30. 串联所有单词的子串
给定一个字符串 s 和一些长度相同的单词 words。找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。
注意子串要与 words 中的单词完全匹配,中间不能有其他字符,但不需要考虑 words 中单词串联的顺序。
示例 1:
输入:
s = "barfoothefoobarman",
words = ["foo","bar"]
输出:[0,9]
解释:
从索引 0 和 9 开始的子串分别是 "barfoor" 和 "foobar" 。
输出的顺序不重要, [9,0] 也是有效答案。
示例 2:
输入:
s = "wordgoodgoodgoodbestword",
words = ["word","good","best","word"]
输出:[]
Python most votes solution with some revision:
class Solution(object):
def findSubstring(self, s, words):
"""
:type s: str
:type words: List[str]
:rtype: List[int]
"""
if not s or words == []:
return []
lens = len(s)
lenword = len(words[0])
lenwords = len(words)*lenword
times = {}
for word in words:
if word in times:
times[word] += 1
else:
times[word] = 1
ans = []
for i in xrange(min(lenword,lens-lenwords+1)):
self.findAnswer(i,lens,lenword,lenwords,s,times,ans)
return ans
def findAnswer(self,strstart,lens,lenword,lenwords,s,times,ans):
wordstart = strstart
curr = {}
while strstart+lenwords <= lens:
word = s[wordstart:wordstart+lenword]
wordstart += lenword
if word not in times:
strstart = wordstart
curr.clear()
else:
if word in curr:
curr[word] += 1
else:
curr[word] = 1
while curr[word] > times[word]:
curr[s[strstart:strstart+lenword]] -= 1
strstart += lenword
if wordstart-strstart == lenwords:
ans.append(strstart)
分析:
(1)代码用到了“双指针 + 双字典”的结构:
-
指针wordstart用于”在前面探路“,它不断探索s中的下一个单词并指向下下一个单词的开头处;
指针strstart用于记录s中匹配字段的起点位置,以便于统计最终的结果。
-
字典times用于记录words中的各单词并统计他们在words中出现的次数;
字典curr用于统计s中匹配字段出现的各单词及它们出现的次数。
(2)对整个代码的解释如下:
-
首先要判断s或words是否为空,可以用not A或A == []来判断。Python中not的用法
-
其次,在代码中要频繁地使用三个长度,这里不妨先把它们记录下来:
字符串s的长度:lens 单词串words的长度:lenwords words中每个单词的长度:lenword -
程序中的第一个for循环的目的是将words中的单词组装成键值对的形式,保存到字典times中。组装的过程如下:
如果word不在times中,说明word是第一次被封装进times,此时为该word赋予初始value: 1;
如果word已经在times中,那么再次将该word封装进times时,让该word的value加1,以表示该word又一次出现。
-
ans用于记录最终的结果。
-
第二个for循环:
循环范围为什么是
for i in xrange(min(lenword, lens-lenwords+1))?以下面一个例子为例:
假设
s = 'barfoothefoobarman',words = ['foo', 'bar'],假设我们能够在s中找到匹配words中单词的子串,这里words的长度为6,s的长度为18。如果s的最后六个字母恰好能匹配words,那么在s中查找时,查找的起始位置必须要保证s中剩余的长度至少为6,即i必须要从'barman'之前开始查找,不能进入'barman',否则长度肯定不够。这说明i必须限制在lens-lenwords+1以内;另一方面,同样假设我们能够在s中找到匹配words中单词的子串,因为words中每个单词的长度为3,而且在后续代码中,我们是以lenword(这里为3)的间隔在s中查找的,这就相当于我们用一个长度为3的窗口在s上从左往右不断地滑动,而且滑动的步长为3,如下图所示:

当滑动窗的起始位置固定时,它就只能滑过s中固定位置的元素。假设滑动窗从左往右滑过s中全部的元素称为滑动窗滑了一轮,那么现在问题转换为:滑动窗至少需要滑动几轮,才能够找到s中匹配words的字符串?
答案是3轮,如下图所示:

因为从第四轮滑动起,就会和前面这三轮的滑动结果重合,只是跳过了前面几个字符。因此只需要三轮就可以找到所有匹配的字符串。
在以上分析的基础上,不难推广得到:若滑动窗的长度为lenword,则只需要滑动lenword轮,就可以在s中找到所有匹配的字符串。
综合以上两种考虑:当
i=lenword时,滑动窗足以找到所有的匹配字符串;而当i=lens-lenwords+1时,也足以找到所有匹配的字符串。因为i是出现在for循环中的,为了能够尽量减小时间复杂度(在此处即减少for循环的次数),应该让i能够取到的值越少越好,因此for循环的循环条件最终定为:for i in xrange(min(lenword, lens-lenwords+1))
(3)调用子函数findAnswer:
-
指针strstart和wordstart的初始位置都被设置为i。在后续的代码中,wordstart总是“冲在最前面”,去探索前面未知的字符串;而strstart总是“殿后”,它总是指向s中匹配字符串的起始位置。
-
因为相邻两次滑动的字符串没有任何关联,所以每一次当i变动时,curr都要重新被建立。
-
外层while循环的边界条件是
while strstart+lenwords <= lens它的意思是:若想保证strstart指向的是匹配字符串的起始位置,则从strstart的位置开始,到字符串s的末尾为止,这之间的字符串的长度必须要大于等于lenwords,否则是不可能会匹配的。
-
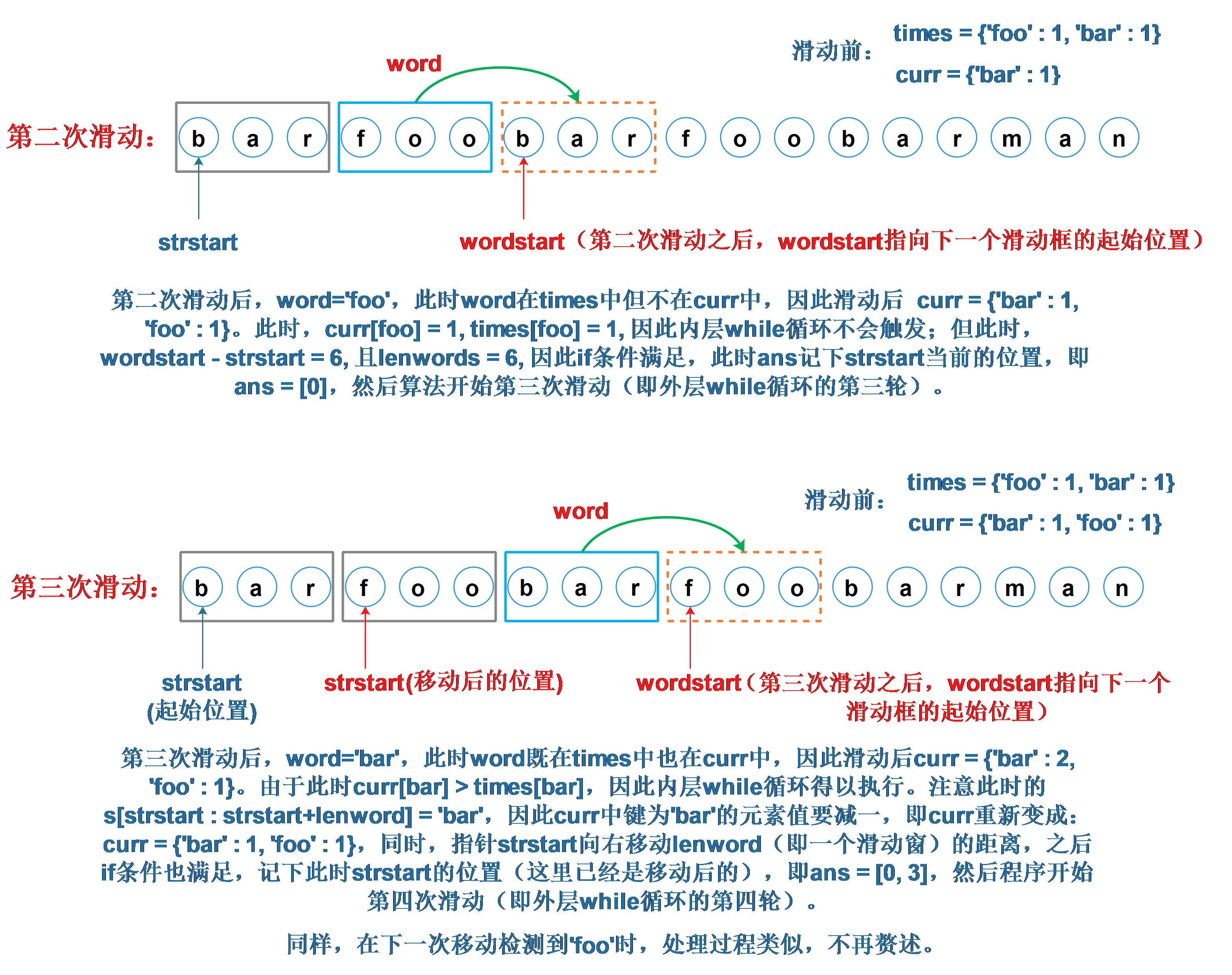
以i=0时的for循环为例,外层while循环的循环过程如下:
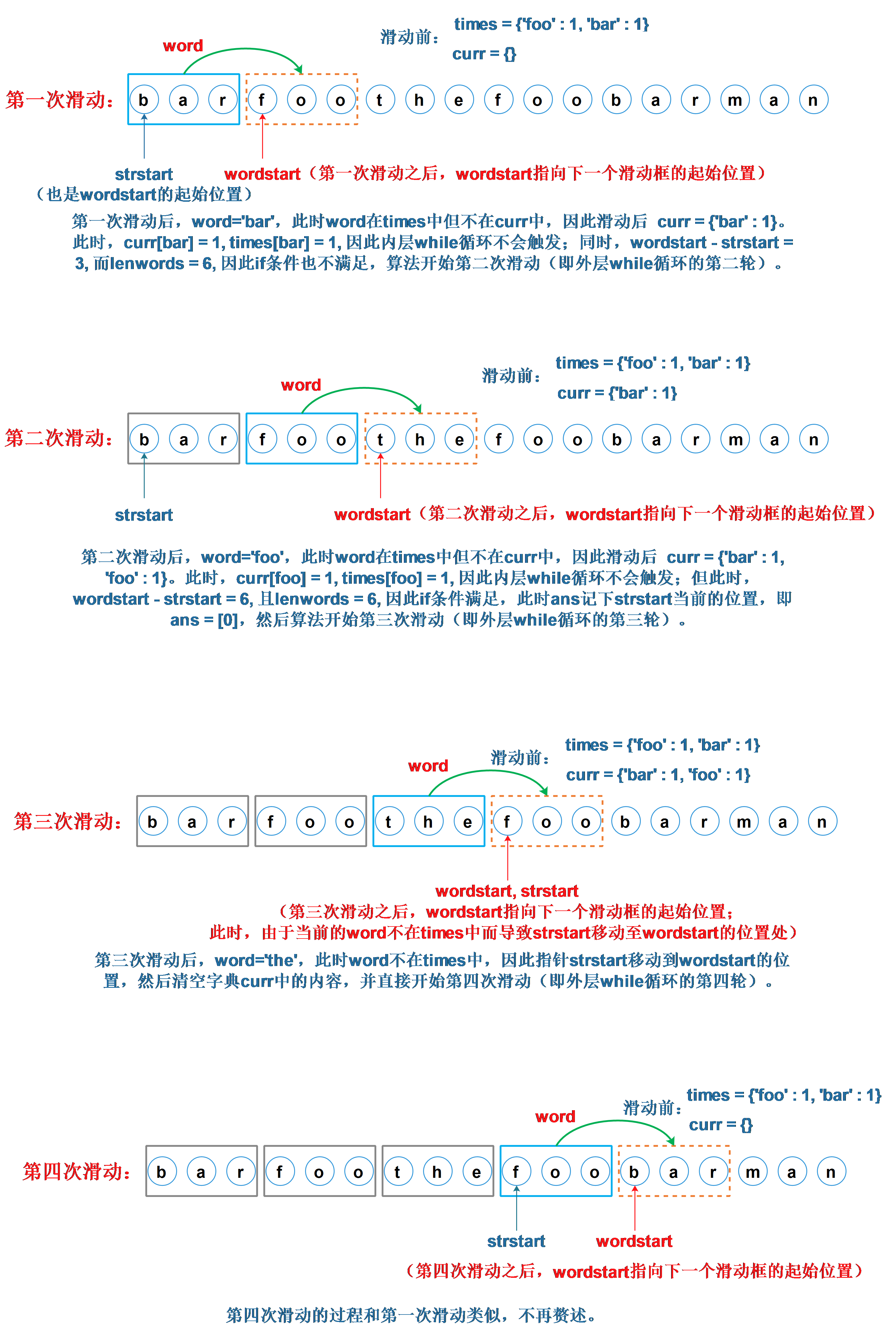
-
内层while循环的作用是什么呢?考虑第二次滑动后的情形,此时
curr = {'bar':1, 'foo':1},现假设第三次滑动时word = 'bar',则滑动后的结果如下所示: