原文链接:http://tecdat.cn/?p=6763
NASA托管和/或维护了超过32,000个数据集; 这些数据集涵盖了从地球科学到航空航天工程到NASA本身管理的主题。我们可以使用这些数据集的元数据来理解它们之间的联系。
1 NASA如何组织数据
首先,让我们下载JSON文件,并查看元数据中存储的名称。
-
-
metadata <- fromJSON("https://data.nasa.gov/data.json")
-
names(metadata$dataset)
我们在这里看到,我们可以从发布每个数据集的人那里获取信息,以获取他们发布的许可证。
class(metadata$dataset$title)
1.1 整理数据
让我们为标题,描述和关键字设置单独的数据框,保留每个数据集的数据集ID,以便我们可以在后面的分析中将它们连接起来 。
1.2 初步的简单探索
NASA数据集中最常见的单词是什么?
-
nasa_title %>%
-
count(word, sort = TRUE)
最常见的关键字是什么?
-
nasa_keyword %>%
-
group_by(keyword) %>%
-
count(sort = TRUE)
2.1描述和标题词的网络
我们可以使用pairwise_count 来计算每对单词在标题或描述字段中出现的次数。
这些是最常出现在descripton字段中的单词对。
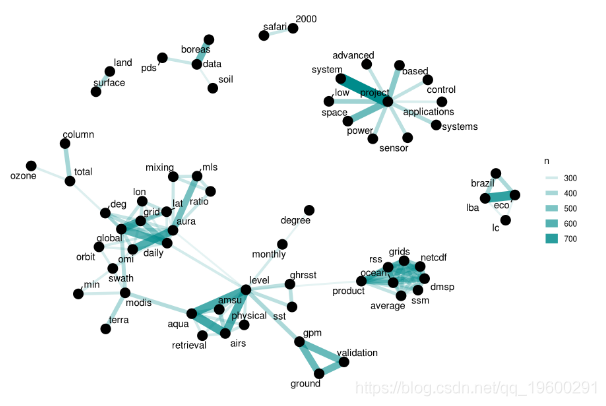
我们在这个标题词网络中看到了一些清晰的聚类; 国家航空航天局数据集标题中的单词大部分被组织成几个词汇系列,这些词汇聚类一起。
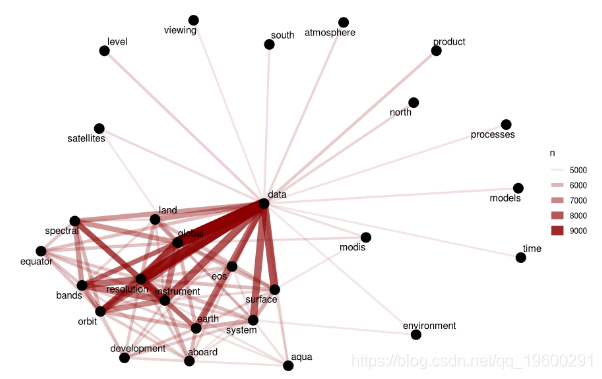
关键词网络
接下来,让我们建立一个 关键字网络,以查看哪些关键字通常在同一数据集中一起出现。
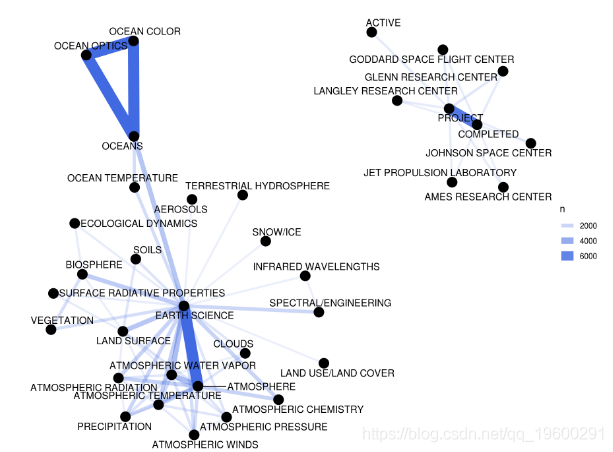
此排序顶部的这些关键字的相关系数等于1; 他们总是一起出现。
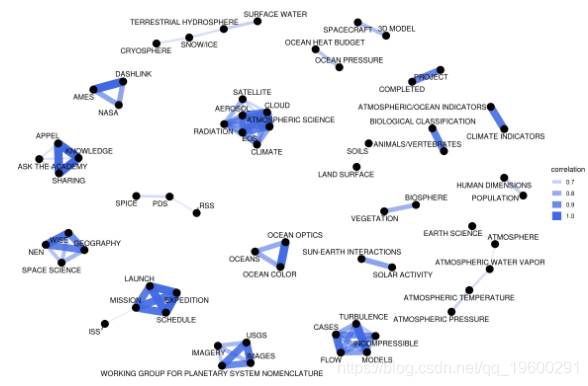
让我们可视化关键字相关性网络,也就是关键字共现网络。
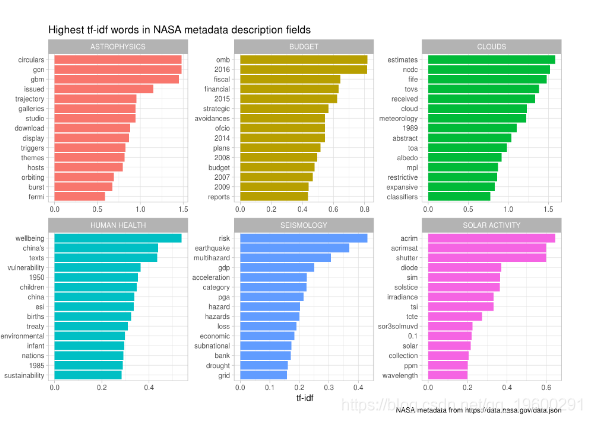
3计算描述字段的tf-idf
网络图向我们展示了描述字段由一些常用词来控制,如“数据”,“全局”; 可以使用tf-idf作为统计数据来查找各个描述字段的特征词。
4主题建模
使用tf-idf作为统计数据已经让我们深入了解NASA描述字段的内容,但让我们尝试另外一种方法来解决NASA描述字段的内容。
每个主题是关于什么的?让我们来看看每个主题的前10个关键词。
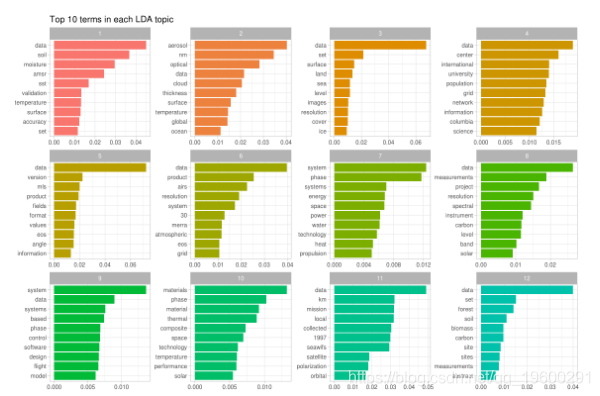
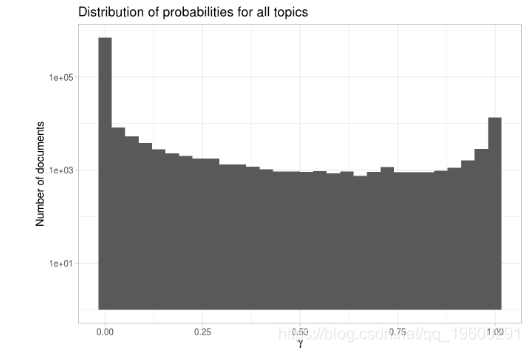
首先注意y轴是以对数刻度绘制的; 否则很难弄清楚图中的细节。
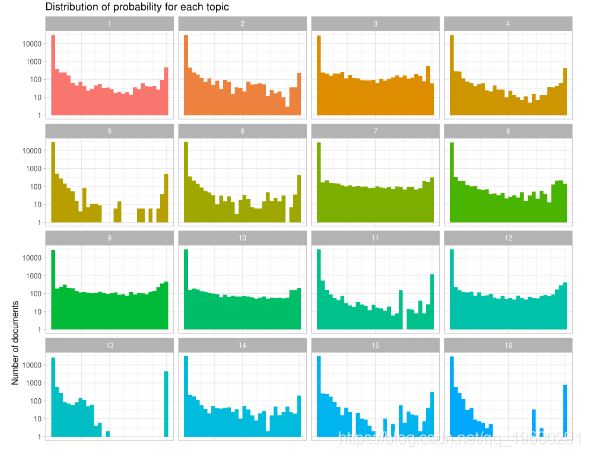
该分布表明文档被很好地区分为属于某个主题。我们还可以看看每个主题中概率的分布情况。

参考文献
3.r语言文本挖掘tf-idf主题建模,情感分析n-gram建模研究
4.python主题建模可视化lda和t-sne交互式可视化
5.r语言文本挖掘nasa数据网络分析,tf-idf和主题建模