本周主要介绍了聚类算法和特征降维方法,聚类算法包括K-means的相关概念、优化目标、聚类中心等内容;特征降维包括降维的缘由、算法描述、压缩重建等内容。coursera上面Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml
(一)K-means聚类算法
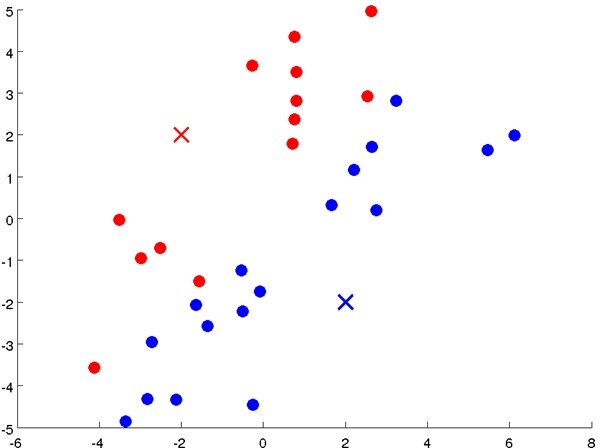
Input data:未标记的数据集,类别数K;
算法流程:
- 首先随机选择K个点,作为初始聚类中心(cluster centroids);
- 计算数据集中每个数据与聚类中心的距离,将其划分到与其最近的中心点那类;
- 重新计算每个类的平均值,并将其作为新的聚类中心;
- 重复步骤2-4直至聚类中心不再变化;
 |
 |
 |
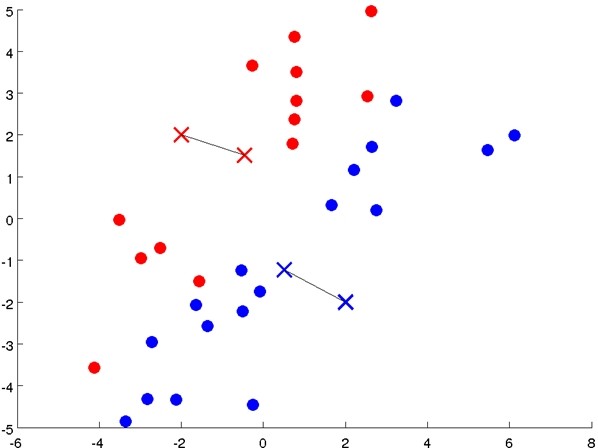
Repeat {
for i = 1 to m
c(i):= index (from 1 to K) of cluster centroid closest to x(i)
for k = 1 to K
μk:= average (mean) of points assigned to cluster k}
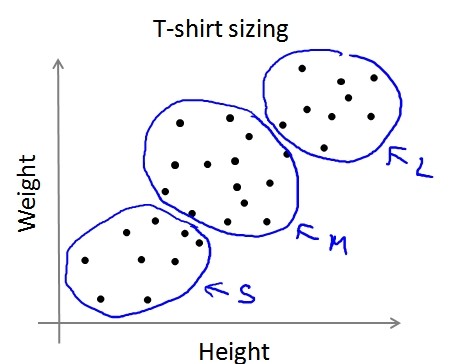
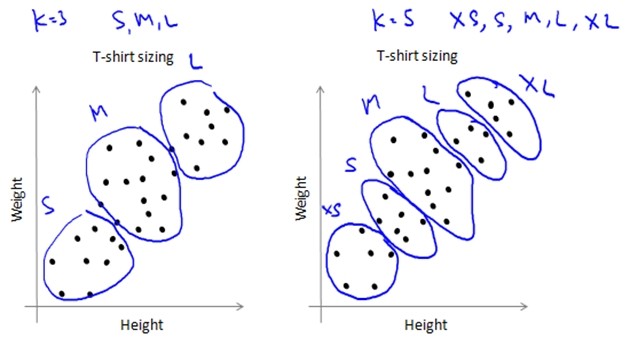
PS:K-means算法也可以用于在没有明显区分的情况下将数据分组,如T-shirt的尺寸问题。
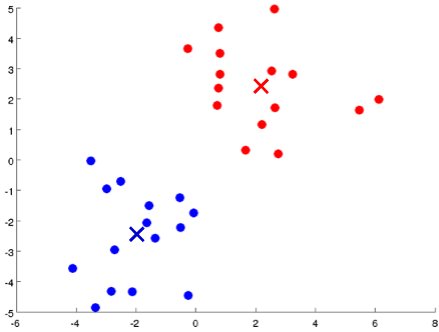
优化目标(Optimization objective)
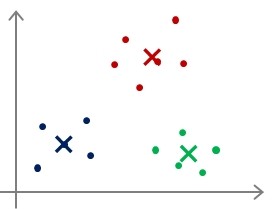
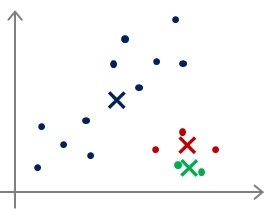
聚类中心初始化(Random initialization)
 |
 |
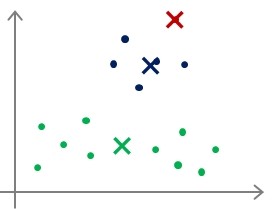 |
- 选择K<m,即聚类中心点的个数要小于所有训练集的数量;
- 随机选择K个训练实例,然后令K个聚类中心分别与这K个训练实例相等;
- 多次运行K-means算法,每次都进行随机初始化;
- 计算代价函数,选择代价最小的结果。
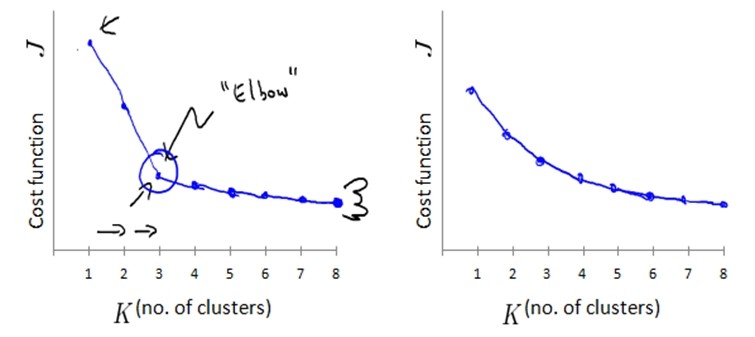
聚类数选择(Choosing the number of clusters)
(二)降维(Dimensionality Reduction)
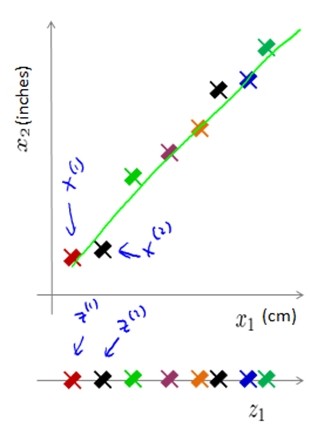
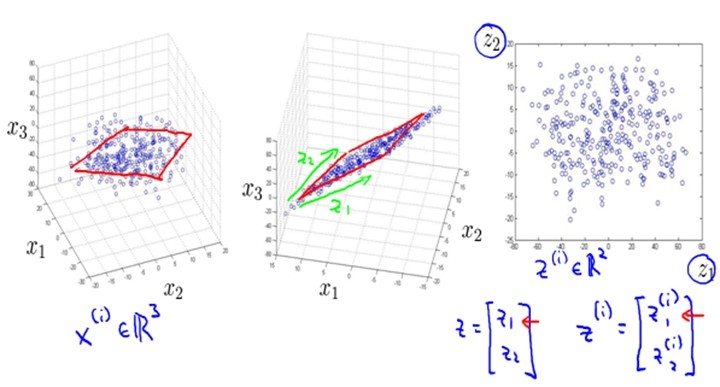
数据可视化(Data Visualization)
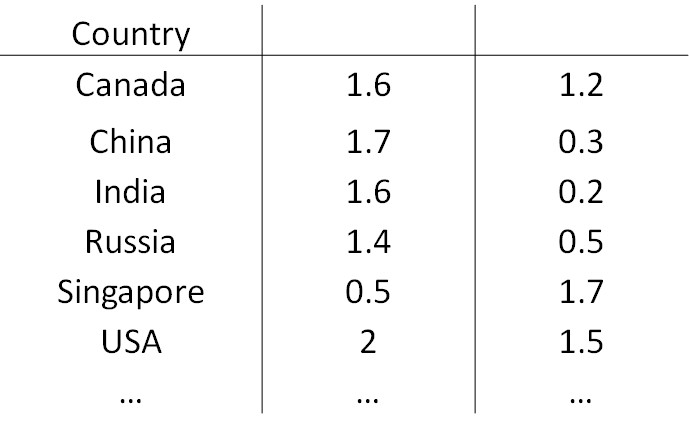 |
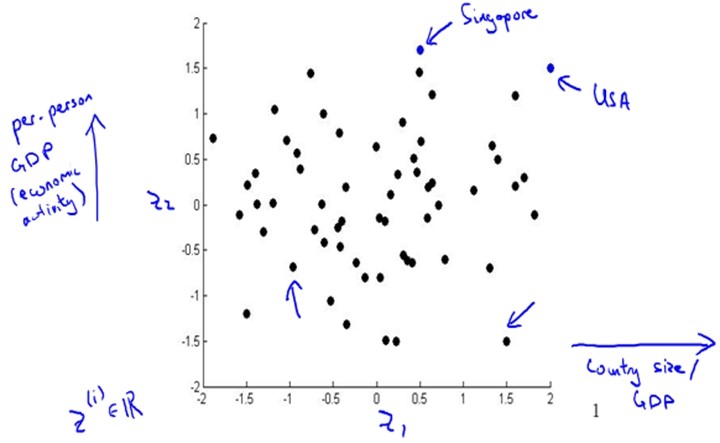 |
PCA(Principal Component Analysis )
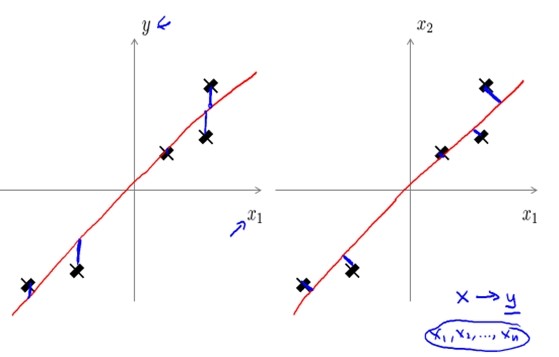
| PCA | Linear Regression |
| 投影误差最小(右图) | 预测误差最小(左图) |
| 无预测任务 | 需预测结果 |
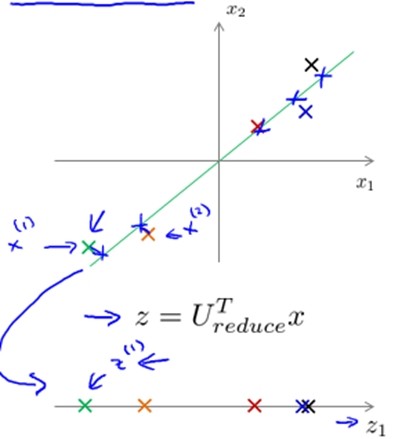
PCA算法
[U,S,V] = svd(Sigma);
其中U是最小投影误差的方向向量构成的矩阵。
Ureduce = U(:,1:k);
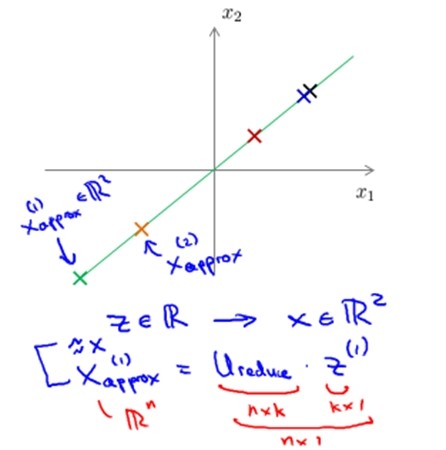
z = UTreduce *x;
压缩重建& k的选择
1. 压缩重建:
- 通过z = UTreduce *x计算特征向量z;其中x是n*1维,所以z是k*1维。
- 通过xapprox = UTreduce * z来近似得到原来的特征向量x;其中z是k*1。所以xapprox 是n*1维。
 |
 |
从上面的分析中可以看出,我们希望在误差尽量小的情况下k值尽量小,那么怎样选择k呢?
2. 方法一:
- 在k = 1时,使用PCA算法;
- 计算Ureduce,z(1),z(2),...,z(m),x(1)approx ,...,x(m)approx
- 检验是否?
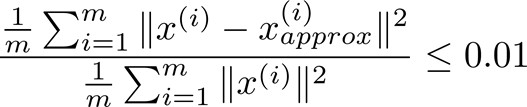 若否,则继续尝试k=2,k=3,.......
若否,则继续尝试k=2,k=3,.......
3. 方法二:
在Octave中使用svd函数时,[U,S,V] = svd(Sigma);其中的S是n*n的矩阵,只有对角线上有值,如下所示:
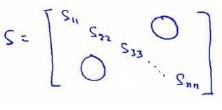
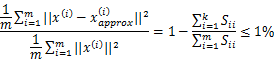 ≡
≡ ![]()
使用PCA的优势及应用
假如我们的输入特征向量是10000维,在使用PCA后可以降至1000维,这样可以加速训练过程,并减少内存。
PS:对于测试集和交叉验证集,同样可以使用训练集得到的Ureduce.由于我们将特征空间由n维减少到了k维,有人会认为这样做会避免过拟合,这样做也许有效,但不是很好的避免过拟合的方法。若要避免过拟合,还是应尝试正则化的方法。
HOMEWORK
好了,既然看完了视频课程,就来做一下作业吧,下面是Clustering & Dimensionality Reduction部分作业的核心代码:
1. findClosestCentroids
m = size(X,1);
dis_vec = zeros(K,1);
for i = 1:m
for j = 1:K
dis_vec(j) = sum((X(i,:)-centroids(j,:)).^2);
end
[v,k] = min(dis_vec);
idx(i) = k;
end
2. computeCentroids
1 tp_sum = zeros(K, n); 2 tp_num = zeros(K, 1); 3 for i = 1:m 4 cy = idx(i); 5 tp_sum(cy,:) = tp_sum(cy,:) + X(i,:); 6 tp_num(cy) += 1; 7 end 8 for j = 1:K 9 centroids(j,:) = tp_sum(j,:)/tp_num(j); 10 end
3. pca.m
sigma = (1/m)*X'*X; [U,S,V] = svd(sigma);
4. projectData.m
Z = X*U(:,1:K);
5. recoverData.m
X_rec = Z* U(:,1:K)';