一 lris 数据集
lris数据集是经典的机器学习数据集,它源自于20世界30年代对花朵特征的统计数据。测量的每个花的特征数据如下:
1 花萼长度 sepal length (cm)
2 花萼宽度 sepal width (cm)
3 花瓣长度 petal length (cm)
4 花瓣宽度 petal width (cm)
我们需要利用以上特征对花朵进行分类,这就是监督学习分类问题:对于给定的带有规则的标签样本,我们需要设计一种规则,然后通过这种规则,最终实现对其他样本的预测。
首先要做的是数据可视化,原来数据具有四个维度,我们可以分别用每两个维度画出一张图,这样一共得到6张图。如下:
from pprint import pprint import matplotlib.pyplot as plt from sklearn.datasets import load_iris # 使用sklearn中的iris数据集 data = load_iris() features = data['data'] feature_names = data['feature_names'] target = data['target'] # 可视化数据,将数据在两个维度上映射,得到6个图 ''' Setosa : 标志位x,颜色红 Versicolor: 标志为o,颜色绿色 Virginica : 标志为<,颜色蓝色 ''' pairs = [(0,1),(0,2),(0,3),(1,2),(1,3),(2,3)] for i,p in enumerate(pairs): plt.subplot(2,3,i+1) for t,marker,c in zip(range(3),'xo<','rgb'): plt.scatter(features[target == t,p[0]], features[target == t,p[1]], marker = marker, c = c) plt.xlabel(feature_names[p[0]]) plt.ylabel(feature_names[p[1]]) plt.grid() plt.show()
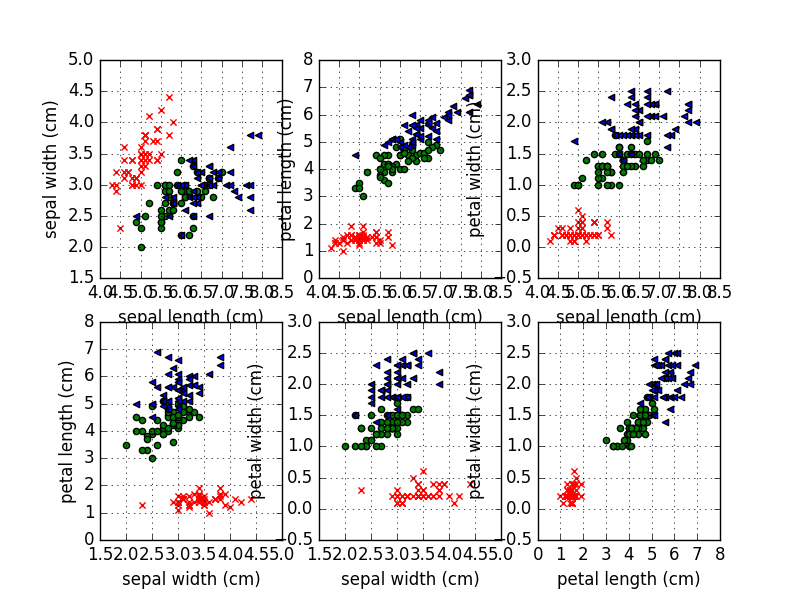
从图片清楚的可以看到iris Setosa 很容易分出来,只需要写一点代码,根据一个维度就可以完全分离出来。
plength = features[:,2] is_setosa = (target == 0) max_setosa = plength[is_setosa].max() min_non_setosa = plength[~is_setosa].min() print max_setosa,min_non_setosa # max_setosa =1.9 ,min_non_setosa = 3.0
于是,可以构造一个分离 Iris Setosa的一个简单模型,如果花瓣长度小于(1.9+3)/2 = 2.45,那么他就是Iris Setosa,否则就是其他两种花。然而我们无法立即找到另外两种花的分类规则。
接下来,我们使用所有的特征和阈值进行遍历,寻找更高的正确率:
# 选择非setosa的花种 features = features[~is_setosa] labels = labels[~is_setosa] virginica = (labels == 'virginica') # 遍历每个特征,和所有的分界值 best_acc = -1.0 best_t = -1.0 best_fi = -1.0 for fi in range(features.shape[1]): thresh = features[:,fi].copy() thresh.sort() for t in thresh: pred = (features[:,fi] > t) acc = (pred == virginica).mean() #计算布尔数组平均值获得正确结果所占比例 if acc > best_acc: best_acc = acc best_t = t best_fi = fi print best_acc,best_fi,best_t
结果的到了最高准确率为0.94.这个模型在全部的数据上运行,然而94%的准确率也许过于乐观了,因为我们使用这个数据去确定阈值,而又使用这组数据来评价我们的模型。该模型的效果当然比其他所有我们在数据集上尝试的效果要好。这种做法实际上是犯了逻辑上的循环论证错误。接下里下一节将介绍交叉验证。