字符编码
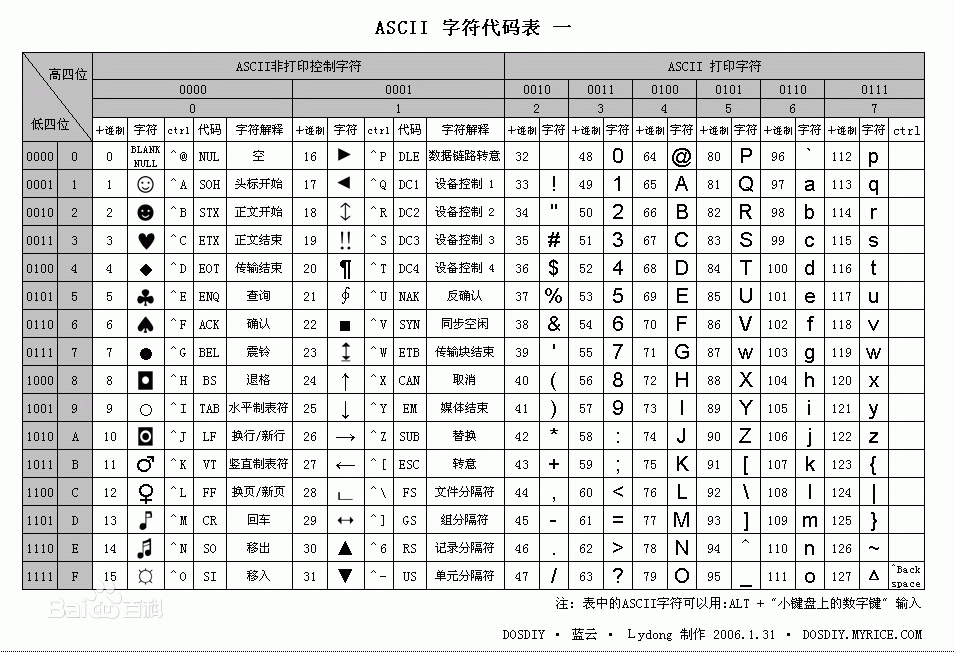
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个符号。
关于中文
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。GB2312 支持的汉字太少。
1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,注:此处说的的是最少2个字节,可能更多。
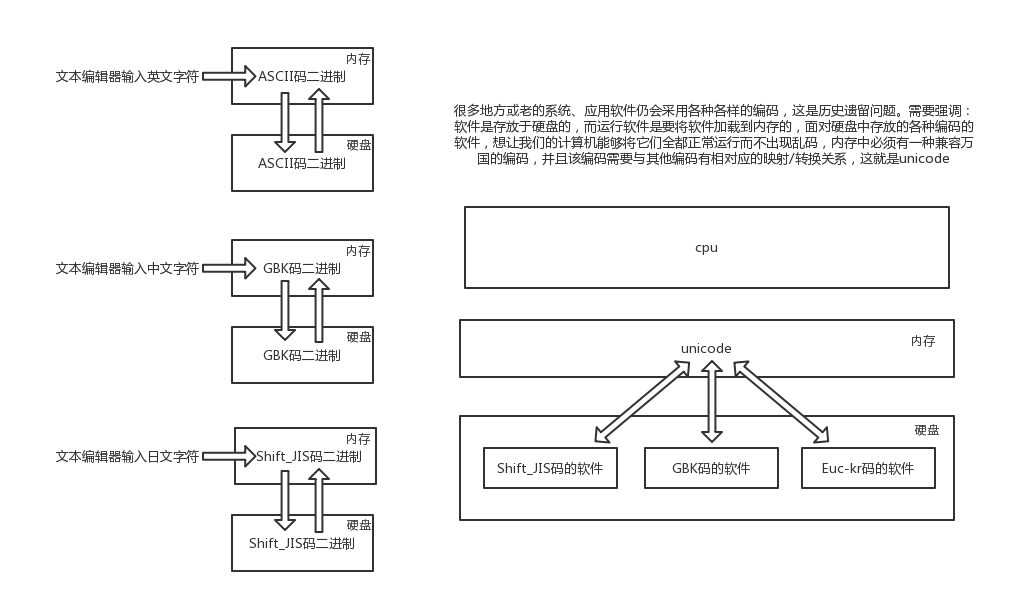
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码,python2默认的是ASCII编码,而python3默认的是UTF-8。
计算机基础知识
python解释器执行py文件的原理
#第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器 #第二阶段:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中(小复习:pyhon的解释性,决定了解释器只关心文件内容,不关心文件后缀名) #第三阶段:python解释器解释执行刚刚加载到内存中test.py的代码( ps:在该阶段,即真正执行代码时,才会识别python的语法,执行文件内代码,当执行到name="egon"时,会开辟内存空间存放字符串"egon")
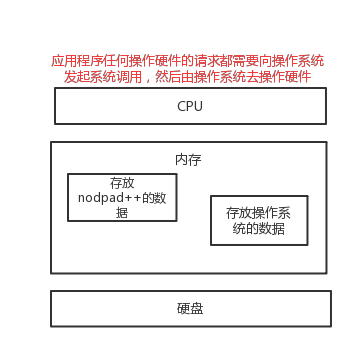
对于文件的读取,顺序应该是这样的。当我们使用应用程序想要执行某个程序时(就是一堆数据,二进制代码),都是先向操作系统发出请求,再让操作系统取调用硬件的功能。字符编码就是把机器语言的二进制(0,1)对应成我们人类能看懂的各种字符,这样就形成了字符编码的形式。
计算机要想工作必须通电,即用‘电’驱使计算机干活,也就是说‘电’的特性决定了计算机的特性。电的特性即高低电平(人类从逻辑上将二进制数1对应高电平,二进制数0对应低电平),关于磁盘的磁特性也是同样的道理。结论:计算机只认识数字 很明显,我们平时在使用计算机时,用的都是人类能读懂的字符(用高级语言编程的结果也无非是在文件内写了一堆字符),如何能让计算机读懂人类的字符? 必须经过一个过程: #字符--------(翻译过程)------->数字 #这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码
字符编码的发展可分为三个阶段
1、在存入磁盘时,需要将unicode转成一种更为精准的格式,utf-8:全称Unicode Transformation Format,将数据量控制到最精简
2、在读入内存时,需要将utf-8转成unicode
所以我们需要明确:内存中用unicode是为了兼容万国软件,即便是硬盘中有各国编码编写的软件,unicode也有相对应的映射关系,但在现在的开发中,程序员普遍使用utf-8编码了,估计在将来的某一天等所有老的软件都淘汰掉了情况下,就可以变成:内存utf-8<->硬盘utf-8的形式了。
最后总结
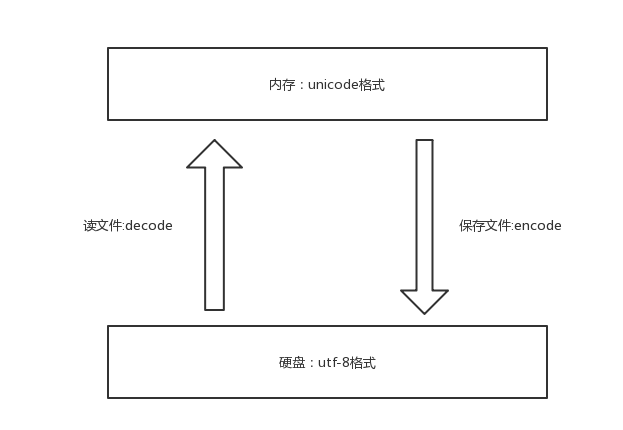
保证不乱吗的核心法则就是,字符按照什么标准而编码的,就要按照什么标准解码,此处的标准指的就是字符编码。
在内存中写的所有字符,一视同仁,都是unicode编码,比如我们打开编辑器,输入一个“你”,我们并不能说“你”就是一个汉字,此时它仅仅只是一个符号,该符号可能很多国家都在使用,根据我们使用的
输入法不同这个字的样式可能也不太一样。只有在我们往硬盘保存或者基于网络传输时,才能确定”你“到底是一个汉字,还是一个日本字,这就是unicode转换成其他编码格式的过程了。
unicode----->encode-------->utf-8
utf-8-------->decode---------->unico补充:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器
如果服务端encode的编码格式是utf-8, 客户端内存中收到的也是utf-8编码的结果。
关于python的字符编码问题
执行python程序的三个阶段:
阶段一:启动python解释器
阶段二:python解释器此时就是一个文本编辑器,负责打开文件test.py,即从硬盘中读取test.py的内容到内存中
阶段三:读取已经加载到内存的代码(unicode编码格式),然后执行,执行过程中可能会开辟新的内存空间,比如x="tao"
当python解释器执行到产生字符串的代码时(例如s=u'林'),会申请新的内存地址,然后将'林'以unicode的格式存放到新的内存空
间中,所以s只能encode,不能decode
字符编码文件头的作用
通常我们在pycharm进行编程的时,都会在开头打印#conding:UTF-8,这个就是文件头,但这不是绝对的,你可以选择任意的
字符编码,但为了有个规范我们通常都是以UTF-8作为文件头,这也是pycharm默认的编码。
下面我讲一下编码和解码:
编码的顺序是: unicod===>encode(编码)===>gbk
解码的顺序是:unicod===>decode===>gbk
文件处理
文件这种概念其实并不存在,只是人们为了便于区分的一种自定义的模式。操作系统把复杂的硬件操作封装成简单的接口给用户/应用程序
使用,其中文件就是操作系统提供给应用程序来操作硬盘虚拟概念,用户或应用程序通过操作文件,可以将自己的数据永久保存下来。
对于文件的处理,这里要用到我们之前所学习的变量,把文件路径定义成一个变量的形式存在来进行处理。
#1. 打开文件,得到文件句柄并赋值给一个变量
f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r
#2. 通过句柄对文件进行操作
data=f.read()
#3. 关闭文件
f.close()
这里有一个重点就是资源回收,其实我们打开一个文件是出现了两次操作,一次是应用程序和操作系统上,应用程序我们可以不用管,这个会
自动清理,但操作系统上打开了之后一定要记得回收。
#强调第一点:
打开一个文件包含两部分资源:操作系统级打开的文件+应用程序的变量。在操作完毕一个文件时,必须把与该文件的这两部分资源一个不落地回收,回收方法为:
1、f.close() #回收操作系统级打开的文件
2、del f #回收应用程序级的变量
其中del f一定要发生在f.close()之后,否则就会导致操作系统打开的文件还没有关闭,白白占用资源,
而python自动的垃圾回收机制决定了我们无需考虑del f,这就要求我们,在操作完毕文件后,一定要记住f.close()
虽然我这么说,但是很多同学还是会很不要脸地忘记f.close(),对于这些不长脑子的同学,我们推荐傻瓜式操作方式:使用with关键字来帮我们管理上下文
with open('a.txt','w') as f:
pass
with open('a.txt','r') as read_f,open('b.txt','w') as write_f:
data=read_f.read()
write_f.write(data)
强调第一点:资源回收
f=open(...)是由操作系统打开文件,那么如果我们没有为open指定编码,那么打开文件的默认编码很明显是操作系统说了算了,操作系统会用自己的默认编码去打开文件,在windows下是gbk,在linux下是utf-8。
这就用到了上节课讲的字符编码的知识:若要保证不乱码,文件以什么方式存的,就要以什么方式打开。
f=open('a.txt','r',encoding='utf-8')
关于文本有三种模式
r 只读模式【默认模式,文件必须存在,不存在则抛出异常】
w只写模式【不可读;不存在则创建;存在则清空内容】
a 之追加写模式【不可读;不存在则创建;存在则只追加内容】
如何操作使用文件
f.read() #读取所有内容,光标移动到文件末尾
f.readline() #读取一行内容,光标移动到第二行首部
f.readlines() #读取每一行内容,存放于列表中
f.write('1111
222
') #针对文本模式的写,需要自己写换行符
f.write('1111
222
'.encode('utf-8')) #针对b模式的写,需要自己写换行符
f.writelines(['333
','444
']) #文件模式
f.writelines([bytes('333
',encoding='utf-8'),'444
'.encode('utf-8')]) #b模式
文件的修改
文件的数据是存放于硬盘上的,因而只存在覆盖、不存在修改这么一说,我们平时看到的修改文件,都是模拟出来的效果,具体的说有两种实现方式:
方式一:将硬盘存放的该文件的内容全部加载到内存,在内存中是可以修改的,修改完毕后,再由内存覆盖到硬盘(word,vim,nodpad++等编辑器)