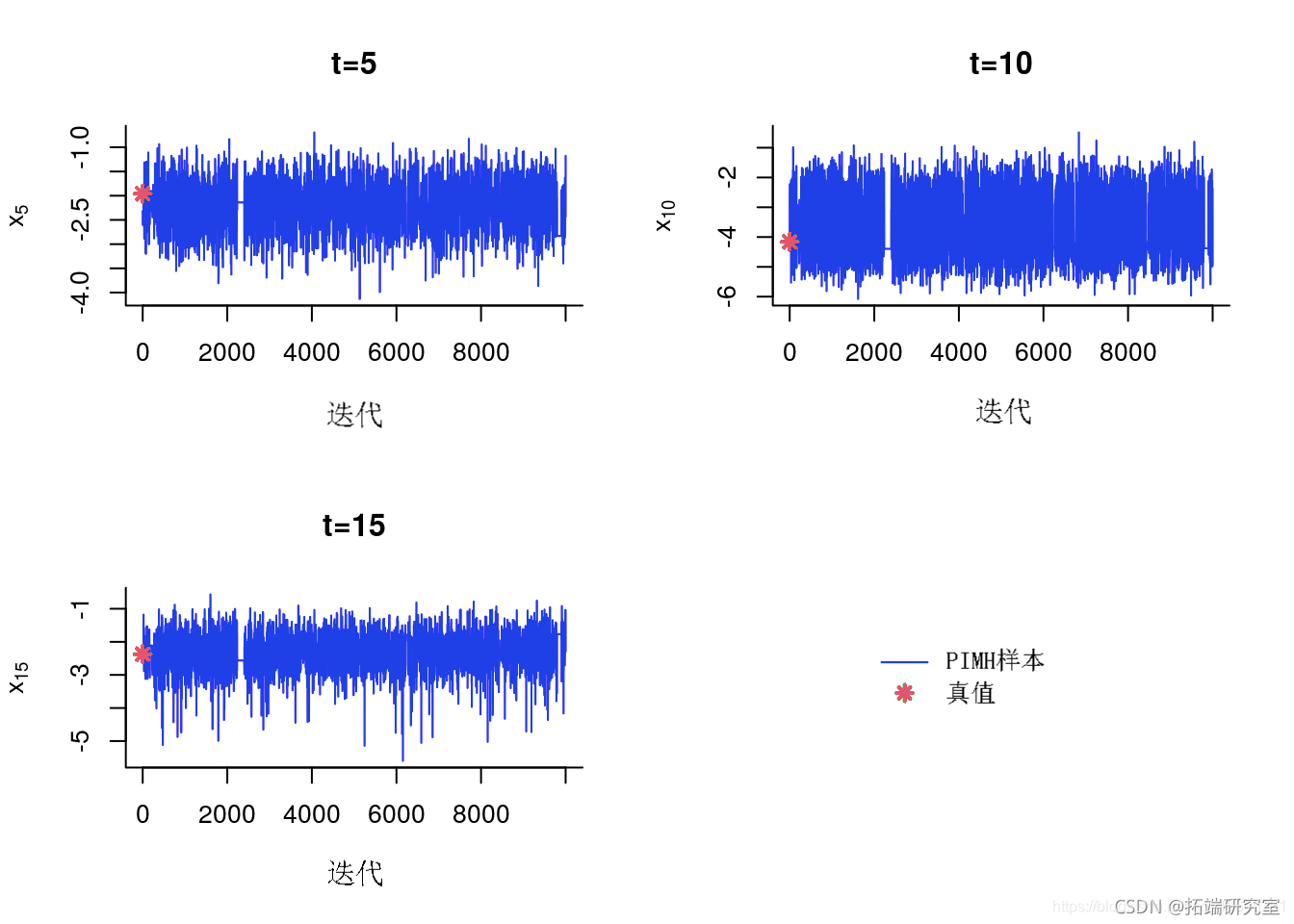
跟踪样本
后验直方图
-
-
for (k in 1:lngh) {
-
k = inex[k]
-
hit(mh$x[t,])
-
poits(true[t])
-
}
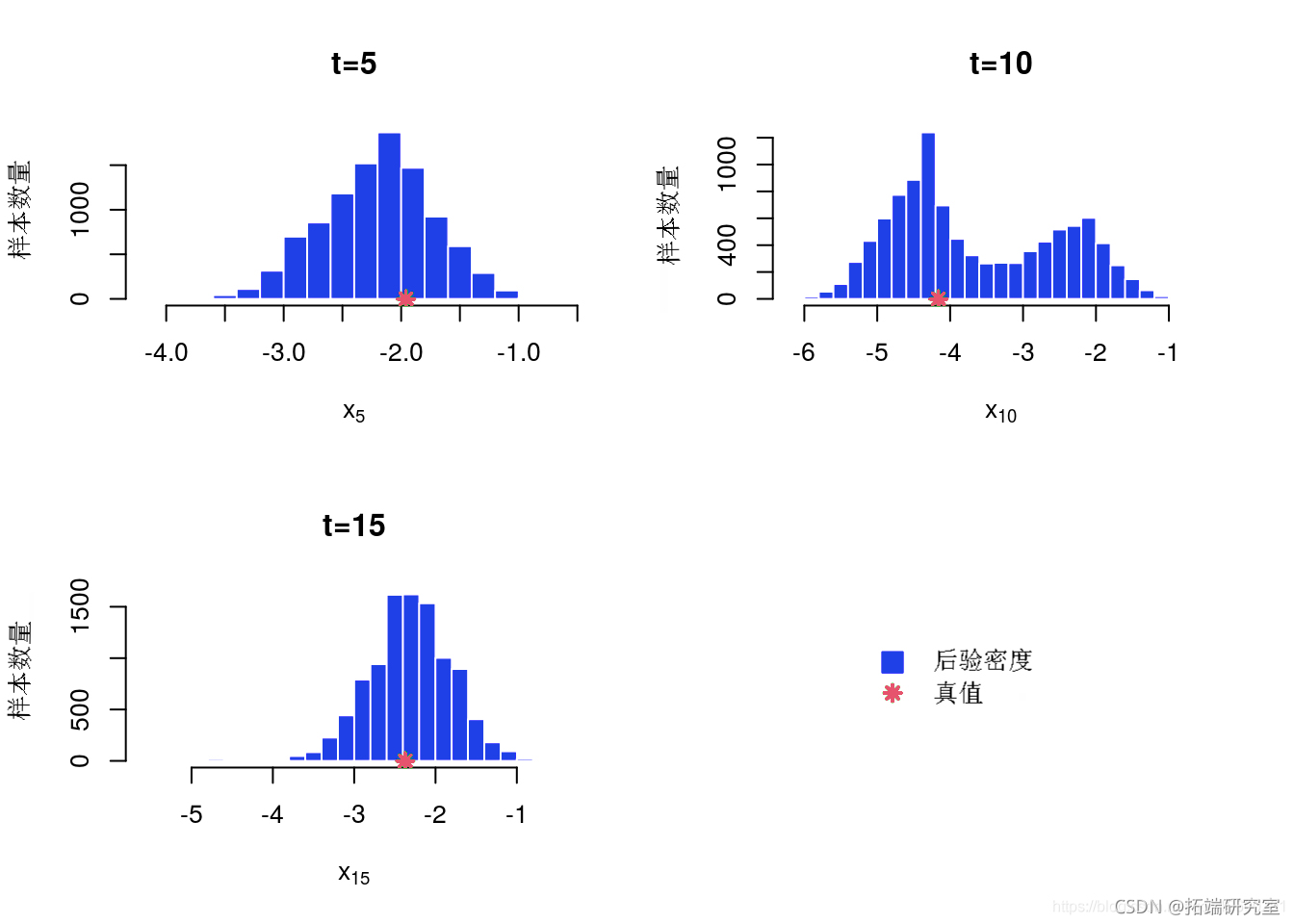
后边缘直方图
后验的核密度估计
-
for (k in 1:lnth(ie)) {
-
idx[k]
-
desty(out[t,])
-
plt(eim)
-
poit(xtu[t])
-
}
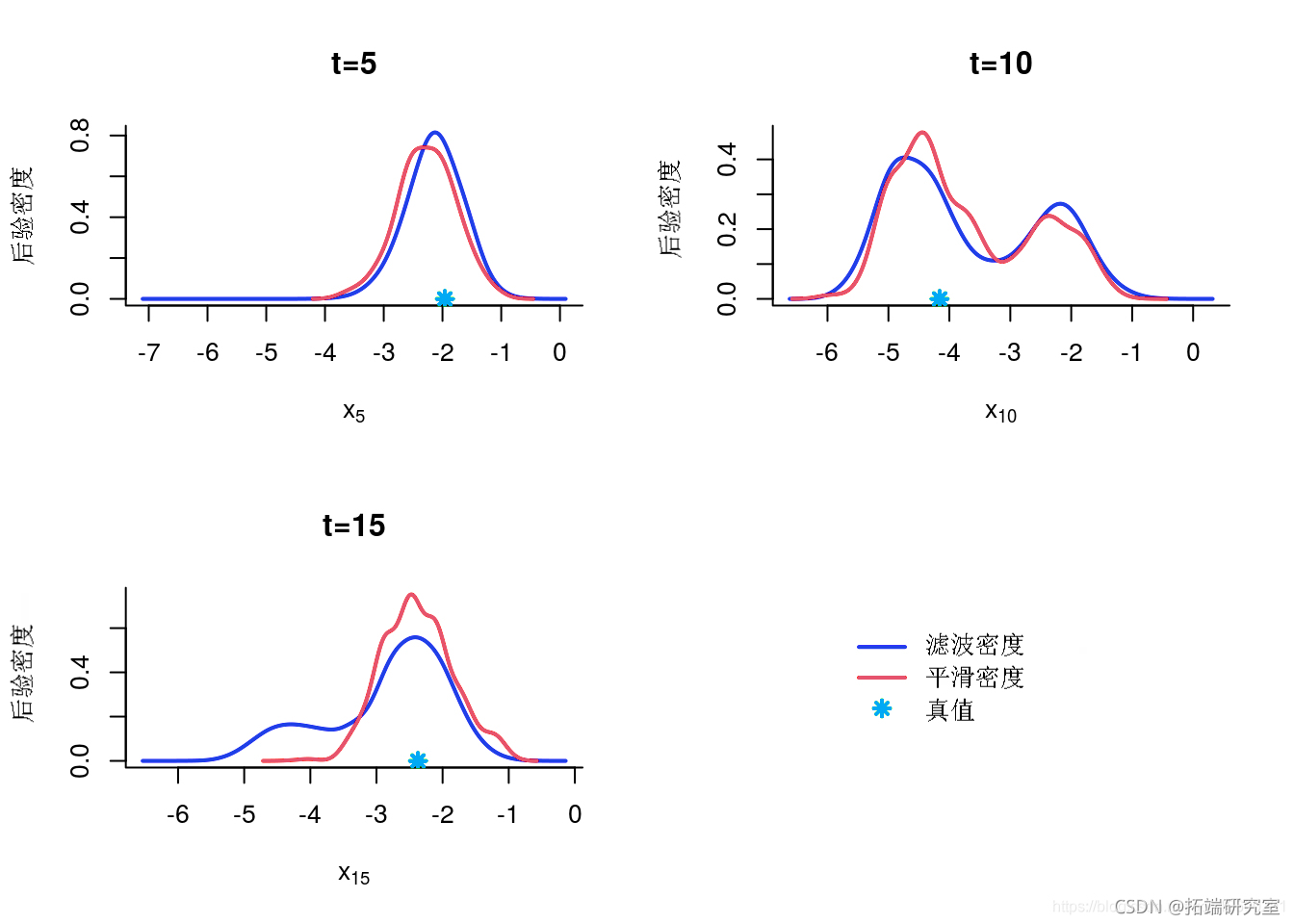
KDE 后验边缘估计
敏感性分析
我们想研究对参数 α 值的敏感性
算法参数
-
nr = 50 # 粒子的数量
-
gd <- seq(-5,2,.2) # 一个成分的数值网格
-
A = rep(grd, tes=leg) # 第一个成分的值
-
B = rep(grd, eah=lnh) # 第二个成分的值
-
vaue = ist('lph' = rid(A, B))
运行灵敏度分析
sny(oel,aaval, ar)
绘制对数边缘似然和惩罚对数边缘似然
-
-
# 通过阈值处理避免标准化问题
-
thr = -40
-
z = atx(mx(thr, utike), row=enth(rd))
-
![]()
-
plot(z, row=grd, col=grd,
-
at=sq(thr))
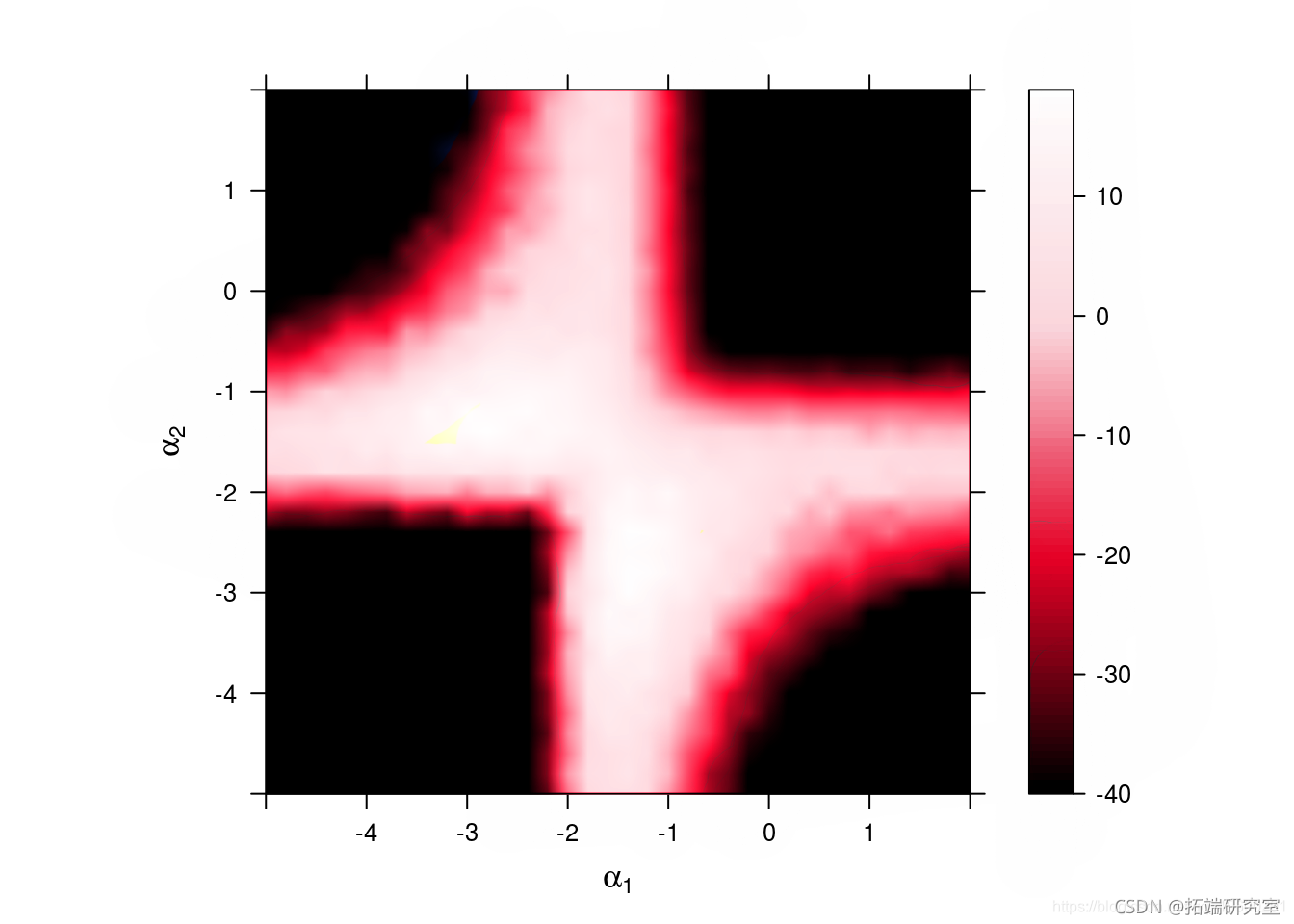
敏感性:对数似然

最受欢迎的见解
1.HAR-RV-J与递归神经网络(RNN)混合模型预测和交易大型股票指数的高频波动率
2.WinBUGS对多元随机波动率模型:贝叶斯估计与模型比较
4.R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测