在机器学习问题中,我们根绝解决的问题将机器学习算法归纳为三类:回归(regression)问题、分类(classification)问题及聚类(clustering)问题。作为机器学习三大解决的三大问题之一的回归问题,前辈们做了很多深入的研究,尤其是回归问题的两类难点问题(多重共线性及特征选择),在此随笔中,我主要根据prml开篇对多项式曲线拟合的试验,讨论影响回归模型泛化能力的两种因素及处理方法。
在本书中,作者举了一个用多项式回归拟合例正弦函数f(x)=sin(2∏x)的例子,给定一个包含10个数据点的数据集 x=(x1,x2,...,x10)T,伴随带有随机噪声的y的观测值y=(y1,y2,...,y10)T,下面画出10个数据点组成的图像:
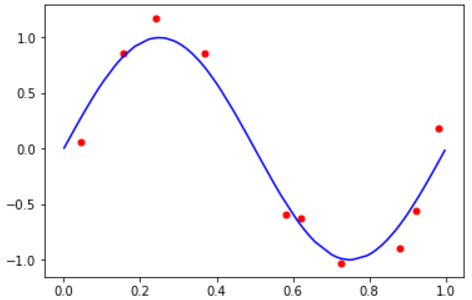
图1:由N=10个数据点组成的训练集的图像,由红色圆点标记。每个数据点由输入变量x的观测及对应的目标
变量y组成,蓝色曲线给出了用来生成数据的sin(2∏x)函数。目标是通过新的x值预测y值,不需知道蓝色曲线。
下面用一种非正式的简单的多项式函数对数据拟合,多项式如下:

其中,m表示多项式的阶数,xj表示x的j次幂,w0,w1,...wm表示多项式系数,整体记为w,多项式函数y(x,w)是关于x的多非线性函数,但是是关于w的线性函数,此类回归问题也被称为线性回归.
在一般情况下,采用上述多项式拟合如图的个数据点的拟合方法有多种(取不同的m值就有不同的拟合多项式)。而在选择不同的多项式时,该多项式就有不同的系数参数,怎么确定多项式系数为最优参数呢,一般采用残差平方和什么样的最小准则,及对所有的x估计f(x)与对应的y的误差平方和最小值,如下:

下面是对刚生成的几个数据点取不同的误差平方和的多项式拟合情况: