打算法比赛有点累,比赛之余写点小项目来提升一下工程能力、顺便陶冶一下情操
本来是想买一个服务器写个博客或者是弄个什么翻墙的东西
最后刷知乎看到有一个很有意思的项目,就是维护一个「高可用低延迟的高匿IP代理池」
于是就想自己把这个项目写一次,其中有些更改,有些没有实现
(数据结构作业要写广义表,写项目时发现还没写 :)
原知乎链接:https://www.zhihu.com/question/47464143 (作者:resolvewang)
原项目github链接:https://github.com/SpiderClub/haipproxy
在此感谢原作者 resolvewang
本项目链接:https://github.com/TangliziGit/proxypool
项目早已在服务器上运行,这篇随笔就是未完待续吧
咕咕咕,鸽了
大体思路
- 用爬虫爬下网络上的免费代理ip
- 对爬取的代理ip进行验证,过滤掉一些不可用、低速的、有网页跳转的代理
- 编写调度器,对各个网站定时爬取、验证免费代理;并对数据库中以爬取的代理进行验证
- 写一个web api,提供数据库中已有的代理ip
大体框架
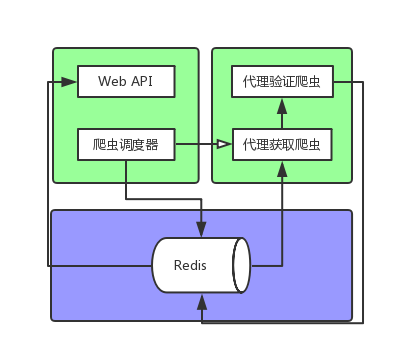
(我就只是想画个图而已 -_-)
项目第一阶段目录:
proxypool/
├── booter.py
├── dump.rdb
├── place.txt
├── proxypool
│ ├── __init__.py
│ ├── items.py
│ ├── logger.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── rules.py
│ ├── settings.py
│ ├── spiders
│ │ ├── base_spider.py
│ │ ├── common_spider.py
│ │ ├── __init__.py
│ │ └── __pycache__
│ ├── task_queue.py
│ ├── user_agent.py
│ └── validators
│ ├── baidu_validator.py
│ ├── base_validator.py
│ ├── __init__.py
│ ├── __pycache__
│ └── zhihu_validator.py
├── __pycache__
├── scheduler.py
├── scrapy.cfg
└── testip.py
7 directories, 24 files
// wc -l `find . -name "*.py"`
5 ./booter.py
119 ./proxypool/middlewares.py
5 ./proxypool/spiders/common_spider.py
67 ./proxypool/spiders/base_spider.py
9 ./proxypool/spiders/__init__.py
7 ./proxypool/logger.py
91 ./proxypool/settings.py
11 ./proxypool/user_agent.py
86 ./proxypool/rules.py
57 ./proxypool/task_queue.py
7 ./proxypool/validators/zhihu_validator.py
7 ./proxypool/validators/baidu_validator.py
56 ./proxypool/validators/base_validator.py
5 ./proxypool/validators/__init__.py
55 ./proxypool/pipelines.py
21 ./proxypool/items.py
0 ./proxypool/__init__.py
59 ./scheduler.py
667 total
细节描述
爬虫部分
数据流向
RedisTaskQueue获取链接
Spider发出请求
RandomUserAgentMiddware换UA
通过规则解析response
送至RedisRawProxyPipeline,未处理数据存入数据库
- 爬取规则的编写
很多免费代理网站的结构都很相似,基本上就是这样的(取自西刺代理):
<tr class="odd">
<td class="country"><img src="http://fs.xicidaili.com/images/flag/cn.png" alt="Cn" /></td>
<td>223.240.209.18</td>
<td>18118</td>
<td>安徽合肥</td>
<td class="country">高匿</td>
<td>HTTP</td>
<td>1分钟</td>
<td>不到1分钟</td>
</tr>
<tr class="">
<td class="country"><img src="http://fs.xicidaili.com/images/flag/cn.png" alt="Cn" /></td>
<td>183.23.73.49</td>
<td>61234</td>
<td>广东东莞</td>
<td class="country">高匿</td>
<td>HTTPS</td>
<td>1小时</td>
<td>不到1分钟</td>
</tr>
...
通过编写爬取规则,我们就可以很方便爬取多个网站:
RULES = {
"xici" : {
"parser_type": "page",
"prefix": "//tr",
"detail": "td/text()",
...
}
}
然后就可以类似这样做请求:
[x.xpath(rule["detail"]) for x in response.xpath(rule["prefix"])]
-
设计RedisTaskQueue类,让爬虫从中取得要爬取的网站
为啥不让爬虫自己从数据库里取任务呢?
呃 这个本来是为了多进程做的考虑,但是发现scrapy的Spider已经满足时间上的需求了
考虑到以后可能需要这个类来让调度器调度爬虫,于是就留下来了 -
设计基本爬虫BaseSpider
主要是以后用来做爬虫种类的拓展,比如这个网页可能会用js做个动态加载
后续就要考虑到编写JsSpider(BaseSpider)
目前只有一个爬虫CommonSpider(BaseSpider),用来爬普通网页(普通网页或json) -
Scrapy框架方面
RawProxyUrlItem, ProxyUrlItem
RandomUserAgentMiddleware, TimerMiddleware
RedisRawProxyPipeline, RedisProxyPipeline
验证部分
数据流向
RedisProxyQueue获取ip
Spider发出验证请求
TimerMiddleware开始计时
TimerMiddleware结束计时
通过规则验证response
验证通过,送至RedisRawProxyPipeline,验证后ip存入数据库
-
验证规则
与爬取规则相同,我们可选许多网站来做验证(每个代理对各网站有不同的效率)
为了方便管理,写验证规则
为什么要验证?
一是为了保证代理速度
二是为了保证不会存在“调包”的情况(中间人偷偷改了回复) -
代理记分方式
简单的用请求时间来作为分数,存入Redis的有序集合
数据库部分
| 数据项 | 描述 |
|---|---|
| ProxyPool:RAW_IPPOOL | 集合 存储未验证ip |
| ProxyPool:IPPOOL | 有序集合 存储验证通过ip 按分数排序 |
| ProxyPool:TASK_QUEUE | 调度器暂时存入请求链接 |
调度器部分
这部分未完待续
仅仅写了获取爬虫和验证爬虫的简单启动
下一步是根据爬取规则的时间间隔来调度
WebAPI部分
这部分根本还没写
不过这是项目里最简单的东西
准备适当时间入一个服务器,用Flask简单写一写就好了
总结要点
- 在项目里专门写一个配置文件,用以配置工程内所有信息,避免hardcode
- 未来可能需要更多相似的类时,编写基类是必须的,考虑到方便编写和复用性
- 给类中添加某一功能时,如果项目较复杂,写Mixin合适一点
- 若对大量(或后续可能大量)的网站做爬取时,最好抽象出爬取规则,便于处理添加更多爬取网站、更改爬取数据顺序等
- 验证代理ip,考虑代理速度和中间人“调包”的可能
- 使用无表的数据库(such as Redis)时,为了结构清晰,将键值写成"XXX:A:B"的形式
实现细节&需要注意的
- 每一个scrapy.Spider里可以自定义设置
- 比如设置pipeline, middleware, DOWNLOAD_DELAY
custom_settings = {
'DOWNLOAD_TIMEOUT': 1,
'CONCURRENT_REQUESTS': 50,
'CONCURRENT_REQUESTS_PER_DOMAIN': 50,
'RETRY_ENABLED': False,
'DOWNLOADER_MIDDLEWARES': {
'proxypool.middlewares.TimerMiddleware': 500,
},
'ITEM_PIPELINES': {
'proxypool.pipelines.RedisProxyPipeline': 200,
}
}
- Python取数据库的数据后,要看看是不是byte类型
- scrapy.Request包括errback, dont_filter等很有用的参数
- scrapy通过CrawlerProcess方法不能重复启动爬虫,如有需要,用多进程即可
**未完待续**