原文链接:http://tecdat.cn/?p=8613
深度学习无处不在。在本文中,我们将使用Keras进行文本分类。
准备数据集
出于演示目的,我们将使用 20个新闻组 数据集。数据分为20个类别,我们的工作是预测这些类别。如下所示:![]()
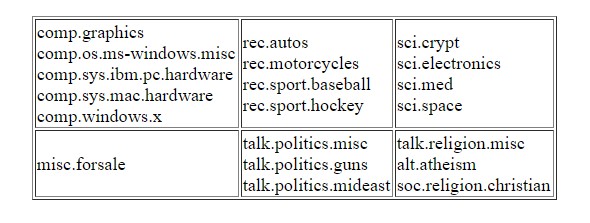
通常,对于深度学习,我们将训练和测试数据分开。
导入所需的软件包
|
1
2
3
4
5
6
7
8
9
|
import pandas as pd
import numpy as np
import pickle
from keras.preprocessing.text import Tokenizer
from keras.models import Sequential
from keras.layers import Activation, Dense, Dropout
from sklearn.preprocessing import LabelBinarizer
import sklearn.datasets as skds
from pathlib import Path
|
将数据从文件加载到Python变量
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# For reproducibility
np.random.seed(1237)
label_index = files_train.target
label_names = files_train.target_names
labelled_files = files_train.filenames
data_tags = ["filename","category","news"]
data_list = []
# Read and add data from file to a list
data = pd.DataFrame.from_records(data_list, columns=data_tags)
|
在我们的情况下,数据无法以CSV格式提供。我们有文本数据文件,文件存放的目录是我们的标签或类别。
我们将使用scikit-learn load_files方法。这种方法可以为我们提供原始数据以及标签和标签索引。
在以上代码的结尾,我们将有一个数据框,其中包含文件名,类别和实际数据。
拆分数据进行训练和测试
|
1
2
3
4
5
6
7
8
9
10
|
# lets take 80% data as training and remaining 20% for test.
train_size = int(len(data) * .8)
train_posts = data['news'][:train_size]
train_tags = data['category'][:train_size]
train_files_names = data['filename'][:train_size]
test_posts = data['news'][train_size:]
test_tags = data['category'][train_size:]
test_files_names = data['filename'][train_size:]
|
标记化并准备词汇
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# 20 news groups
num_labels = 20
vocab_size = 15000
batch_size = 100
# define Tokenizer with Vocab Size
tokenizer = Tokenizer(num_words=vocab_size)
tokenizer.fit_on_texts(train_posts)
|
在对文本进行分类时,我们首先使用Bag Of Words方法对文本进行预处理。
预处理输出标签/类
在将文本转换为数字向量后,我们还需要确保标签以神经网络模型接受的数字格式表示。
建立Keras模型并拟合
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
model = Sequential()
|
它为输入数据的形状以及构成模型的图层类型提供了简单的配置。
这是一些适合度和测试准确性的代码段
|
1
2
3
4
5
6
7
8
9
10
11
12
|
100/8145 [..............................] - ETA: 31s - loss: 1.0746e-04 - acc: 1.0000
200/8145 [..............................] - ETA: 31s - loss: 0.0186 - acc: 0.9950
300/8145 [>.............................] - ETA: 35s - loss: 0.0125 - acc: 0.9967
400/8145 [>.............................] - ETA: 32s - loss: 0.0094 - acc: 0.9975
500/8145 [>.............................] - ETA: 30s - loss: 0.0153 - acc: 0.9960
...
7900/8145 [============================>.] - ETA: 0s - loss: 0.1256 - acc: 0.9854
8000/8145 [============================>.] - ETA: 0s - loss: 0.1261 - acc: 0.9855
8100/8145 [============================>.] - ETA: 0s - loss: 0.1285 - acc: 0.9854
8145/8145 [==============================] - 29s 4ms/step - loss: 0.1293 - acc: 0.9854 - val_loss: 1.0597 - val_acc: 0.8742
Test accuracy: 0.8767123321648251
|
评估模型
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
for i in range(10):
prediction = model.predict(np.array([x_test[i]]))
predicted_label = text_labels[np.argmax(prediction[0])]
print(test_files_names.iloc[i])
print('Actual label:' + test_tags.iloc[i])
print("Predicted label: " + predicted_label)
|
在Fit方法训练了我们的数据集之后,我们将如上所述评估模型。
混淆矩阵
混淆矩阵是可视化模型准确性的最佳方法之一。
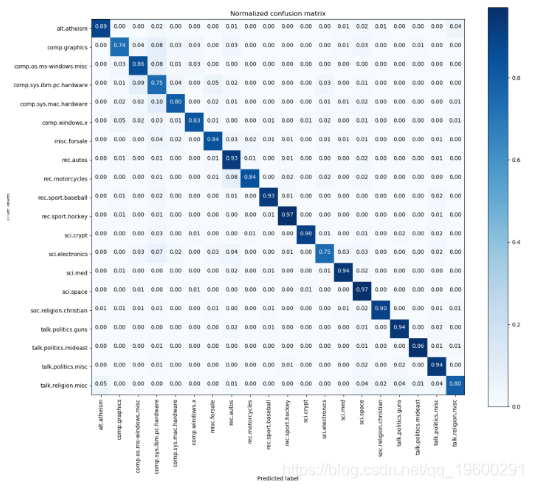
![]()
保存模型
通常,深度学习的用例就像在不同的会话中进行数据训练,而使用训练后的模型进行预测一样。
|
1
2
3
4
5
6
|
# creates a HDF5 file 'my_model.h5'
model.model.save('my_model.h5')
# Save Tokenizer i.e. Vocabulary
with open('tokenizer.pickle', 'wb') as handle:
pickle.dump(tokenizer, handle, protocol=pickle.HIGHEST_PROTOCOL)
|
Keras没有任何实用程序方法可将Tokenizer与模型一起保存。我们必须单独序列化它。
加载Keras模型
预测环境还需要注意标签。
|
1
|
encoder.classes_ #LabelBinarizer
|
预测
如前所述,我们已经预留了一些文件进行实际测试。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
labels = np.array(['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc',
'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x',
'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball',
'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space',
'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast',
'talk.politics.misc', 'talk.religion.misc'])
...
for x_t in x_tokenized:
prediction = model.predict(np.array([x_t]))
predicted_label = labels[np.argmax(prediction[0])]
print("File ->", test_files[i], "Predicted label: " + predicted_label)
i += 1
|
输出量
|
1
2
3
|
File -> C:DL20news-bydate20news-bydate-testcomp.graphics38758 Predicted label: comp.graphics
File -> C:DL20news-bydate20news-bydate-testmisc.forsale76115 Predicted label: misc.forsale
File -> C:DL20news-bydate20news-bydate-testsoc.religion.christian21329 Predicted label: soc.religion.christian
|
我们知道目录名是文件的真实标签,因此上述预测是准确的。
结论
在本文中,我们使用Keras python库构建了一个简单而强大的神经网络。