
原文链接:http://tecdat.cn/?p=13885
在之前的课堂上,我们已经看到了如何可视化多元回归模型(带有两个连续的解释变量)。在此,目标是使用一些协变量(例如,驾驶员的年龄和汽车的年龄)来预测保险索赔的平均成本(请注意,此处的损失为责任损失)。通过对数链接从(标准)广义线性模型获得的预测。
> reg1=glm(cout~ageconducteur+agevehicule,data=base,family=Gamma(link="log"))可视化预测平均成本的代码如下:首先,我们必须计算特定值的预测,
> pred=function(x,y){
+ predict(reg,newdata=data.frame(ageconducteur=x,
+ agevehicule=y),type="response")然后,我们使用此函数来计算网格上的值,
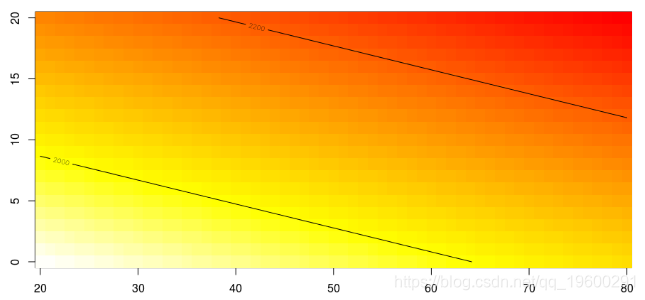

如果我们使用因子,而不是连续变量(这两个变量的简化版本),我们可以使用glm函数
(我们考虑的是笛卡尔乘积,因此将针对乘积,驾驶员年龄和汽车年龄的每个乘积计算值)
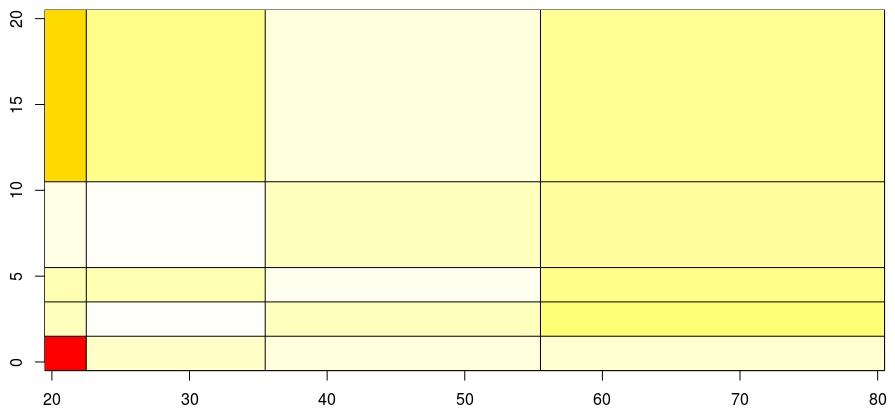
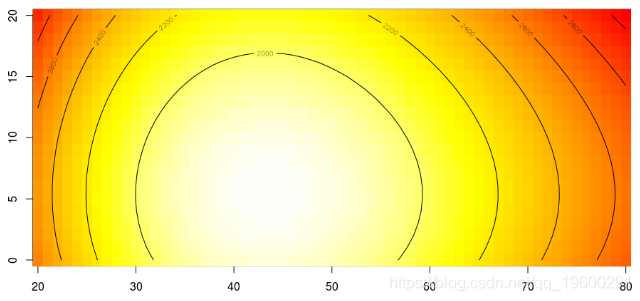
显然,我们在这里缺少了一些东西,让我们使用样条曲线平滑这两个变量,
使用加法平滑函数,我们获得了一个对称图(由于加法特性)
而带有二元样条回归gam
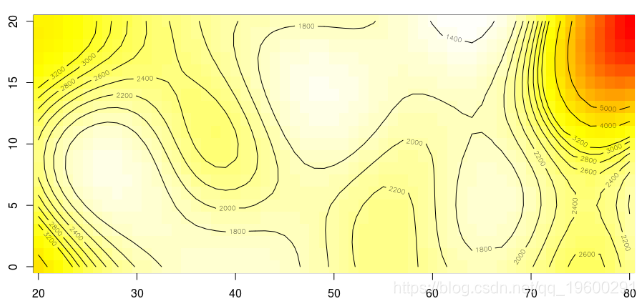
我不能在广义线性模型中使用双变量样条,但是考虑到广义可加模型(现在绝对不是可加模型),它确实可以工作。更准确地说,投资组合的分布是这两个协变量的函数,如下所示
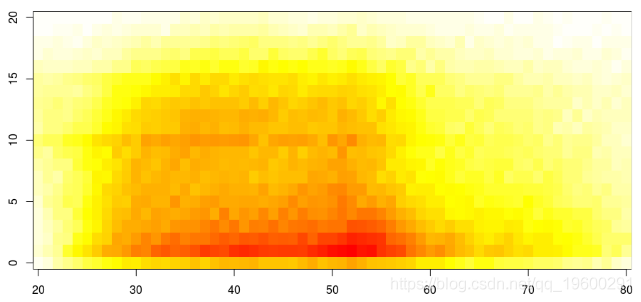
因此,驾驶一辆新车的年轻驾驶员的比例和驾驶一辆非常旧的汽车的老年驾驶员的比例相当小……如果目标是找到合适的位置,则应更仔细地看一下预测,但如果目标是为了使每个人都能获得保险,也许我们应该允许某些司机的价格被低估(尤其是在投资组合中很少见的情况下)。并且应该记住,平均成本对巨额亏损极为敏感。