原文链接:http://tecdat.cn/?p=9024
原文出处:拓端数据部落公众号
拓端tecdat:R语言广义相加模型(GAM)在电力负荷预测中的应用
视频:R语言广义相加模型(GAM)在电力负荷预测中的应用
1导言
这篇文章探讨了为什么使用广义相加模型 是一个不错的选择。为此,我们首先需要看一下线性回归,看看为什么在某些情况下它可能不是最佳选择。
2回归模型
假设我们有一些带有两个属性Y和X的数据。如果它们是线性相关的,则它们可能看起来像这样:
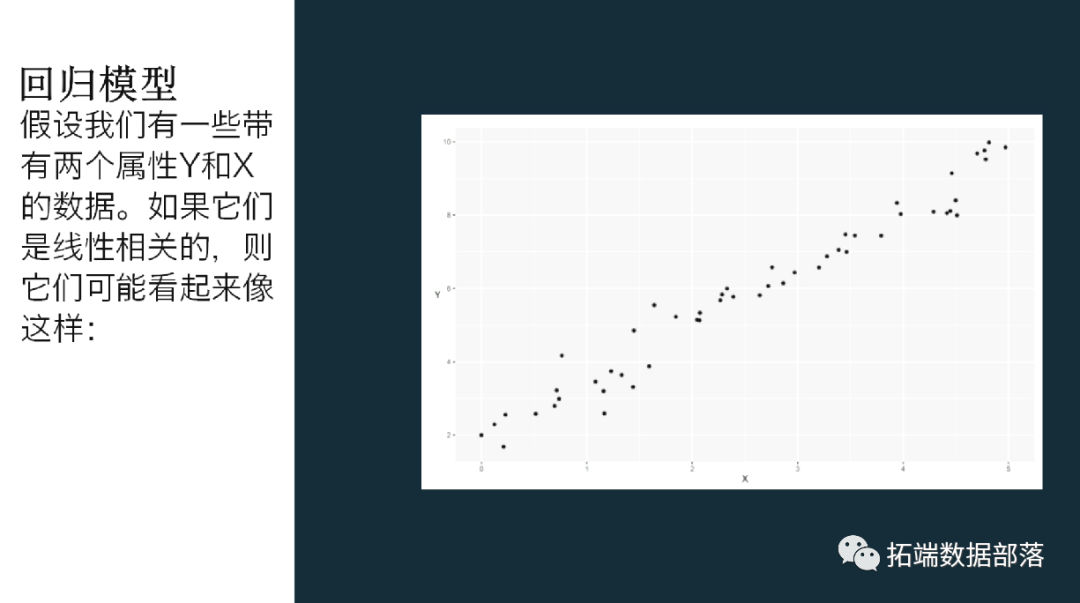
为了检查这种关系,我们可以使用回归模型。线性回归是一种使用X来预测变量Y的方法。将其应用于我们的数据将预测成红线的一组值:
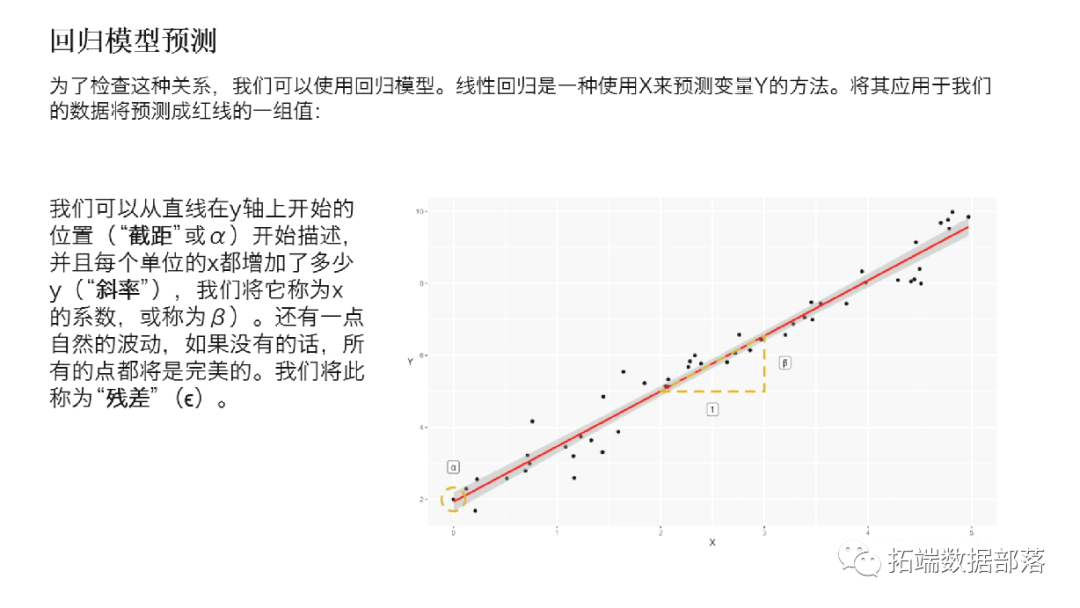
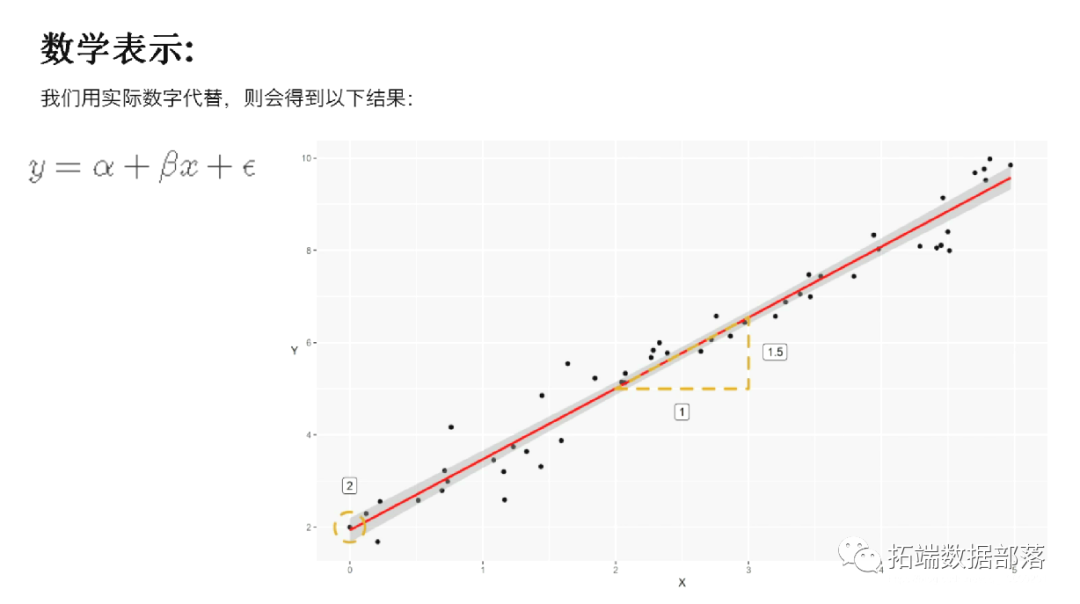
这就是“直线方程式”。根据此等式,我们可以从直线在y轴上开始的位置(“截距”或α)开始描述,并且每个单位的x都增加了多少y(“斜率”),我们将它称为x的系数,或称为β)。还有一点自然的波动,如果没有的话,所有的点都将是完美的。我们将此称为“残差”(ϵ)。

数学上是:
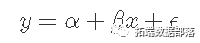
或者,如果我们用实际数字代替,则会得到以下结果:
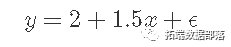
这篇文章通过考虑每个数据点和线之间的差异(“残差)然后最小化这种差异来估算模型。
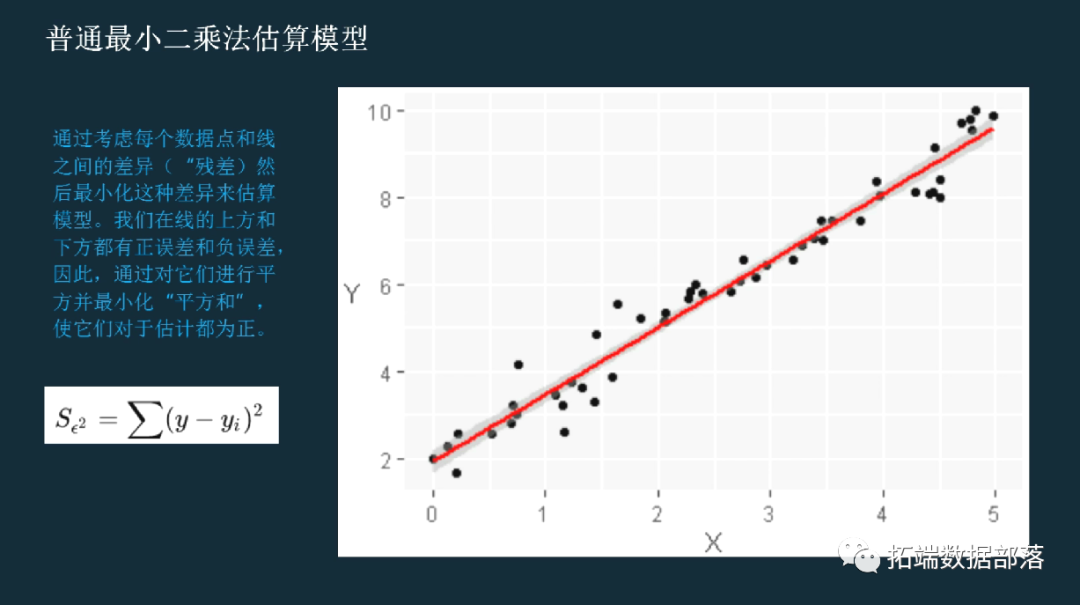
我们在线的上方和下方都有正误差和负误差,因此,通过对它们进行平方并最小化“平方和”,使它们对于估计都为正。这称为“普通最小二乘法”或OLS。
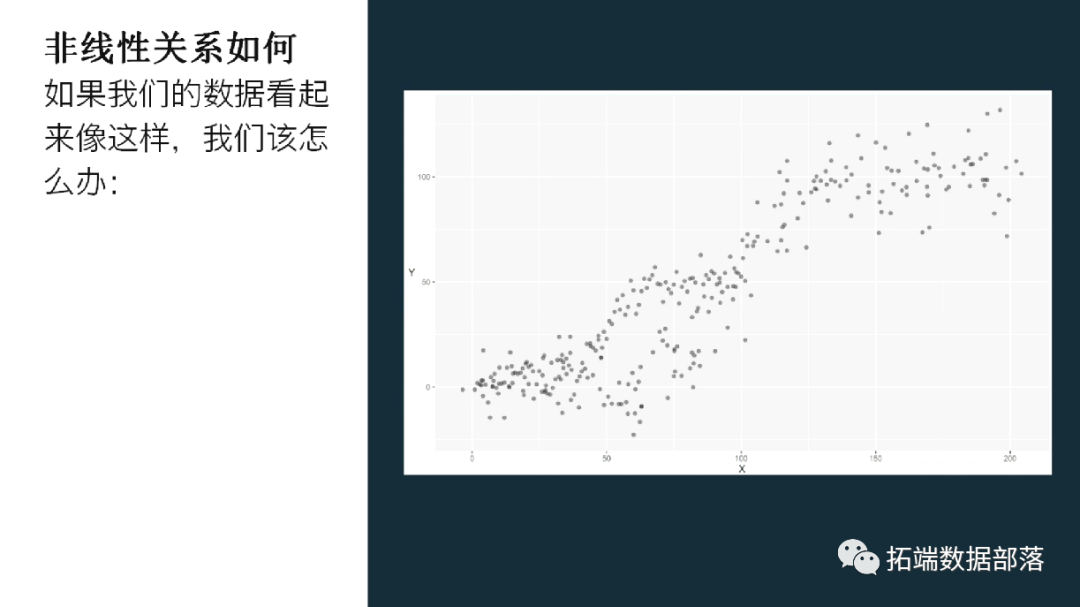
3非线性关系如何?
因此,如果我们的数据看起来像这样,我们该怎么办:
我们刚刚看到的模型的关键假设之一是y和x线性相关。如果我们的y不是正态分布的,则使用广义线性模型 _(Nelder&Wedderburn,1972)_,其中y通过链接函数进行变换,但再次假设f(y)和x线性相关。如果不是这种情况,并且关系在x的范围内变化,则可能不是最合适的。我们在这里有一些选择:
-
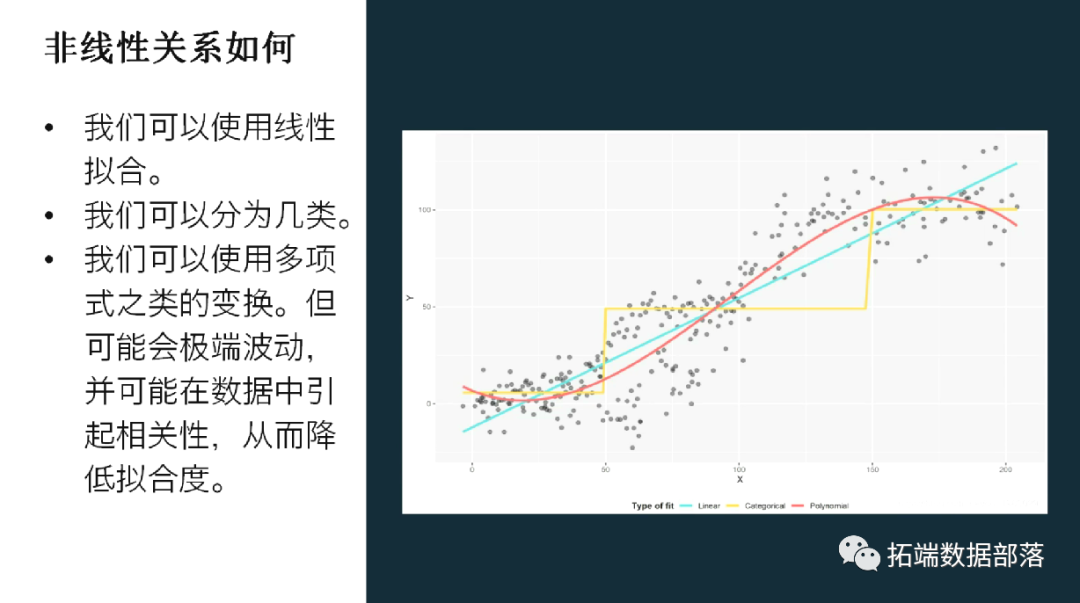
我们可以使用线性拟合,但是如果这样做的话,我们会在数据的某些部分上面或者下面。
-
我们可以分为几类。我在下面的图中使用了三个,这是一个合理的选择。同样,我们可能处于数据某些部分之下或之上,而在类别之间的边界附近似乎是准确的。例如,如果x = 49时,与x = 50相比,y是否有很大不同?
-
我们可以使用多项式之类的变换。下面,我使用三次多项式,因此模型适合:
 。这些的组合使函数可以光滑地近似变化。这是一个很好的选择,但可能会极端波动,并可能在数据中引起相关性,从而降低拟合度。
。这些的组合使函数可以光滑地近似变化。这是一个很好的选择,但可能会极端波动,并可能在数据中引起相关性,从而降低拟合度。
4样条曲线
多项式的进一步细化是拟合“分段”多项式,我们在数据范围内将多项式链在一起以描述形状。“样条线”是分段多项式,以绘图员用来绘制曲线的工具命名。物理样条曲线是一种柔性条,可以弯曲成形,并由砝码固定。在构造数学样条曲线时,我们有多项式函数,二阶导数连续,固定在“结”点上。

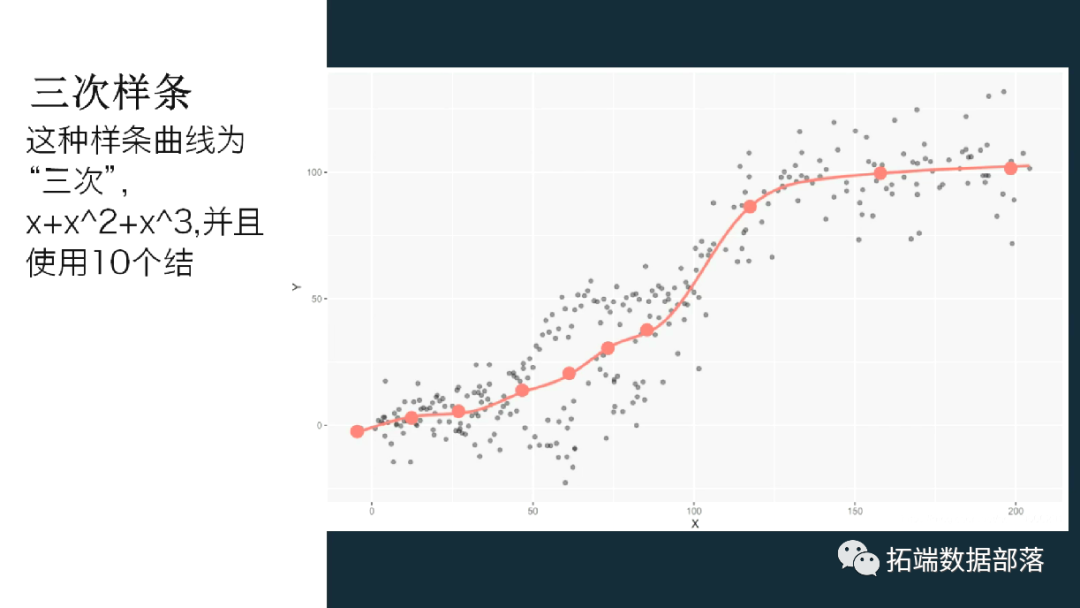
下面是一个ggplot2 对象,该 对象的 geom_smooth 的公式包含ns 函数中的“自然三次样条” 。这种样条曲线为“三次”
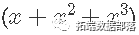
,并且使用10个结
5光滑函数
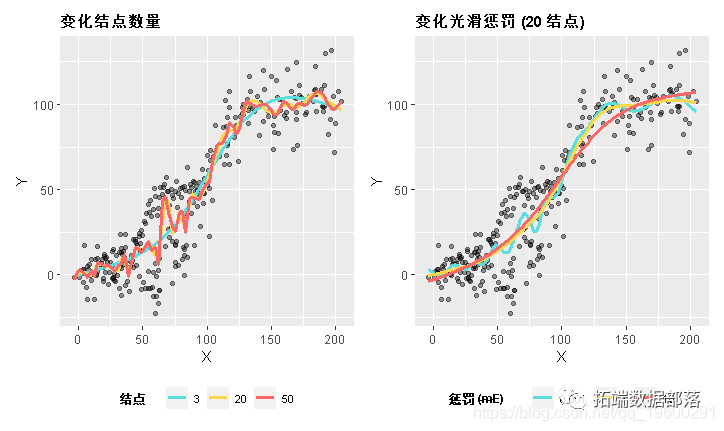
样条曲线可以是光滑的或“摇摆的”,这可以通过改变节点数(k)或使用光滑惩罚γ来控制。如果我们增加结的数目,它将更“摇摆”。这可能会更接近数据,而且误差也会更小,但我们开始“过度拟合”关系,并拟合我们数据中的噪声。当我们结合光滑惩罚时,我们会惩罚模型中的复杂度,这有助于减少过度拟合。
6广义相加模型(GAM)
广义加性模型(GAM)(Hastie,1984)使用光滑函数(如样条曲线)作为回归模型中的预测因子。

这些模型是严格可加的,这意味着我们不能像正常回归那样使用交互项,但是我们可以通过重新参数化作为一个更光滑的模型来实现同样的效果。事实并非如此,但本质上,我们正转向一种模型,如:
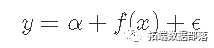
摘自Wood _(2017)_的GAM的更正式示例 是:
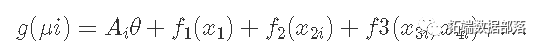
其中:
-
μi≡E(Yi),Y的期望
-
Yi〜EF(μi,ϕi),Yi是一个响应变量,根据均值μi和形状参数ϕ的指数族分布。
-
Ai是任何严格参数化模型分量的模型矩阵的一行,其中θ为对应的参数向量。
-
fi是协变量xk的光滑函数,其中k是每个函数的基础。
如果您要建立回归模型,但怀疑光滑拟合会做得更好,那么GAM是一个不错的选择。它们适合于非线性或有噪声的数据。
7 gam拟合
那么,如何 为上述S型数据建立 GAM模型?

在这里,我将使用三次样条回归 :
gam(Y ~ s(X, bs="cr")上面的设置意味着:
-
s()指定光滑器。还有其他选项,但是s是一个很好的默认选项 -
bs=“cr”告诉它使用三次回归样条('basis')。 -
s函数计算出要使用的默认结数,但是您可以将其更改为k=10,例如10个结。
8模型输出:
查看模型摘要:
-
##
-
## Family: gaussian
-
## Link function: identity
-
-
## Parametric coefficients:
-
## Estimate Std. Error t value Pr(>|t|)
-
## (Intercept) 43.9659 0.8305 52.94 <2e-16 ***
-
## ---
-
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
-
##
-
## Approximate significance of smooth terms:
-
## edf Ref.df F p-value
-
## s(X) 6.087 7.143 296.3 <2e-16 ***
-
## ---
-
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
-
##
-
## R-sq.(adj) = 0.876 Deviance explained = 87.9%
-
## GCV = 211.94 Scale est. = 206.93 n = 300
-
显示了我们截距的模型系数,所有非光滑参数将在此处显示
-
每个光滑项的总体含义如下。
-
这是基于“有效自由度”(edf)的,因为我们使用的样条函数可以扩展为许多参数,但我们也在惩罚它们并减少它们的影响。
9检查模型:
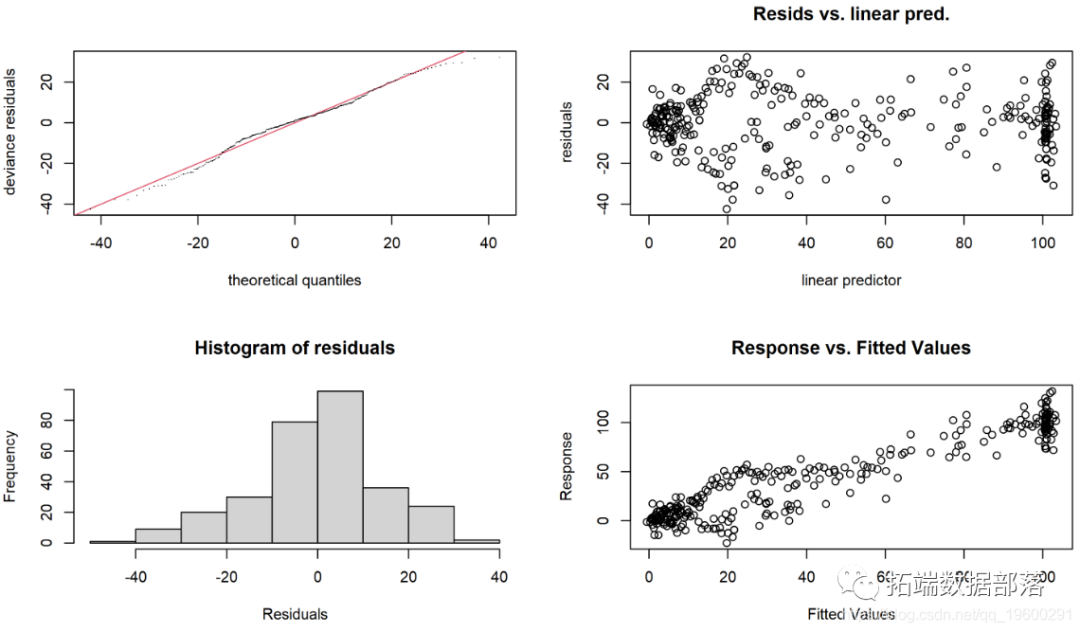
该 gam.check() 函数可用于查看残差图,但它也可以测试光滑器以查看是否有足够的结来描述数据。但是如果p值很低,则需要更多的结。
-
##
-
## Method: GCV Optimizer: magic
-
## Smoothing parameter selection converged after 4 iterations.
-
## The RMS GCV score gradient at convergence was 1.107369e-05 .
-
## The Hessian was positive definite.
-
## Model rank = 10 / 10
-
##
-
## Basis dimension (k) checking results. Low p-value (k-index<1) may
-
## indicate that k is too low, especially if edf is close to k'.
-
##
-
## k' edf k-index p-value
-
## s(X) 9.00 6.09 1.1 0.97
10它比线性模型好吗?
让我们对比具有相同数据的普通线性回归模型:
anova(my\_lm, my\_gam)-
## Analysis of Variance Table
-
##
-
## Model 1: Y ~ X
-
## Model 2: Y ~ s(X, bs = "cr")
-
## Res.Df RSS Df Sum of Sq F Pr(>F)
-
## 1 298.00 88154
-
## 2 292.91 60613 5.0873 27540 26.161 < 2.2e-16 ***
-
## ---
-
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
我们的方差分析函数在这里执行了f检验,我们的GAM模型明显优于线性回归。
11小结
所以,我们看了什么是回归模型,我们是如何解释一个变量y和另一个变量x的。其中一个基本假设是线性关系,但情况并非总是这样。当关系在x的范围内变化时,我们可以使用函数来改变这个形状。一个很好的方法是在“结”点处将光滑曲线链接在一起,我们称之为“样条曲线”
我们可以在常规回归中使用这些样条曲线,但是如果我们在GAM的背景中使用它们,我们同时估计了回归模型以及如何使我们的模型更光滑。
上面的示例显示了基于样条的GAM,其拟合度比线性回归模型好得多。
12用GAM进行建模用电负荷时间序列
我已经准备了一个文件,其中包含四个用电时间序列来进行分析。数据操作将由data.table程序包完成。
将提及的智能电表数据读到data.table。
DT <- as.data.table(read\_feather("ind"))使用GAM回归模型。将工作日的字符转换为整数,并使用recode包中的函数重新编码工作日:1.星期一,…,7星期日。
-
DT[, week_num := as.integer(car::recode(week,
-
"'Monday'='1';'Tuesday'='2';'Wednesday'='3';'Thursday'='4';
-
'Friday'='5';'Saturday'='6';'Sunday'='7'"))]
将信息存储在日期变量中,以简化工作。
-
n_type <- unique(DT[, type])
-
n_date <- unique(DT[, date])
-
n_weekdays <- unique(DT[, week])
-
period <- 48
让我们看一下用电量的一些数据并对其进行分析。
-
data\_r <- DT[(type == n\_type[1] & date %in% n_date[57:70])]
-
-
ggplot(data\_r, aes(date\_time, value)) +
-
geom_line() +
-
theme(panel.border = element_blank(),
-
panel.background = element_blank(),
-
panel.grid.minor = element_line(colour = "grey90"),
-
panel.grid.major = element_line(colour = "grey90"),
-
panel.grid.major.x = element_line(colour = "grey90"),
-
axis.text = element_text(size = 10),
-
axis.title = element_text(size = 12, face = "bold")) +
-
labs(x = "Date", y = "Load (kW)")
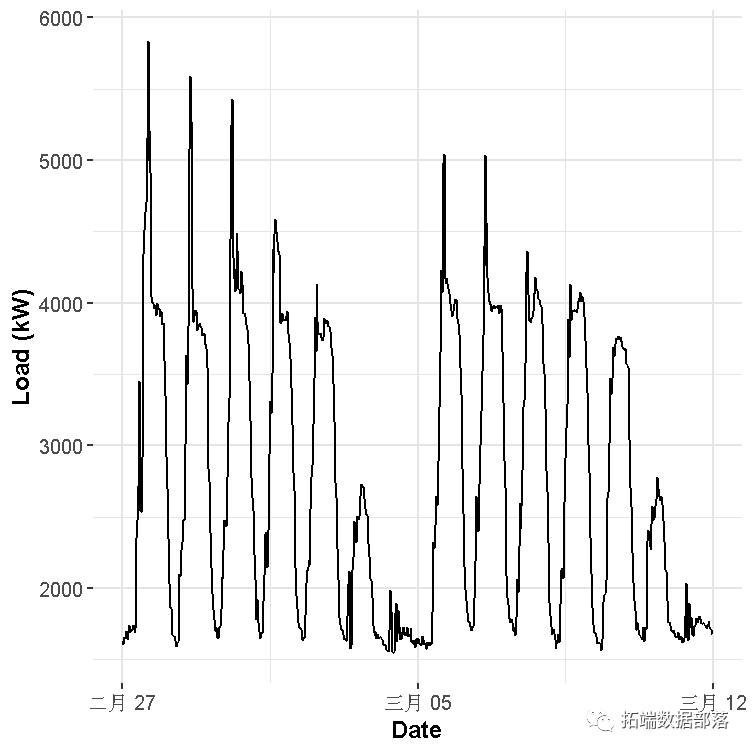
在绘制的时间序列中可以看到两个主要的季节性:每日和每周。我们在一天中有48个测量值,在一周中有7天,因此这将是我们用来对因变量–电力负荷进行建模的自变量。
训练我们的第一个GAM。通过平滑函数s对自变量建模,对于每日季节性,使用三次样条回归,对于每周季节性,使用P样条。
-
gam_1 <- gam(Load ~ s(Daily, bs = "cr", k = period) +
-
s(Weekly, bs = "ps", k = 7),
-
data = matrix_gam,
-
family = gaussian)
首先是可视化。
-
layout(matrix(1:2, nrow = 1))
-
plot(gam_1, shade = TRUE)
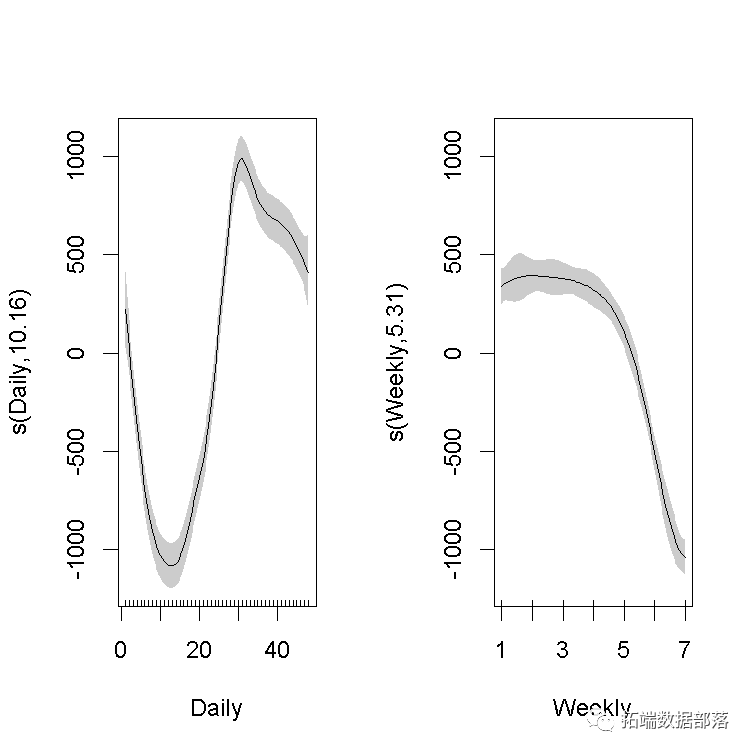
我们在这里可以看到变量对电力负荷的影响。在左图中,白天的负载峰值约为下午3点。在右边的图中,我们可以看到在周末负载量减少了。
让我们使用summary函数对第一个模型进行诊断。
-
##
-
## Family: gaussian
-
## Link function: identity
-
##
-
## Formula:
-
## Load ~ s(Daily, bs = "cr", k = period) + s(Weekly, bs = "ps",
-
## k = 7)
-
##
-
## Parametric coefficients:
-
## Estimate Std. Error t value Pr(>|t|)
-
## (Intercept) 2731.67 18.88 144.7 <2e-16 ***
-
## ---
-
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
-
##
-
## Approximate significance of smooth terms:
-
## edf Ref.df F p-value
-
## s(Daily) 10.159 12.688 119.8 <2e-16 ***
-
## s(Weekly) 5.311 5.758 130.3 <2e-16 ***
-
## ---
-
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
-
##
-
## R-sq.(adj) = 0.772 Deviance explained = 77.7%
-
## GCV = 2.4554e+05 Scale est. = 2.3953e+05 n = 672
EDF:估计的自由度–可以像对给定变量进行平滑处理那样来解释(较高的EDF值表示更复杂的样条曲线)。P值:给定变量对因变量的统计显着性,通过F检验进行检验(越低越好)。调整后的R平方(越高越好)。我们可以看到R-sq.(adj)值有点低。
让我们绘制拟合值:
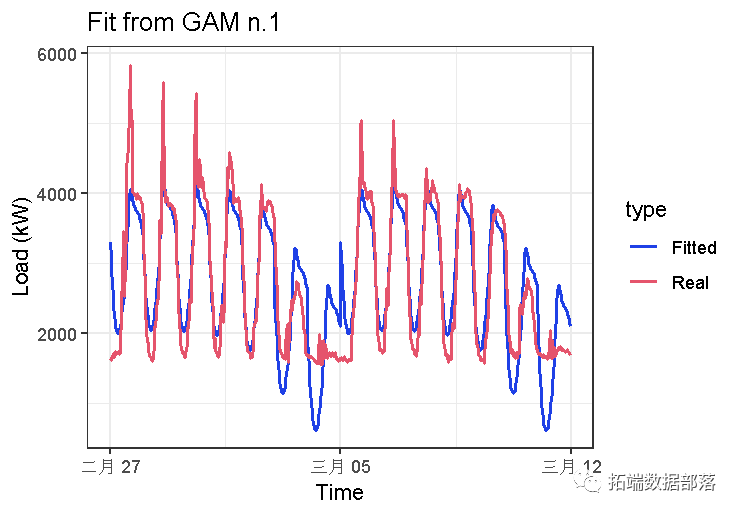
我们需要将两个自变量的交互作用包括到模型中。
第一种交互类型对两个变量都使用了一个平滑函数。
-
gam_2 <- gam(Load ~ s(Daily, Weekly),
-
-
-
summary(gam_2)$r.sq
## [1] 0.9352108R方值表明结果要好得多。
summary(gam_2)$s.table-
## edf Ref.df F p-value
-
## s(Daily,Weekly) 28.7008 28.99423 334.4754 0
似乎也很好,p值为0,这意味着自变量很重要。拟合值图:
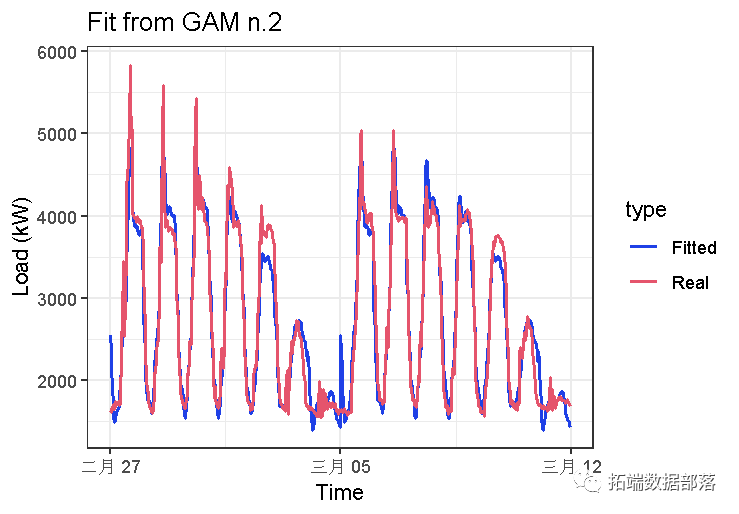
现在,让我们尝试上述变量交互。这可以通过function完成te,也可以定义基本函数。
## [1] 0.9268452与以前的模型相似gam_2。
summary(gam_3)$s.table-
## edf Ref.df F p-value
-
## te(Daily,Weekly) 23.65709 23.98741 354.5856 0
非常相似的结果。让我们看一下拟合值:
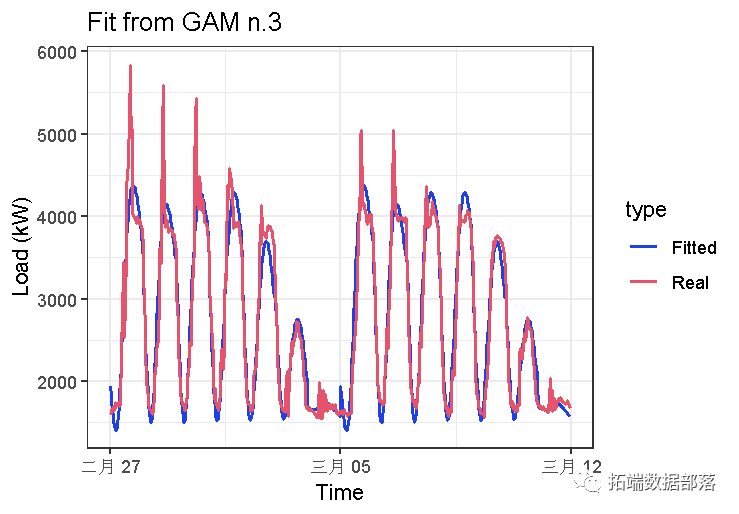
与gam_2模型相比,只有一点点差异,看起来te拟合更好。
## [1] 0.9727604summary(gam_4)$sp.criterion-
## GCV.Cp
-
## 34839.46
summary(gam_4)$s.table-
## edf Ref.df F p-value
-
## te(Daily,Weekly) 119.4117 149.6528 160.2065 0
我们可以在这里看到R方略有上升。
让我们绘制拟合值:
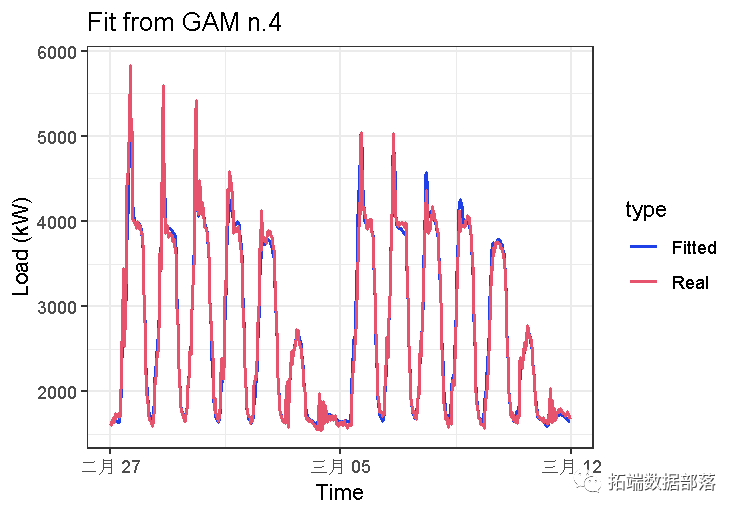
这似乎比gam_3模型好得多。
## [1] 0.965618summary(gam\_4\_fx)$s.table-
## edf Ref.df F p-value
-
## te(Daily,Weekly) 335 335 57.25389 5.289648e-199
我们可以看到R平方比模型gam_4低,这是因为我们过度拟合了模型。证明lambda和EDF的估计工作正常。
因此,让我们在案例(模型)中尝试ti方法。
## [1] 0.9717469summary(gam_5)$sp.criterion-
## GCV.Cp
-
## 35772.35
summary(gam_5)$s.table-
## edf Ref.df F p-value
-
## s(Daily) 22.583649 27.964970 444.19962 0
-
## s(Weekly) 5.914531 5.995934 1014.72482 0
-
## ti(Daily,Weekly) 85.310314 110.828814 41.22288 0
然后使用t2。
## [1] 0.9738273summary(gam_6)$sp.criterion-
## GCV.Cp
-
## 32230.68
summary(gam_6)$s.table-
## edf Ref.df F p-value
-
## t2(Daily,Weekly) 98.12005 120.2345 86.70754 0
我还输出了最后三个模型的GCV得分值,这也是在一组拟合模型中选择最佳模型的良好标准。我们可以看到,对于t2相应模型gam_6,GCV值最低。
在统计中广泛使用的其他模型选择标准是AIC(Akaike信息准则)。让我们看看三个模型:
AIC(gam\_4, gam\_5, gam_6)-
## df AIC
-
## gam_4 121.4117 8912.611
-
## gam_5 115.8085 8932.746
-
## gam_6 100.1200 8868.628
最低值在gam_6模型中。让我们再次查看拟合值。
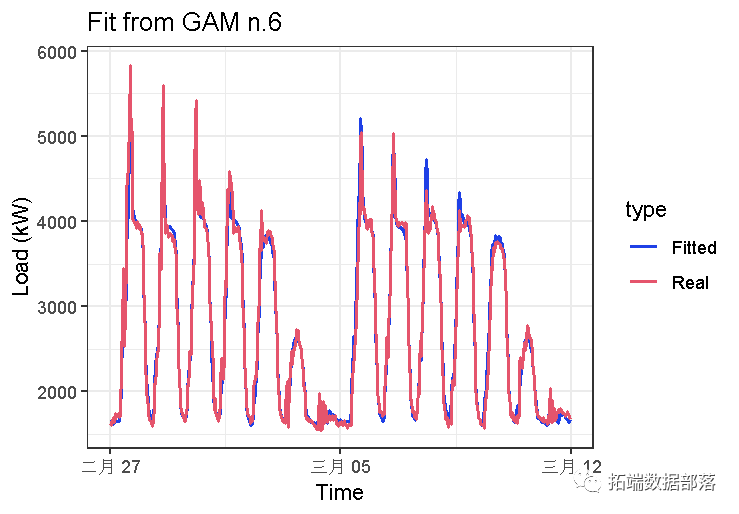
我们可以看到的模型的拟合值gam_4和gam_6非常相似。可以使用软件包的更多可视化和模型诊断功能来比较这两个模型。
第一个是function gam.check,它绘制了四个图:残差的QQ图,线性预测变量与残差,残差的直方图以及拟合值与因变量的关系图。让我们诊断模型gam_4和gam_6。
gam.check(gam_4)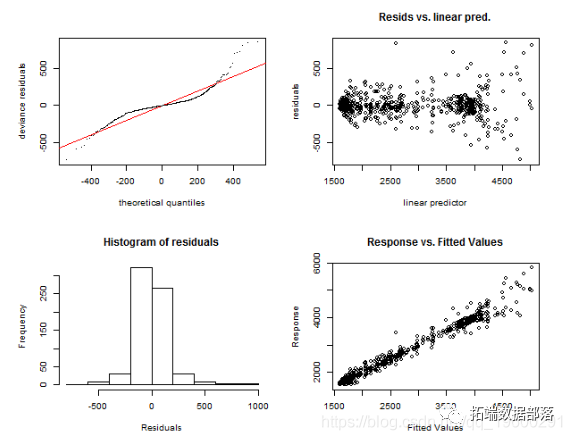
-
##
-
## Method: GCV Optimizer: magic
-
## Smoothing parameter selection converged after 7 iterations.
-
## The RMS GCV score gradiant at convergence was 0.2833304 .
-
## The Hessian was positive definite.
-
## The estimated model rank was 336 (maximum possible: 336)
-
## Model rank = 336 / 336
-
##
-
## Basis dimension (k) checking results. Low p-value (k-index<1) may
-
## indicate that k is too low, especially if edf is close to k'.
-
##
-
## k' edf k-index p-value
-
## te(Daily,Weekly) 335.00 119.41 1.22 1
gam.check(gam_6)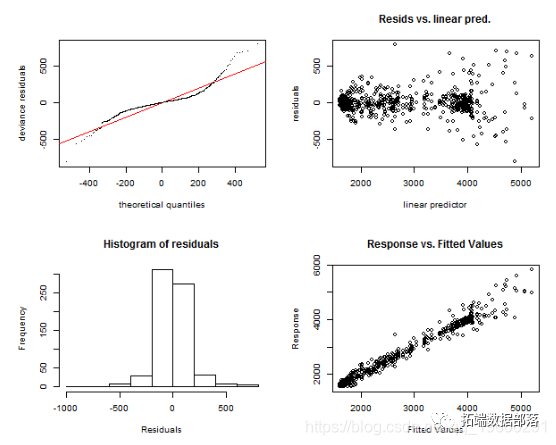
-
##
-
## Method: GCV Optimizer: magic
-
## Smoothing parameter selection converged after 9 iterations.
-
## The RMS GCV score gradiant at convergence was 0.05208856 .
-
## The Hessian was positive definite.
-
## The estimated model rank was 336 (maximum possible: 336)
-
## Model rank = 336 / 336
-
##
-
## Basis dimension (k) checking results. Low p-value (k-index<1) may
-
## indicate that k is too low, especially if edf is close to k'.
-
##
-
## k' edf k-index p-value
-
## t2(Daily,Weekly) 335.00 98.12 1.18 1
我们可以再次看到模型非常相似,只是在直方图中可以看到一些差异。
-
layout(matrix(1:2, nrow = 1))
-
plot(gam_4, rug = FALSE, se = FALSE, n2 = 80, main = "gam n.4 with te()")
-
plot(gam_6, rug = FALSE, se = FALSE, n2 = 80, main = "gam n.6 with t2()")
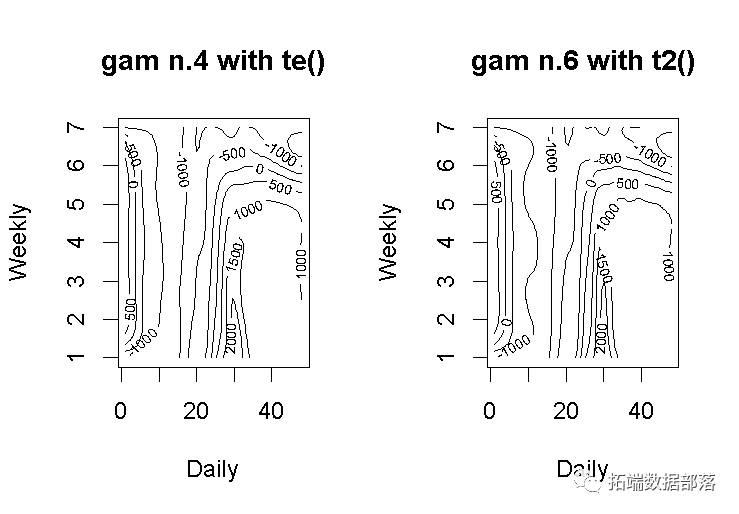
该模型gam_6 有更多的“波浪形”的轮廓。因此,这意味着它对因变量的拟合度更高,而平滑因子更低。
-
vis.gam(gam_6, n.grid = 50, theta = 35, phi = 32, zlab = "",
-
ticktype = "detailed", color = "topo", main = "t2(D, W)")
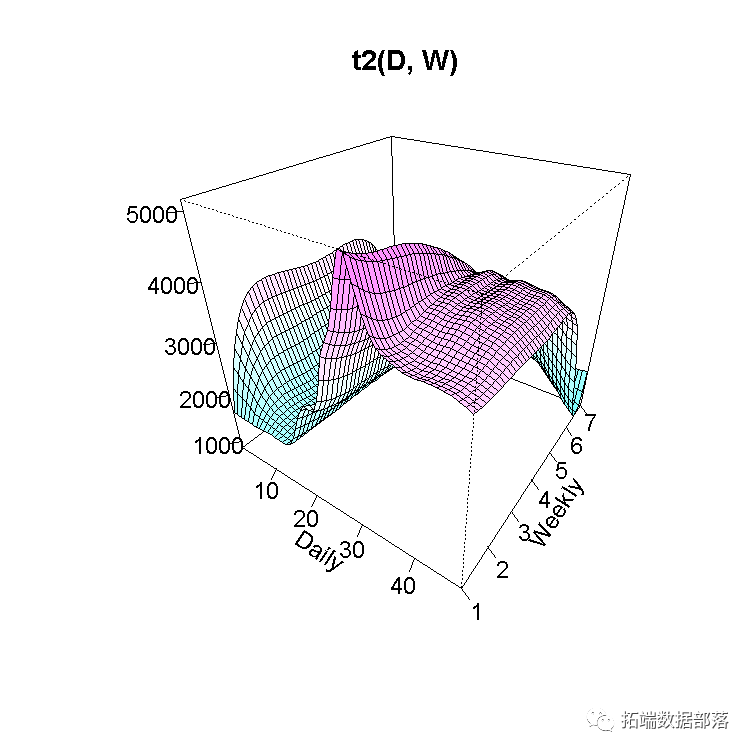
我们可以看到最高峰值是Daily变量的值接近30(下午3点),而Weekly变量的值是1(星期一)。
-
vis.gam(gam_6, main = "t2(D, W)", plot.type = "contour",
-
color = "terrain", contour.col = "black", lwd = 2)
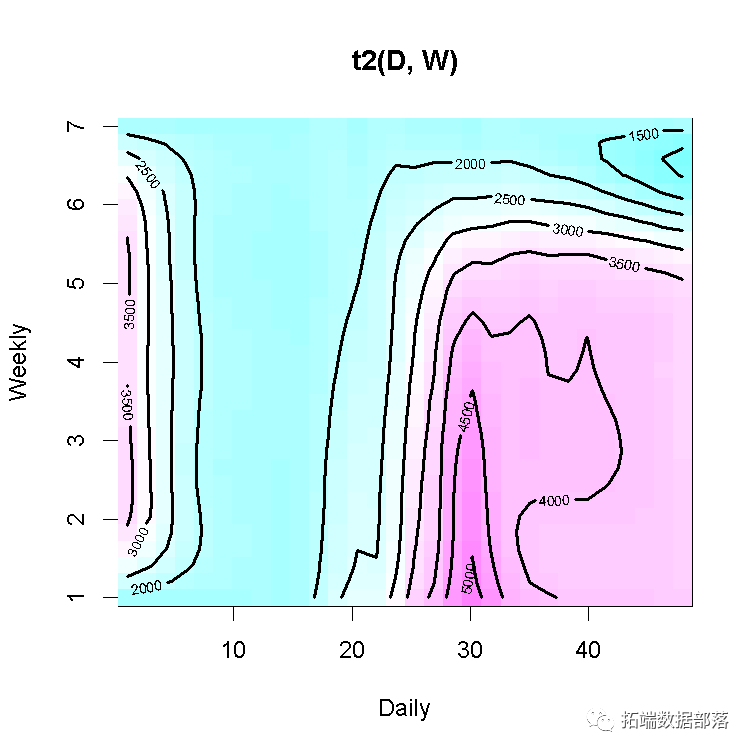
再次可以看到,电力负荷的最高值是星期一的下午3:00,直到星期四都非常相似,然后负荷在周末减少。

最受欢迎的见解
1.在python中使用lstm和pytorch进行时间序列预测
2.python中利用长短期记忆模型lstm进行时间序列预测分析