布隆过滤器的原理:
布隆过滤器是一种多哈希函数映射的快速查找算法。它可以判断出某个元素肯定不在集合里或者可能在集合里,即它不会漏报,但可能会误报。通常应用在一些需要快速判断某个元素是否属于集合,但不严格要求100%正确的场合。
基本原理:
一个空的布隆过滤器是一个m位的位数组,所有位的值都为0。定义了k个不同的符合均匀随机分布的哈希函数,每个函数把集合元素映射到位数组的m位中的某一位。
添加一个元素:
先把这个元素作为k个哈希函数的输入,拿到k个数组位置,然后把所有的这些位置置为1。
查询一个元素(测试这个元素是否在集合里):
把这个元素作为k个哈希函数的输入,得到k个数组位置。这些位置中只要有任意一个是0,元素肯定不在这个集合里。如果元素在集合里,那么这些位置在插入这个元素时都被置为1了。如果这些位置都是1,那么要么元素在集合里,要么所有这些位置是在其他元素插入过程中被偶然置为1了,导致了一次“误报”。
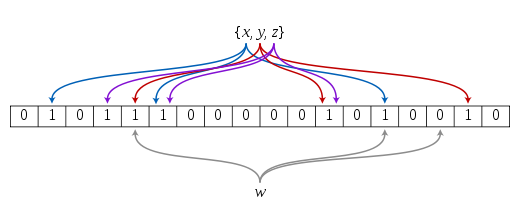
一个布隆过滤器的例子见下图,代表了集合{x,y,z}。带颜色的箭头表示了集合中每个元素映射到位数组中的位置。元素w不在集合里,因为它哈希后的比特位置中有一个值为0的位置。在这个图里,m=18,k=3。
简单的布隆过滤器不支持删除一个元素,因为“漏报”是不允许的。一个元素映射到k位,尽管设置这k位中任意一位为0就能够删除这个元素,但也会导致删除其他可能映射到这个位置的元素。因为没办法决定是否有其他元素也映射到了需要删除的这一位上。
通过好几个哈希函数来共同判断这个元素是否在集合里,比只用一次哈希带来冲突的可能性要低很多。暴雪的MPQ归档文件中使用的哈希算法跟布隆过滤器也有异曲同工之妙。
误判率
误报率主要是基于概率基础进行的推导,本文不再介绍,想了解的可以参考链接
Java Demo:
- maven依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>22.0</version>
</dependency>
- code:
package buct.edu.cn;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class Demo1 {
public static void main(String[] args) {
BloomFilter<Integer> filter = BloomFilter.create(
Funnels.integerFunnel(),
500,
0.01);
filter.put(1);
filter.put(2);
filter.put(3);
boolean result = filter.mightContain(4);
System.out.println(result);
}
}
关于布隆过滤器的持久化问题,请参考:布隆过滤器(BloomFilter)持久化
更多参考:
Bloom Filter in Java using Guava
Bloom Filters by Example
Bloom filter