参考博客:https://www.cnblogs.com/guoyaohua/p/8724433.html
参考知乎:https://www.zhihu.com/question/38102762/answer/85238569
1.BN的原理
我们知道,神经网络在训练的时候,如果对图像做白化(即通过变换将数据变成均值为0,方差为1)的话,训练效果就会好。那么BN其实就是做了一个推广,它对隐层的输出也做了归一化的操作。那么为什么归一化操作能够使得训练效果好那么多呢?机器学习领域有个很重要的假设:IID独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。假设我们用批量梯度下降法来训练,在没有BN层之前,你对输入做了白化,对于每一个batch在喂到神经网络之前分布是一致的,但是通过每一个隐层的激活函数后,每一个batch的隐层输出分布可能就有很大差异了,而且随着层数的加深,这种差异也会越来越大。
2.BN的公式表达

下面具体解释一下上述公式的意思:前三步的作用就是把输入数据分布归一化成一个正态分布,这样一来,每一个隐藏层未经激活的输出值经过激活函数之后大部分都落在了激活函数的线性区域(参考sigmoid函数),但是由于神经网络强大的表达能力就是基于它的高度非线性化,如果这种特性失去了,网络在再深也没有用了。原作者采取了一个办法,就是第四步,这个步骤其实就是将正太分布进行一个偏移(scale and shift),从某种意义上来说,就是在线性和非线性之间做一个权衡,而这个偏移的参数gamma和bata是神经网络在训练时学出来的。另外提一下,公式3中的eplison应该是一个很小的正数,为了防止分母为0,tensorflow的源码是这样解释的。
3.BN的参数推导
现在我们看下,如何通过链式法则更新BN中的参数(其中![]() 就相当于之前的传播误差
就相当于之前的传播误差![]() ):
):

4.BN在实际运用中需要注意的问题 (此处参考博客:https://blog.csdn.net/xys430381_1/article/details/85141702 )
当我们的测试样本前向传导的时候,上面的均值u、标准差σ要哪里来?其实网络一旦训练完毕,参数都是固定的,这个时候即使是每批训练样本进入网络,那么BN层计算的均值u、和标准差σ都是固定不变的。我们可以采用这些训练阶段的均值u、标准差σ来作为测试样本所需要的均值、标准差,于是最后测试阶段的u和σ计算公式如下:
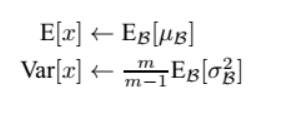
上面简单理解就是:对于均值来说直接计算所有batch u值的平均值;然后对于标准偏差采用每个batch σB的无偏估计。最后测试阶段,BN的使用公式就是:
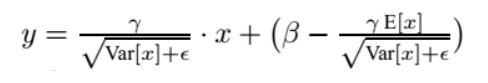
也就是说, 在test的时候,BN用的是固定的mean和var, 而这个固定的mean和var是通过训练过程中对mean和var进行滑动平均得到的,被称之为moving_mean和moving_var。在实际操作中,每次训练时应当更新一下moving_mean和moving_var,然后把BN层的这些参数保存下来,留作测试和预测时使用。(如果不太了解滑动平均可以参考博文:https://blog.csdn.net/qq_18888869/article/details/83009504)
5.BN的好处(此处参考知乎:https://www.zhihu.com/question/38102762中龙鹏-言有三的回答)
(1) 减轻了对参数初始化的依赖,这是利于调参的朋友们的。
(2) 训练更快,可以使用更高的学习率。
(3) BN一定程度上增加了泛化能力,dropout等技术可以去掉。
6.BN的缺陷
batch normalization依赖于batch的大小,当batch值很小时,计算的均值和方差不稳定。研究表明对于ResNet类模型在ImageNet数据集上,batch从16降低到8时开始有非常明显的性能下降,在训练过程中计算的均值和方差不准确,而在测试的时候使用的就是训练过程中保持下来的均值和方差。
由于这一个特性,导致batch normalization不适合以下的几种场景。
(1)batch非常小,比如训练资源有限无法应用较大的batch,也比如在线学习等使用单例进行模型参数更新的场景。
(2)rnn,因为它是一个动态的网络结构,同一个batch中训练实例有长有短,导致每一个时间步长必须维持各自的统计量,这使得BN并不能正确的使用。在rnn中,对bn进行改进也非常的困难。不过,困难并不意味着没人做,事实上现在仍然可以使用的,不过这超出了咱们初识境的学习范围。