1、位图
位图是空间利用率极高的数据结构,能够使用很少的存储空间来存储更多的数据。
位图只标记数据的状态,用0和1来表示,1表示存在,0表示不存在
在java中,一个int有4个字节的长度,占据32个bit,只能存储一个数字,而在位图中可以标记32条数据。
例如
5在位图的存储形式:从右向左数5位,存储的是二进制数据,101
0000 0000 0000 0000 0000 0000 0010 1000
9的存储形式:1001
0000 0000 0000 0000 0000 0001 0010 0000
当我们去判断这个值是否存在的时候,判断这个位置的标记为0还是为1即可。为1表示当前数据可能存在,而为0则表示当前数据不存在。
2、布隆过滤器
布隆过滤器是基于位图实现,布隆过滤器增加了对数据的哈希算法的实现,可以多次hash来减少误判。
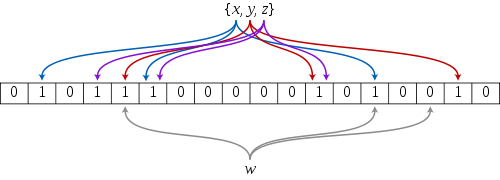
例如x值经过三次hash,分别落在不同的标记位上,当我们需要判断当前值是否存在,就需要判断三次hash后的标记为是否都为1
有一个为0则表示不存在。
3、应用场景
场景:一般请求数据时,会先去访问redis,如果不存在,就再去查询数据库。
在redis的缓存击穿的问题中,大量的请求去访问一个redis中不存在的key,会导致大量的数据请求都去访问数据库
导致数据库崩溃。这时候我们就可以使用布隆过滤器在访问redis前调用。
实例:这里使用guava的布隆过滤器,hutool,redision都提供了布隆过滤器。
初始化布隆过滤器数据:
/** * @description: 布隆过滤器初始化数据 **/ @Component @Slf4j public class BloomApplicationRunner implements ApplicationRunner { @Override public void run(ApplicationArguments args) throws Exception { //创建bloom过滤器,expectedInsertions表示创建多少个,fpp表示误判率,误判率越低,采用hash算法越多,占用内存也会变大。 BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), 10000, 0.05); //模拟存储用户id数据 List<Integer> list = new ArrayList<>(10000); for (int i = 0; i < 10000; i++) { list.add(i); bloomFilter.put("user:id:"+i); } //赋值 BloomFilterCache.userIdCache = bloomFilter; } }
使用:
@RestController @RequestMapping("/bloom") public class BloomFilterController { @Autowired private StringRedisTemplate redisTemplate; @ApiOperation("判断用户id数据是否存在") @GetMapping("/test/{id}") public String getString(@PathVariable("id") String id){ if(!BloomFilterCache.userIdCache.mightContain("user:id:"+id)){ return "数据不存在"; } return redisTemplate.opsForValue().get("user:id:1000"); } }
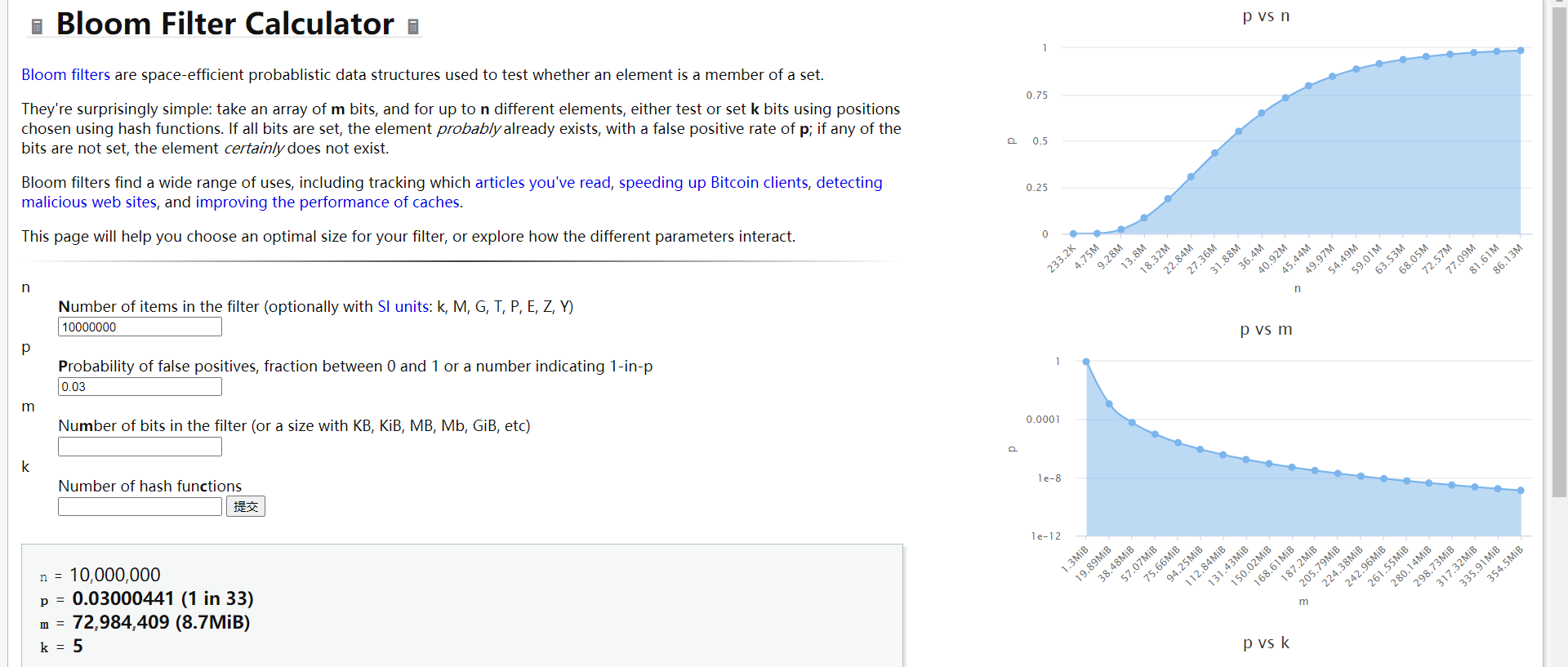
计算布隆过滤器的大小:
https://hur.st/bloomfilter/?n=10000000&p=0.03&m=&k=