原文链接:http://tecdat.cn/?p=4146
通过对用电负荷的消费者进行聚类,我们可以提取典型的负荷曲线,提高后续用电量预测的准确性,检测异常或监控整个智能电网(Laurinec等人(2016),Laurinec和Lucká( 2016))。第一个用例通过K-medoids聚类方法提取典型的电力负荷曲线。
有50个长度为672的时间序列(消费者),长度为2周的耗电量的时间序列。这些测量来自智能电表。
维数太高,并且会发生维数的诅咒。因此,我们必须以某种方式降低维度。最好的方法之一是使用时间序列表示,以减少维数,减少噪声并提取时间序列的主要特征。
对于用电的两个季节性时间序列(每日和每周季节性),基于模型的表示方法似乎具有提取典型用电量的最佳能力。
让我们使用一种基于模型的基本表示方法- 平均季节性。在此还有一个非常重要的注意事项,对时间序列进行归一化是对时间序列进行每次聚类或分类之前的必要步骤。我们想要提取典型的消耗曲线,而不是根据消耗量进行聚类。
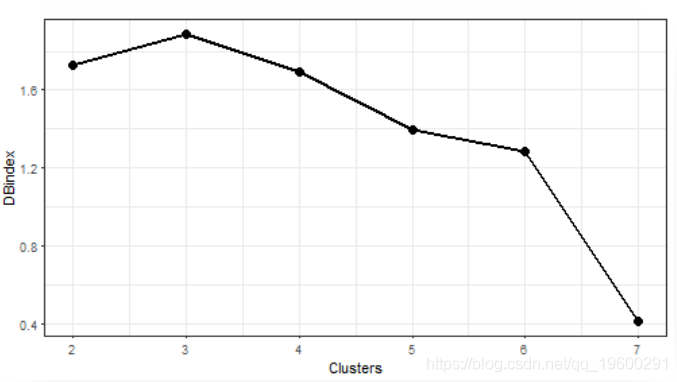
维数上已大大降低。现在,让我们使用K-medoids聚类方法来提取典型的消耗量概况。由于我们不知道要选择合适的簇数,即先验信息,因此必须使用验证指数来确定最佳簇数。我将使用众所周知的Davies-Bouldin指数进行评估。通过Davies-Bouldin指数计算,我们希望找到其最小值。
我将群集数的范围设置为2-7。
让我们绘制评估的结果。


![]()
群集的“最佳”数目是7。
让我们绘制有7个聚类的聚类结果。

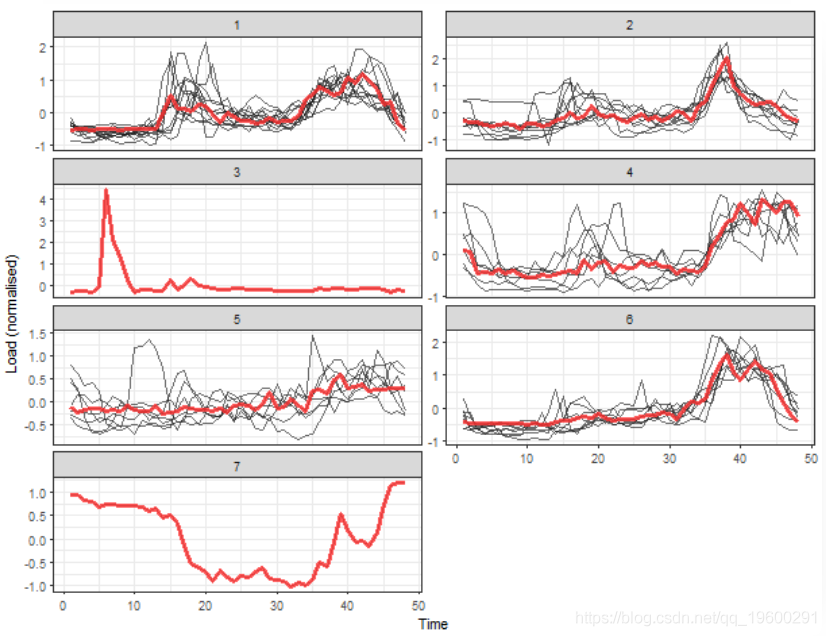
![]()
我们可以看到5个典型的提取轮廓 (簇的中心)。接下来的两个簇可以称为离群值。
现在,让我们尝试一些更复杂的方法来提取季节 GAM回归系数。 我们可以提取每日和每周的季节性回归系数 。
## [1] 50 53由于GAM方法中使用样条曲线 。让我们对数据进行聚类并可视化其结果。
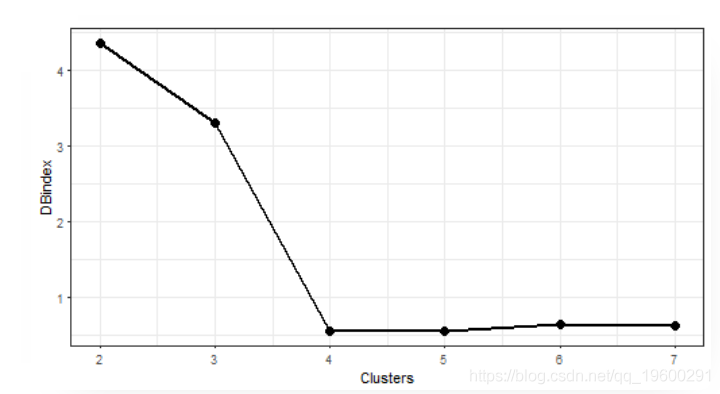
让我们绘制 评估的结果。

![]()
聚类的最佳数目为7。让我们绘制结果。
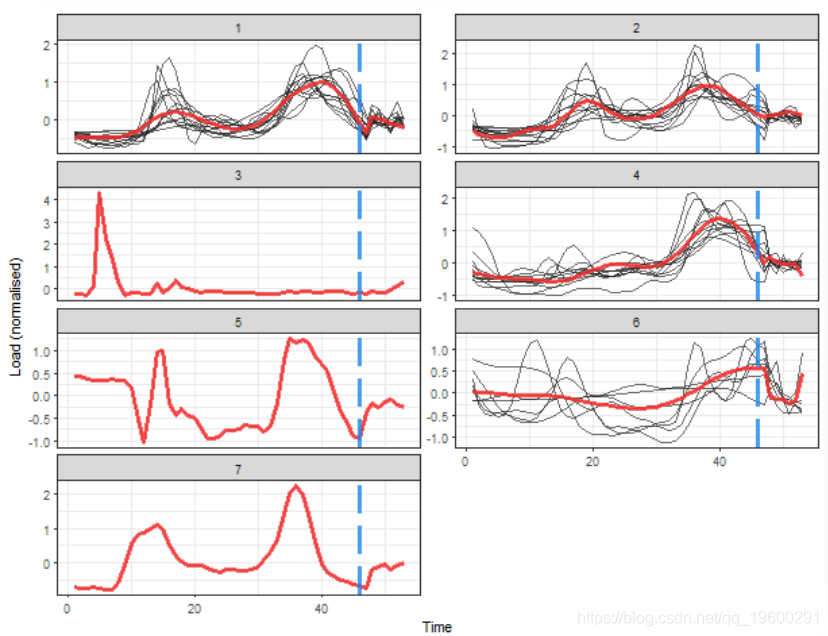
![]()
提取的消费数据比平均季节性数据更平滑。 现在,K 中心提取了4个典型的轮廓,并确定了3个簇。
我展示一些自适应表示的聚类结果,让我们以DFT(离散傅立叶变换)方法为例,并提取前48个DFT系数。

让我们绘制评估的结果。
![]()
我们可以在4个簇中看到漂亮的“肘部”。
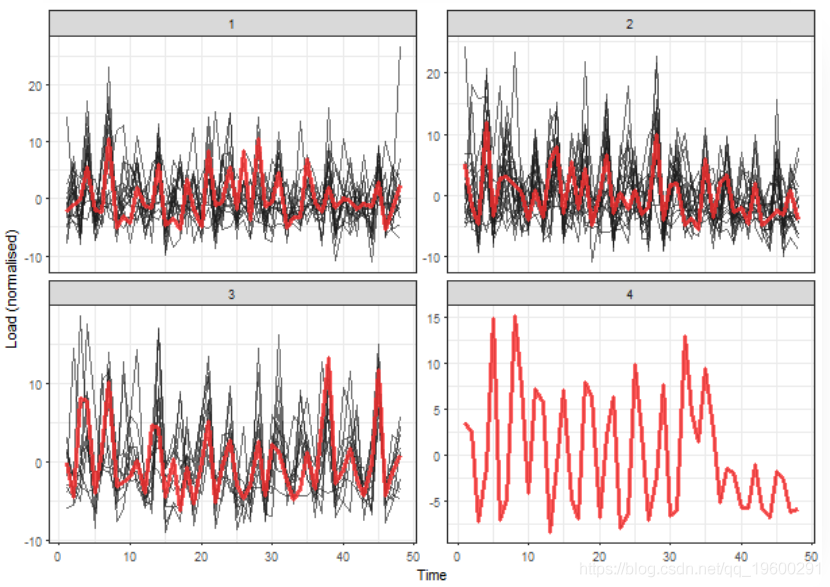
![]()
这些结果难以解释。因此,基于模型的时间序列表示在此用例中非常有效 。
建议在每天的时间序列中使用与FeaClip一起的窗口方法。最大的优点是不需要与FeaClip方法一起进行标准化。
dim(data_feaclip)## [1] 50 112
让我们绘制评估的结果。

![]()
我们可以看到现在出现了2个“肘部”。最大的变化是在2到3之间,因此我将选择3。
![]()
可分离性似乎好于DFT。但是也可以检查具有不同数量集群的其他结果。
结论
在本教程中,我展示了如何使用时间序列表示方法来创建消费者的更多特征文件。然后,用时间序列进行K-medoids聚类,并从创建的聚类中提取典型的消耗曲线。