之前学习了基于协同过滤的推荐。 在写同意后过滤中,通过和你购买了同样的物品的人也购买了其他物品来推荐。协同过滤的难点包括数据稀疏问题和扩展问题。另一个问题是基于协同过滤的推荐倾向于推荐已经流行的商品。这种情况可能导致‘富者越富贫者越贫’。流行音乐平台Pandora的推荐基于一种称为音乐基因的项目分析师会在超过400中的基因(特性)上进行评分。
Pandora构建音乐的做法是,大部分音乐基因取值范围在1到5之间,每两个相邻值差距为0.5,根据不同的特征,Pandora将没首音乐表示成400维的向量,然后按照标准距离来推荐音乐,这个和前面协同过滤很想,就是根据两首歌曲距离来找出相似的歌曲,然后进行推荐。
取值范围问题:
在实际问题中,某些属性的量纲不同,从而在数据值上可能有较大的差别,这样计算出来的距离的值完全依赖于较大值,使得结果偏离实际。解决办法是将数据归一化。归一化是消除数据偏斜性的好办法,有的时候也叫作标准化。一个常用的归一化方法是将数据转换为0到1之间。
标准分数 = ((每个值) - (均值)) /(标准差)
标准差定义如下:
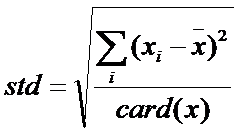
使用标准分数会带来一些问题,标准分数会受到离群点的剧烈影响。由于均值存在上述问题,所以往往会对标准差公式进行改进,改进的标准分数公式用到一种不绝对标准差asd:
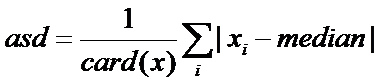
其中 median表示中位数,改进标准分数 = (每个值 - 中位数)/绝对标准差。综上介绍,标准化步骤如下:
1 计算中位数
2 计算绝对偏差
3 计算改进的标准分数
在实际应用中,由于一些尺度的原因,值比较大的属性在计算中会占据主导地位。在下面情况下,应该归一化:
1 所用数据挖掘方法基于图特征的值来计算两个对象的距离
2 不同特征尺度不同(特别是在显著不同时)
最近邻分类器
分类器使用一个已标记好的类别的集合。它利用这个集合对新的未标记的对象进行分类。考虑某个用户对一首歌曲是喜欢还是不喜欢,如果我们计算得到的该歌曲最近邻是一首该用户喜欢的歌曲,那么我们预测该用户也会喜欢这首歌。在这种情况下,我们的任务就是将歌曲分到两个类(喜欢/不喜欢)的一个中去。
下面是一个体育项目的分类问题。信息如下表,现在假设给出前10个人的分类,分类属性为 年龄,身高,体重,分类类别是体育项目,后10个人作为测试。现在给出下面10个人中的任何一个人信息,按照上述构造的分类器规则,确定该运动员的类别。
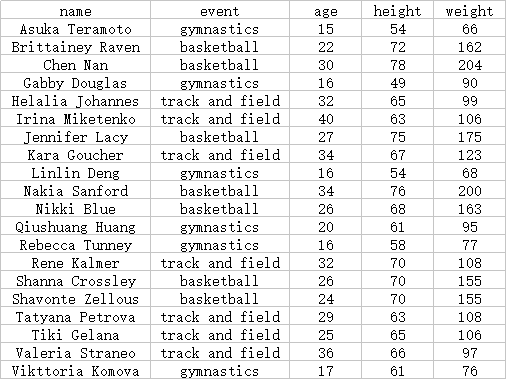
将数据导入数据库,为了练习下数据库的使用。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# __author__ : '小糖果'
import xlrd
import os
import sqlite3
from pprint import pprint
path = r'C:UsersTDDesktopPythonProject'
wb = xlrd.open_workbook(os.path.join(path,'athlete.xls'))
ws = wb.sheet_by_name('Sheet1')
conn = sqlite3.connect('athlete.db')
cursor = conn.cursor()
try:
cursor.execute('''
CREATE TABLE information(
name text PRIMARY KEY ,
event text,
age INT ,
height FLOAT ,
weight FLOAT
)
''')
except sqlite3.OperationalError:
pass
query = 'INSERT INTO information VALUES (?,?,?,?,?)'
for i in range(1,ws.nrows):
vals = []
for j in range(ws.ncols):
vals.append(ws.cell_value(i,j))
cursor.execute(query,vals)
cursor.close()
conn.commit()
conn.close()
基于最近邻的推荐代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# __author__ : '小糖果'
import sqlite3
from pprint import pprint
import scipy as sp
import sys
class Classfier(object):
def __init__(self,db_name):
conn = sqlite3.connect(db_name)
cursor = conn.cursor()
cursor.execute(
'SELECT * FROM information')
self.data = cursor.fetchall()
cursor.close()
conn.close()
@staticmethod
def standarVector(vector):
m = sp.median(vector)
asd = sp.sum([abs(x -m) for x in vector])*1./len(vector)
vector = [(x-m)/asd for x in vector]
return vector
def standardization(self):
# 将三个数值向量标准化
age = self.standarVector([alt[2] for alt in self.data])
height = self.standarVector([alt[3] for alt in self.data])
weight = self.standarVector([alt[4] for alt in self.data])
# 修改原数据为标准化后的数据
for i in range(len(self.data)):
self.data[i] = (self.data[i][0],
self.data[i][1],
age[i],
height[i],
weight[i])
@staticmethod
def minkowski(vec1,vec2,r):
return pow(sum([abs(x1 -x2)**r for x1,x2 in zip(vec1,vec2)]),1./r)
def nearestNeihbor(self,name):
# 获得信息
for i in range(10,len(self.data)):
if name == self.data[i][0]:
break
if i >= len(self.data):
print 'not found'
sys.exit(-1)
athlete = self.data[i]
# 寻找最近邻
neighbor = (float('inf'),)
for ath in self.data[:10]:
dis = self.minkowski(ath[2:],athlete[2:],2)
if dis < neighbor[0]:
neighbor = (dis,ath)
return neighbor[1]
def getClassfy(self,name):
return self.nearestNeihbor(name)[1]
def test():
instance = Classfier('athlete.db')
instance.standardization()
print " 姓名 预测类别 实际类别"
for athlete in instance.data[10:]:
print "{:<20}{:<20}{:<20}".format(athlete[0],athlete[1],instance.getClassfy(athlete[0]))
if __name__ == "__main__":
test()
输出结果如下:
姓名 预测类别 实际类别
Nikki Blue basketball basketball
Qiushuang Huang gymnastics gymnastics
Rebecca Tunney gymnastics gymnastics
Rene Kalmer track and field track and field
Shanna Crossley basketball basketball
Shavonte Zellous basketball basketball
Tatyana Petrova track and field track and field
Tiki Gelana track and field track and field
Valeria Straneo track and field track and field
Vikttoria Komova gymnastics gymnastics
得到的结果与实际结果惊人的一致。