以下仅为自己的整理记录,绝大部分参考来源:莫烦Python,建议去看原博客
一、处理结构

因为TensorFlow是采用数据流图(data flow graphs)来计算, 所以首先我们得创建一个数据流流图, 然后再将我们的数据(数据以张量(tensor)的形式存在)放在数据流图中计算. 节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组, 即张量(tensor). 训练模型时tensor会不断的从数据流图中的一个节点flow到另一节点, 这就是TensorFlow名字的由来.
Tensor 张量意义
张量(Tensor):
- 张量有多种. 零阶张量为 纯量或标量 (scalar) 也就是一个数值. 比如
[1] - 一阶张量为 向量 (vector), 比如 一维的
[1, 2, 3] - 二阶张量为 矩阵 (matrix), 比如 二维的
[[1, 2, 3],[4, 5, 6],[7, 8, 9]] - 以此类推, 还有 三阶 三维的 …
二、使用Tensorflow创建一个线性回归的模型
创建数据
加载 tensorflow 和 numpy 两个模块, 并且使用 numpy 来创建我们的数据.
import tensorflow as tf import numpy as np # create data x_data = np.random.rand(100).astype(np.float32) y_data = x_data*0.1 + 0.3
用 tf.Variable 来创建描述 y 的参数. 我们可以把 y_data = x_data*0.1 + 0.3 想象成 y=Weights * x + biases, 然后神经网络也就是学着把 Weights 变成 0.1, biases 变成 0.3.
搭建模型
Weights = tf.Variable(tf.random_uniform([1], -1.0, 1.0)) biases = tf.Variable(tf.zeros([1])) y = Weights*x_data + biases
计算误差
计算 y 和 y_data 的误差:
tf.reduce_mean:求平均值; tf.square求平方
loss = tf.reduce_mean(tf.square(y-y_data))
传播误差
反向传递误差的工作就教给optimizer(优化器)了, 我们使用的误差传递方法是梯度下降法: Gradient Descent 让后我们使用 optimizer 来进行参数的更新.
tf.train.GradientDescentOptimizer 实现梯度下降算法的优化器 0.5代表学习率
参考链接:优化器Optimizer
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
训练
到目前为止, 我们只是建立了神经网络的结构, 还没有使用这个结构. 在使用这个结构之前, 我们必须先初始化所有之前定义的Variable, 所以这一步是很重要的!
# init = tf.initialize_all_variables() # tf 马上就要废弃这种写法 init = tf.global_variables_initializer() # 替换成这样就好
接着,我们再创建会话 Session. 用 Session 来执行 init 初始化步骤. 并且, 用 Session 来 run 每一次 training 的数据. 逐步提升神经网络的预测准确性.
sess = tf.Session() sess.run(init) # Very important for step in range(201): sess.run(train) if step % 20 == 0: print(step, sess.run(Weights), sess.run(biases))
全部代码:
import numpy as np import tensorflow as tf # creat data x_data = np.random.rand(100).astype(np.float32) y_data = 0.1 * x_data + 0.3 ''' tf.Variable 来创建描述 y 的参数. 我们可以把 y_data = x_data*0.1 + 0.3 想象成 y=Weights * x + biases, 然后神经网络也就是学着把 Weights 变成 0.1, biases 变成 0.3 ''' weights = tf.Variable(tf.random_uniform([1], -1, 1)) biases = tf.Variable(tf.zeros([1])) y = weights * x_data + biases # 计算误差 loss = tf.reduce_mean(tf.square(y - y_data)) # 反向传递误差的工作就教给optimizer了, 我们使用的误差传递方法是梯度下降法: Gradient Descent 让后我们使用 optimizer 来进行参数的更新 optimizer = tf.train.GradientDescentOptimizer(0.5) train = optimizer.minimize(loss) # 到目前为止, 我们只是建立了神经网络的结构, 还没有使用这个结构. 在使用这个结构之前, 我们必须先初始化所有之前定义的Variable # init = tf.initialize_all_variables() # tf 马上就要废弃这种写法 init = tf.global_variables_initializer() # 创建会话 Session,用 Session 来执行 init 初始化步骤. 并且, 用 Session 来 run 每一次 training 的数据. 逐步提升神经网络的预测准确性. sess = tf.Session() sess.run(init) # very import for step in range(201): sess.run(train) if step % 20 == 0: print(step, sess.run(weights), sess.run(biases))
sess.close()
# with tf.Session() as sess:
# sess.run(init) # very import
#
# for step in range(201):
# sess.run(train)
# if step % 20 == 0:
# print(step, sess.run(weights), sess.run(biases))
三、Session会话控制
Session 是 Tensorflow 为了控制,和输出文件的执行的语句. 运行 session.run() 可以获得你要得知的运算结果, 或者是你所要运算的部分.
下面代码是为了输出两个矩阵相乘的结果
因为 product 不是直接计算的步骤, 所以我们会要使用 Session 来激活 product 并得到计算结果. 有两种形式使用会话控制 Session 。
第二种形式类似于Python对于文件的操作,用with控制,可以避免“忘记关闭session”
import tensorflow as tf # create two matrixes matrix1 = tf.constant([[3,3]]) matrix2 = tf.constant([[2], [2]]) product = tf.matmul(matrix1,matrix2) # method 1 sess = tf.Session() result = sess.run(product) print(result) sess.close() # [[12]] # method 2 with tf.Session() as sess: result2 = sess.run(product) print(result2) # [[12]]
四、Variable 变量
在 Tensorflow 中,定义了某字符串是变量,它才是变量,这一点是与 Python 所不同的。
定义语法: state = tf.Variable()
tf.Variable.init(initial_value, trainable=True, collections=None, validate_shape=True, name=None)
参数名称 : 参数类型 :含义
initial_value :所有可以转换为Tensor的类型 :变量的初始值
trainable: bool :如果为True,会把它加入到GraphKeys.TRAINABLE_VARIABLES,才能对它使用Optimizer
collections: list :指定该图变量的类型、默认为[GraphKeys.GLOBAL_VARIABLES]
validate_shape :bool :如果为False,则不进行类型和维度检查
name :string :变量的名称,如果没有指定则系统会自动分配一个唯一的值
虽然有一堆参数,但只有第一个参数initial_value是必需的
参考链接:TensorFlow图变量tf.Variable的用法解析
定义常量:one = tf.constant(1)
assign函数用于给图变量赋值
import tensorflow as tf state = tf.Variable(0, name='counter') # 定义常量 one one = tf.constant(1) # 定义加法步骤 (注: 此步并没有直接计算) new_value = tf.add(state, one) # 将 State 更新成 new_value update = tf.assign(state, new_value)
如果你在 Tensorflow 中设定了变量,那么初始化变量是最重要的!!所以定义了变量以后, 一定要定义 init = tf.initialize_all_variables() .
到这里变量还是没有被激活,需要再在 sess 里, sess.run(init) , 激活 init 这一步
# 如果定义 Variable, 就一定要 initialize # init = tf.initialize_all_variables() # tf 马上就要废弃这种写法 init = tf.global_variables_initializer() # 替换成这样就好 # 使用 Session with tf.Session() as sess: sess.run(init) for _ in range(3): sess.run(update) print(sess.run(state))
注意:直接 print(state) 不起作用!!
一定要把 sess 的指针指向 state 再进行 print 才能得到想要的结果!
五、Placeholder 传入值
placeholder 是 Tensorflow 中的占位符,暂时储存变量.
Tensorflow 如果想要从外部传入data, 那就需要用到 tf.placeholder(), 然后以这种形式传输数据 sess.run(***, feed_dict={input: **}).
传值的工作交给了 sess.run() , 需要传入的值放在了feed_dict={} 并一一对应每一个 input. placeholder 与 feed_dict={} 是绑定在一起出现的。
import tensorflow as tf #在 Tensorflow 中需要定义 placeholder 的 type ,一般为 float32 形式 input1 = tf.placeholder(tf.float32) input2 = tf.placeholder(tf.float32) # mul = multiply 是将input1和input2 做乘法运算,并输出为 output ouput = tf.multiply(input1, input2) with tf.Session() as sess: print(sess.run(ouput, feed_dict={input1: [7.], input2: [2.]})) # [ 14.]
六、激励函数
我们可以把整个网络简化成这样一个式子. Y = Wx, W 就是我们要求的参数, y 是预测值, x 是输入值. 用这个式子, 我们很容易就能描述线性问题
对于非线性问题,AF 就是指的激励函数,它其实就是另外一个非线性函数. 比如说relu, sigmoid, tanh. 将这些掰弯利器嵌套在原有的结果之上, 强行把原有的线性结果给扭曲了. 使得输出结果 y 也有了非线性的特征.
甚至可以创造自己的激励函数来处理自己的问题, 不过要确保的是这些激励函数必须是可以微分的, 因为在 backpropagation 误差反向传递的时候, 只有这些可微分的激励函数才能把误差传递回去.
激励函数运行时激活神经网络中某一部分神经元,将激活信息向后传入下一层的神经系统。激励函数的实质是非线性方程。 Tensorflow 的神经网络 里面处理较为复杂的问题时都会需要运用激励函数 activation function

激励函数的选择
参考链接:ML激活函数使用法则
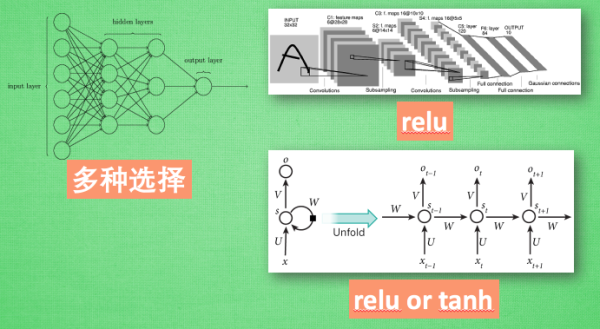
想要恰当使用这些激励函数, 还是有窍门的. 比如当你的神经网络层只有两三层, 不是很多的时候, 对于隐藏层, 使用任意的激励函数, 随便掰弯是可以的, 不会有特别大的影响. 不过, 当你使用特别多层的神经网络, 在掰弯的时候, 玩玩不得随意选择利器. 因为这会涉及到梯度爆炸, 梯度消失的问题.
首选的激励函数:在少量层结构中, 我们可以尝试很多种不同的激励函数. 在卷积神经网络 Convolutional neural networks 的卷积层中, 推荐的激励函数是 relu. 在循环神经网络中 recurrent neural networks, 推荐的是 tanh 或者是 relu
参考链接:ML激活函数使用法则