Slope One 算法是由 Daniel Lemire 教授在 2005 年提出的一个 Item-Based 推荐算法。 他的主要优点是简单,易于扩展。实际上有多个Slope One算法,在此主要学习加权的Slope One算法。它将分为两步,第一步 为计算所有物品间的偏差,第二步利用偏差进行预测。下面分两步介绍该算法,并给出python实现的程序。
第一步 : 计算偏差
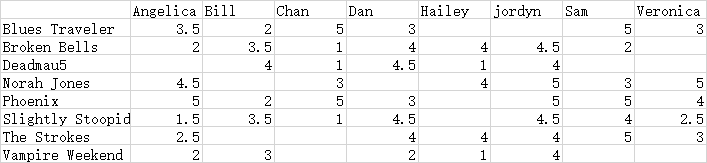
基于下面用户对乐队的评分例子:
先计算偏差,物品 i 到物品 j 的平均偏差为:
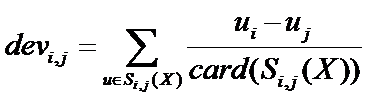
其中card(S)表示S中元素的个数,X是整个评分集合。因此card(Si,j(X))是所有同时对 i 和 j 进行评分的用户集合。从公式容易可以看出:
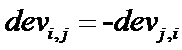
然后是维护问题,考虑如下问题:倘若又有新用户对其中的10个物品进行了评分,我们是否有必要重新计算dev矩阵。显然如果重新计算,性能问题将成为瓶颈,计算量会大的惊人。然而只要我们事先记录了两个物品的偏差同时,还记录下同时对两个物品评分的用户数目即可。这样可以在旧数据基础上更新了,大大减少了运算量,这也是Slope one算法的一个优点,易于维护。
第二步,利用加权Slope One 算法进行预测
Slope One的预测公式如下:
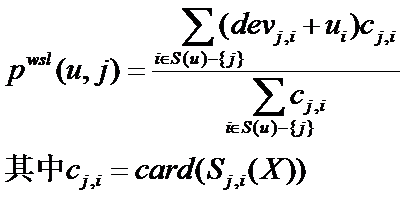
Pwsl(u,j)指的是利用加权Slope One算法给出用户 u 对物品 j 的评分预测值。S(u)表示所有u评级过的物品的集合。实际上这个加权的权重根据评分用户数得出的。
基于python的实现:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# __author__ : '小糖果'
import json
import sys
from math import sqrt
from pprint import pprint
class Recommender(object):
def __init__(self,data):
'''
frequencies用来记录共同评价i,j物品的用户数目
deviations用来记录物品i与j的评分差值
'''
self.frequencies = {}
self.deviations = {}
self.data = data
def computeDeviations(self):
"""
计算dev(i,j)以及同时评级i,j物品的用户数,data数据为
json格式的字典
"""
'''遍历每一个人的评分记录'''
for ratings in self.data.values():
for (item,rating) in ratings.items():
self.frequencies.setdefault(item,{})
self.deviations.setdefault(item,{})
''' item和item2是该用户评分记录中的两个物品'''
for (item2,rating2) in ratings.items():
if item != item2:
self.frequencies[item].setdefault(item2,0)
self.deviations[item].setdefault(item2,0.)
self.frequencies[item][item2] += 1
self.deviations[item][item2] += rating - rating2
# 接下来计算dev
for (item,ratings) in self.deviations.items():
for item2 in ratings:
self.deviations[item][item2] /= self.frequencies[item][item2]
def slopeOneRecommendations(self,username):
userRatings = self.data[username]
recommendtions = {}
frequencies = {}
for (userItem,userRating) in userRatings.items():
for (diffItem,diffRatings) in self.deviations.items():
if diffItem not in userRatings and
userItem in diffRatings:
freq = self.frequencies[diffItem][userItem]
recommendtions.setdefault(diffItem,0.)
frequencies.setdefault(diffItem,0)
recommendtions[diffItem] +=
(self.deviations[diffItem][userItem] + userRating)*freq
frequencies[diffItem] += freq
recommendtions = [(item,rating/frequencies[item])
for (item,rating) in recommendtions.items()]
recommendtions.sort(key = lambda ele:ele[1],reverse = True)
return recommendtions
def test():
with open('records.json','r') as f:
users = json.load(f)
instance = Recommender(users)
instance.computeDeviations()
print instance.slopeOneRecommendations('Bill')
if __name__ == '__main__':
test()