words:
conceptually adv 概念地
training end-to-end from scratch 从头开始训练
meta-learning 元学习
unified adj 统一的
scalability n 可扩展性
emerging 作adj时 新出现的
stripy adj 有条纹的
resurgence n (中断之后)再度兴起
fine-tune 微调
alleviate vt 减轻
regime n 管理制度,组织方法
contemporary adj 同时代的,同期的
decompose vt & vi 分解
exemplar n 典范,样例
insufficient adj 不足的
promising adj 很有前途的,前景很好的
inference n 推理
metric n 原意是“度量标准”,可以译为“优值”
inductive adj 归纳的
outperform vt 做得比......更好,胜过
encompass vt 包括
compelling adj 令人信服的;引人入胜的
across the board adv 全体都包括在内
alternatives n 此处译为“其他的”
iterative adj 反复的,迭代的
iterate through 遍历(iterate 本身译为“重复”)
discriminative adj 判别的;有判别力的;歧视性的
surge n & vi 急剧上升;激增
in the sense that 在这个意义上,从这方面来说(可以翻译为“即”)
extract vt 提取,获得
configuration n 布局;配置
low-latency 低延时的
leverage n 杠杆作用(此处应该译为“借助”)
unrolling v 铺开,展开
appealing adj 吸引人的
adequacy n 足够
entail vt 招致,带来
in terms of 在......方面
be represented in 用......方法表示
prototypical network 原型网络
siamese network 孪生网络
span vt 跨越
align v 与......联合;使对准
manually adv 手工地
disjoint adj 分离的;不相交的
in principle 原则上;大体上
exploit vt (充分)发挥,(充分)利用
mimic vt 模仿
split 作n时 分支,划分
feed through 馈通,贯穿
be fed into 被送入
concatenate vt 把(一系列事件、事情等)联系起来
concatenation n 一连串相关联的事情
scalar n 标量
somewhat adv 稍微,有点
conceptually adv 在概念上
ground-truth n 参考标准;(机器学习中)数据正确的标签
analogous adj 相似的
in that 因为
datum n 数据;资料
straightforward 作adj时 简单的;坦率的
modality n 形式
heterogeneous adj 不同的
subnet n 子网络;分支网络
anneal vt 使退火
baseline n 基线,基准
statistician n 统计学家,统计员
deviation n 偏离,偏差
despite that 此处应译为“因为”
significantly adv 显著地;数量相当大地;有意义地
confidence interval n 置信区间
overlap n & v 重叠;相交
conduct vt 实施;执行
violate vt 违背
comprise vt 由......组成
benchmark n 基准,参照
hubness problem 枢纽点问题(即高维空间中,某些点会成为大多数点的最近邻点。)
cross-modal adj 跨通道的;交叉式的
inductive adj 归纳的
at the cost of 以......为代价
harmonic adj 调和的
specify vt 指定;详述
Mahalanobis distance 马氏距离
approximator n 逼近器
solely adv 唯一地;仅仅
element-wise adv 元素级地
separability n 可分离性
efficacy n 功效;效力
the extent to which ... ......的程度 (有多大)
jointly adv 共同地
symmetry n 对称
empirically adv 经验主义地
numerically adv 数字上地
trivial adj 平凡的;琐碎的
subsequent adj 后来的;随后的
cyan n 青色
magenta n 品红色(紫色和红色的混合色)
in terms of 根据;就......而言
penultimate adj 倒数第二的
tune vt 调整
在这篇文章中,作者提出了 Relation Network (RN) 的概念。
作者指出目前一些比较成功的深度网络存在的一些弊端:需要提供大量有标签的数据而且需要很多次的迭代来更新参数。
目前已有的 few-shot learning 存在的问题:要么需要复杂的推理机制,要么需要复杂的RNN架构,要么需要对目标问题进行 fine-tune 。
这篇论文采用的核心方法是:train an effective metric for one-shot learning 。对 few-shot learning 而言,要学得一个能比较图片之间关联度的优值;对 zero-shot learning 而言,要学得一个能比较图片和与之相关的类别的描述之间关联度的优值。
作者提出一个双分支结构的 RN ,通过比较 query image 和 few-shot labeled sample image,来实现 few-shot recognition。
整体架构由一个 embedding module 和一个 relation module 组成。前者用于产生 query image 和 training image,后者用于对 query image 和 training image 进行比较。
对前人工作的借鉴体现在:embedding module 和 relation module 都是 meta-learned end-to-end 的,创新点在于:没有使用 RNN (使网络结构更加简单),也没有使用 fine-tuning (使训练更快) 。
MAML方法通过 meta-learn 来找到一个合适的初始权重,为后续的 fine-tuning 做准备。这种方法的弊端是需要 fine-tuning ,作者通过 feed-forward 的方式避免了 fine-tuning 。
基于 RNN Memory 的方法进行 few-shot learning 有一个很大的弊端:memory 必须保证在存储很长的历史信息的同时,不会发生遗忘。作者采用的方法是通过 feed forward CNN 来实现 learning-to-learn approach 。
原型网络和孪生网络通过学习 embeddings 来转换数据,使得类别能够通过 fixed nearest-neighbour 或 linear classifier 识别出来。作者在此基础上,定义了一个 relation classifier CNN ,识别的手段变成了一个 learnable metric (而非 fixed metric) 或是 non-linear classifier (而非 linear classifier) 。
在 few-shot learning 中存在3个数据集:一个 training set,一个 support set,和一个 testing set。
C-way K-shot:如果 support set 中包含 C 个不同的类,而且每个类中包含 K 个有标签的样本时,此时的 few-shot 问题称为 C-way K-shot 问题。(e.g. K = 1 时称为 one-shot ,K = 5 时称为 five-shot ,K = 0 时称为 zero-shot 。)
作者指出,如果仅仅使用 support set ,原则上也可以训练出一个分类器,只是它的性能并不好。因此作者先在训练集上进行 meta-learning 以获取 transferrable knowledge ,再使用 support set 进行 few-shot learning ,这样得到的分类器效果会更好。
在每一轮迭代时,随机从训练集中挑出 C 个类,每个类 K 个样本,来构成 sample set S = {(xi, yi)} ;然后从剩下的部分中也挑出 C 个类,来构成 query set Q = {(xj, yj)} 。sample / query set 的目的是用来对 support / test set 进行 simulate 。
xi(来自 sample set S)和 xj(来自 query set Q)通过 embedding module f_phi 产生两个 feature map f_phi(xi) 和 f_phi(xj) ,然后由 operator C(· , ·) 结合起来,构成 C(f_phi(xi) , f_phi(xj)) 。
经过 operator C(· , ·) 结合之后的 feature map(即 C(f_phi(xi) , f_phi(xj)) )被送入 relation module g_phi ,并产生一个(0,1)之间的相关系数,以此来表征 xi 和 xj 之间相似度的大小。
在 C-way one-shot 问题中,总共会产生 C 个相关系数( query input 只有一个 xj ,sample input 共 C 类,每类只有 1 个,因此总共会产生 C 对 feature map)。
5-way 1-shot 的架构如下:
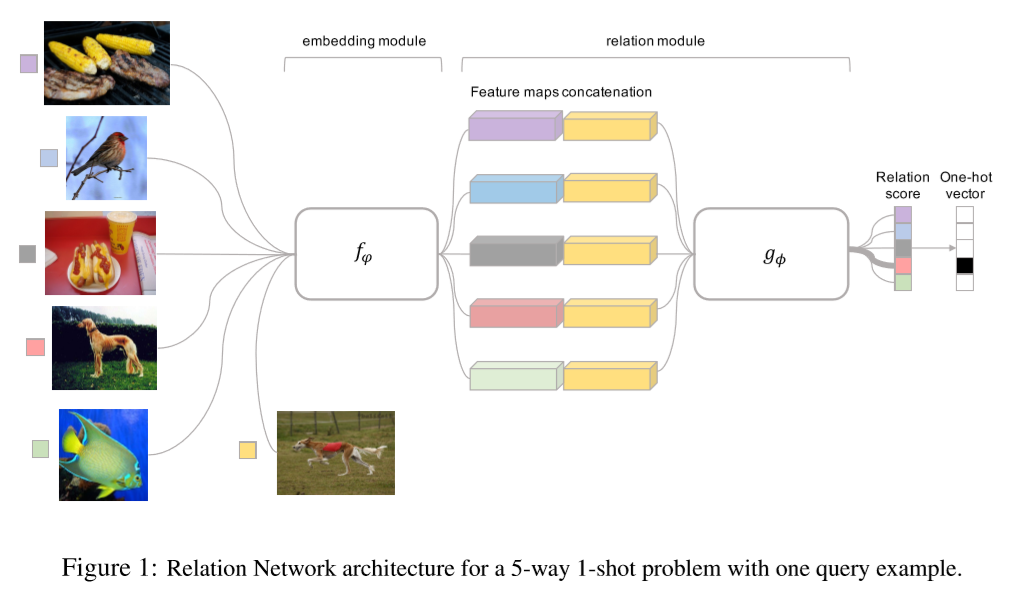
作者将该 few-shot learning 问题视为回归相关系数的问题而非分类问题,因此损失函数采用的是 MSE 而非 CrossEntropy 。
大多数 few-shot learning model 的 embedding model 都使用了 4 个卷积块,为了比对的公平性,作者也采取了同样的架构设计,如下图所示:
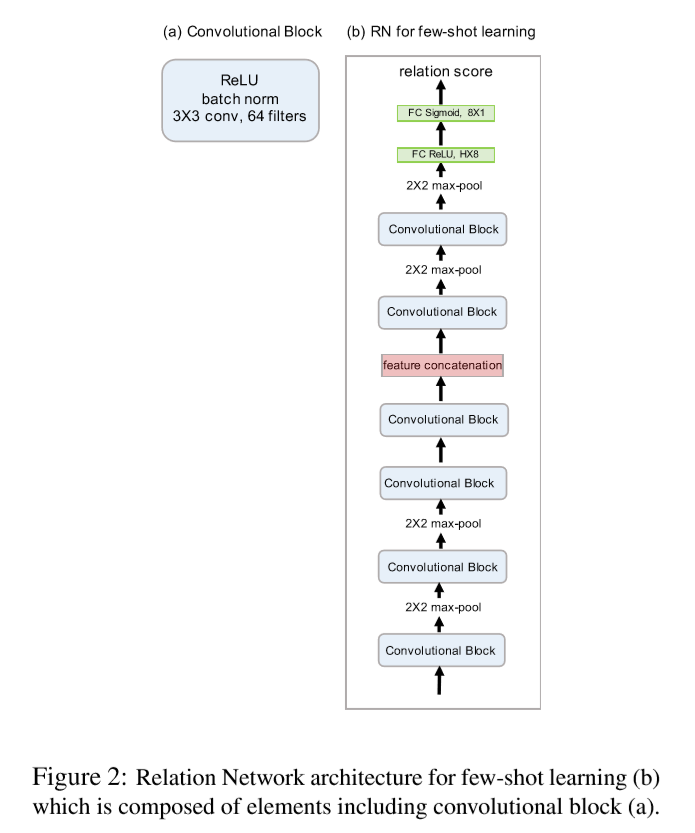
每一个 Convolutional Block 都包含了 64 个 3x3 的卷积核、一个 batch normalisation 层和一个 ReLU 层。embedding module(箭头从下往上数的前4个 Convolutional Block)中的前两个 block 还各自包含一个 2x2 的 max-pooling 层,后两个 block 则没有。这样做的目的是希望得到的 feature map 能够继续参与其他的卷积运算(这里指的是 relation module 中的卷积运算),因为如果 embedding module 中的 pooling 层太多,feature map 的尺寸会迅速减小,这样在 relation module 中可供利用的信息就会很少,不利于相关系数的计算。
relation module 由两个 convolutional block 和两个 fully-connected layer 组成,在两个 convolutional block 后面还各自连接了两个 2x2 的 max-pooling 层。沿着箭头的方向,第一个 fully-connected layer 是 8 维的且激活函数是 ReLU,第二个 fully-connected layer 是 1 维的且激活函数是 Sigmoid(采用 Sigmoid 是为了产生(0,1)之间的相关系数)。
所有的与 few-shot learning 有关的实验采用的都是 Adam 方法,初始学习率设置为 0.001,每 100,000 轮衰减为原来的一半。
作者将自己的工作和其他 state of the art 工作进行了对比,这些工作包括:
neural statistician
Matching Nets with and without fine-tuning
MANN
Siamese Nets with Memory
Convolutional Siamese Nets
MAML
Meta Nets
Prototypical Nets
Meta-Learner LSTM
作者对数据集进行了增强:对 Omniglot 数据集,将原始图片分别旋转 90 度,180 度和 270 度得到增强后的数据集,从原始的数据集中挑出 1200 个类,和与之对应的增强后的数据一起,用作训练;将剩下的 423 个类和与之对应的增强后的数据一起,用作测试。所有的图片都被 resize 成 28x28 。
在实际训练时,5-way 1-shot 总共有 20 个 query image,5-way 5-shot 也有 20 个 query image,20-way 1-shot 有 11 个 query image,20-way 5-shot 有 10 个 query image 。
因此 5-way 1-shot 在每一轮训练中都有 20x5 = 100 个 image 。
在 Omniglot 数据集上:作者在比较训练结果时,是将1000次随机测试的结果进行平均。作者指出,5-way 5-shot 比最好结果低 0.1% 是因为那些训练结果要么机制复杂,要么使用了 fine-tune ,而作者并没有采用这些方法。
在 miniImageNet 数据集上,作者分别选了 64,16,20 个类分别用于 training,validation 和 testing 。其中,16 个 validation class 仅仅用来监测泛化性能。作者依据现有的 few-shot learning 工作,分别做了 5-way 1-shot 和 5-shot 的分类测试。
作者在列举为什么 Relation Network 可以 work 时,指出了前面一些 few-shot work 采用的方法:learning a fixed metric or fixed features and shallow learned metric 。与这些方法不同的是,Relation Network 可以认为是同时 learning a deep embedding and learning a deep non-linear metric (similarity function)。
总结:
作者提出了 Relation Network 的方法来解决 few-shot 和 zero-shot learning 的问题。Relation Netwoek 通过学习 an embedding and a deep non-linear distance metric 来比较 query 和 sample items 。
补充:
关于 Zero-Shot Learning 一篇很好的入门文章:https://blog.csdn.net/tianguiyuyu/article/details/81948700