正文
一,引言
前面我们学习过mapReduce编程,通过哪些简单的例子发现,处理数据时开发成本过高。而且不易于普通大众学习,那么有没有什么办法,把HDFS中的哪些结构化的数据文件变成一张张类似MySQL的关系型的数据库表呢?若有的话我们就可以通过类似SQL这种机制轻松便捷的处理数据了。这就是我们这里讲的Hadoop生态中非常重要的Hive。
二,什么是Hive
2.1 hive是什么
在Hadoop中,hive是用来处理hadoop中的结构化数据的数据仓库工具。
2.2 hive的特点
1),hive在hadoop中,是在HDFS之上,数据来源基于HDFS。处理过后的数据也是存储到HDFS中。
2),hive可以将结构化的数据映射成一张表,表现形式类似于MySQL的表,在HDFS中还文件。
3),hive可以使用SQL来进行数据处理,底层的逻辑就是将用户提交的SQL转转换成MapReduce任务去执行。(这里的SQL是HSQL和大多数SQL一致)
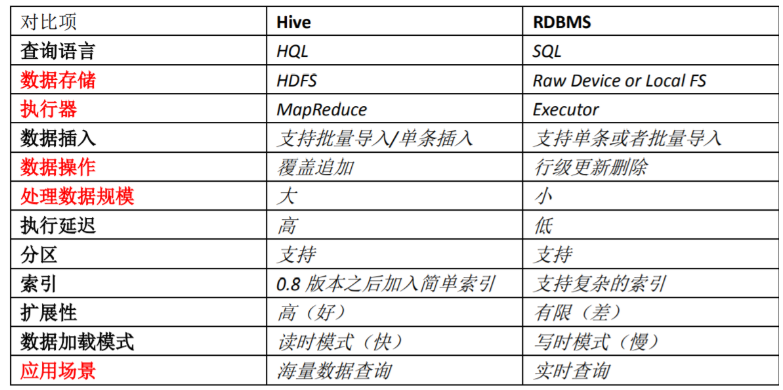
2.3 hive与RDBMS的对比
1),hive主要用于OLAP(联机分析处理)。而RDMBS(关系型数据库)主要用于OLTP(联机事务处理)
2),hive不可以随时进行update和insert。因为底层是HDFS中是文件,不易于update和insert。
3),hive的扩展性强,主要的针对海量数据。而RDMBS一般。
4),RDMBS的SQL执行速度快,而hive执行速度慢(底层是MapReduce实现)
5),hive不支持事务,而RDMS可以
其他对比如下:
三,Hive的架构
下图为Hive的架构图:
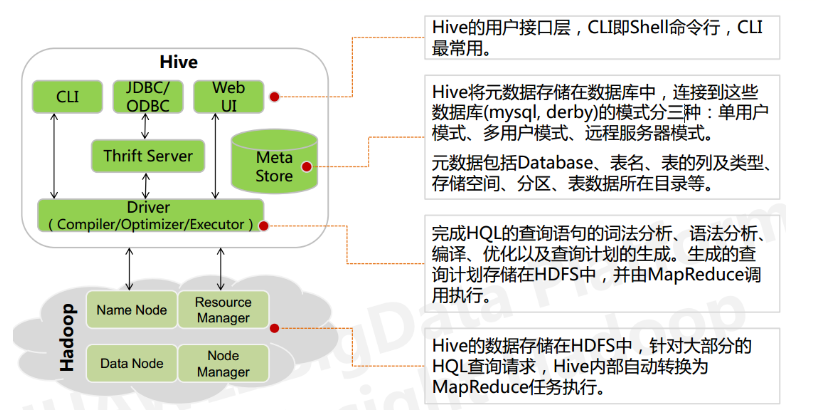
3.1 用户接口与界面
1),CLI,Shell 终端命令行(Command Line Interface):采用交互形式使用 Hive 命令行与 Hive 进行交互,最常用(学习,调试,生产)
2),JDBC/ODBC:是 Hive 的基于 JDBC 操作提供的客户端,用户(开发员,运维人员)通过这连接至 Hive server 服务
3),Web UI,通过浏览器访问 Hive。常用的有Hue(这个在以后比较常用)
3.2 跨语言服务
用户可以通过Thrift server,从而使用不同的语言来操纵Hive。Thrift Server:hive集成了该服务,作用就是,让不同的语言调用Hive接口。
3.3 元数据存储
元数据:在Hive中非重要的就是元数据。该数据是用来描述Hive中数据库或表的信息的。因为hive中的数据本质是存储在HDFS中的文件,如何将这些文件映射成表,就是通过元数据的描述。所以元数据是至关重要的。
Hive 中的元数据通常包括:表的名字,表的列和分区及其属性,表的属性(内部表和 外部表),表的数据所在目录
Metastore 默认存在自带的 Derby 数据库中。一般情况下是不用数据库,而是通过自己配置来指定数据库。常用的是MySQL。
3.4 底层驱动(driver)
Driver 组件完成 HQL 查询语句从词法分析,语法分析,编译,优化,以及生成逻辑执行 计划的生成。生成的逻辑执行计划存储在 HDFS 中,并随后由 MapReduce 调用。
Hive 的核心是驱动引擎, 驱动引擎由四部分组成:
(1) 解释器:解释器的作用是将 HiveSQL 语句转换为抽象语法树(AST)
(2) 编译器:编译器是将语法树编译为逻辑执行计划
(3) 优化器:优化器是对逻辑执行计划进行优化
(4) 执行器:执行器是调用底层的运行框架执行逻辑执行计划
四,Hive的工作原理
如下图所示,表示的是Hive工作流程图:
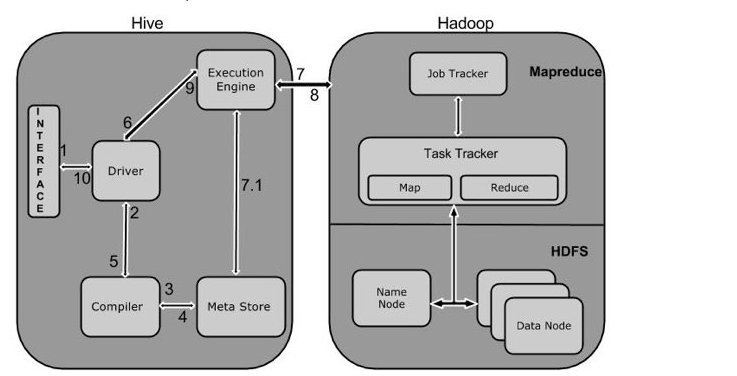
流程解析:
1),调用Hive接口,如命令行或Web UI发送查询驱动程序(任何数据库驱动程序,如JDBC,ODBC等)来执行。
2),在驱动程序帮助下查询编译器,分析查询检查语法和查询计划或查询的要求。
3),编译器发送元数据请求到Metastore(任何数据库)。
4),Metastore发送元数据,以编译器的响应。
5),编译器检查要求,并重新发送计划给驱动程序。到此为止,查询解析和编译完成。
6),驱动程序发送的执行计划到执行引擎。
7),在内部,执行作业的过程是一个MapReduce工作。执行引擎发送作业给JobTracker,在名称节点并把它分配作业到TaskTracker(这里也有肯尼是同Yarn)这是在数据节点。在这里,查询执行MapReduce工作。与此同时,在执行时,执行引擎可以通过Metastore执行元数据操作
8),执行引擎接收来自数据节点的结果。
9),执行引擎发送这些结果值给驱动程序。
10),驱动程序将结果发送给Hive接口。
五,Hive的数据类型
5.1 基本数类型

5.2 集合数据类型

5.3 案例
下面是一个案例,具体后面文章谈及:
hive>create table employees( > name string, > salary float, > subordinates array<string>, > deductions map<string,float>, > address struct<street:string,city:string,state:string,zip:int> > );
5.4存储格式
Hive会为每个创建的数据库在HDFS上创建一个目录,该数据库的表会以子目录形式存储,表中的数据会以表目录下的文件形式存储。对于default数据库,默认的缺省数据库没有自己的目录,default数据库下的表默认存放在/user/hive/warehouse目录下。
1),textfile:textfile为默认格式,存储方式为行存储。数据不做压缩,磁盘开销大,数据解析开销大。
2),SequenceFile:SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。 SequenceFile支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。
3),RCFfile:一种行列存储相结合的存储方式。
4),ORCfile:数据按照行分块,每个块按照列存储,其中每个块都存储有一个索引。hive给出的新格式,属于RCFILE的升级版,性能有大幅度提升,而且数据可以压缩存储,压缩快 快速列存取。
5),Parquet:Parquet也是一种行式存储,同时具有很好的压缩性能;同时可以减少大量的表扫描和反序列化的时间。