推荐系统介绍
一、推荐系统的应用场景
推荐系统在我们的日常生活中无出不在。想要了解资讯时,推荐系统会为你准备你感兴趣的新闻;想要看电影时,推荐系统会为你挑选让你满意的电影;想要购物时,推荐系统会为你找到你需要的商品;想要学习时,推荐系统会为你精心挑选你最需要的课程;想要休闲娱乐时,推荐系统会为你推荐最应景的音乐;想要玩游戏时,推荐系统会为你找到你热爱的游戏。推荐系统充斥着我们的生活,让我们的生活更加高效与惬意。
二、推荐系统的作用和意义
推荐系统存在的作用和意义可以从用户和公司两个角度进行阐述。
- 用户角度:推荐系统解决在“信息过载”的情况下,用户如何高效获得感兴趣信息的问题。从理论上讲,推荐系统并不仅限于互联网。但互联网带来的海量信息问题,往往会导致用户迷失在信息中无法找到目标内容。可以说,互联网是推荐系统应用的最佳场景。从用户需求层面看,推荐系统是在用户需求并不十分明确的情况下进行信息的过滤,因此,与搜索系统(用户会输入明确的“搜索词”)相比,推荐系统更多地利用用户的各类历史信息“猜测”其可能喜欢的内容,这是解决推荐问题是必须注意的基本场景假设。
- 公司角度:推荐系统解决产品能够最大限度地吸引用户、留存用户、增加用户粘性、提高用户转化率的问题,从而达到公司商业目标连续增长的目的。不同业务模式的公司定义的具体推荐系统优化目标不同。例如,视频类公司更注重用户观看时长,电商类公司更注重用户的购买转化率(Conversion Rate,CVR),新闻类公司更注重用户的点击率,等等。需要注意的是,设计推荐系统的最终目标是达成公司的商业目标、增加公司收益,这应是推荐工程师站在公司角度考虑问题的出发点
正因为如此,推荐系统不仅是用户高效获取感兴趣内容的“引擎”,也是互联网公司达商业目标的引擎,而这时一个问题的两个维度,是相辅相成的。
三、推荐系统的架构
- 推荐系统的逻辑架构
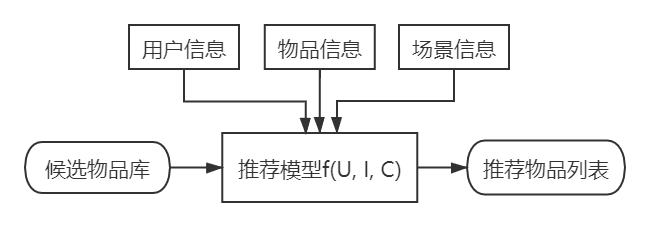
在获知“用户信息”、”物品信息“、”场景信息“的基础上,推荐系统要处理的问题可以较形式化的定义为:对于用户U(User),在特定场景C(Context)下,针对海量的“物品”信息,构建一个函数f(U, I, C),预测用户对特定候选物品I(Item)的喜好程度,再根据喜好程度对所有候选物品进行排序,生成推荐列表的问题。
根据推荐系统问题的定义,可以得到抽象的推荐系统逻辑框架(如图1.1)。虽然该逻辑框架是概括性的,但正是在此基础上,对各模块进行细化和扩展,才产生了推荐系统的整个技术体系。
- 推荐系统的技术架构
在实际的推荐系统中,工程师需要将抽象的概念和模块具体化、工程化。在图1.1的基础上,工程师需要着重解决的问题有两类。
- 数据和信息相关的问题,即“用户信息”、“物品信息”、“场景信息”分别是什么?如何存储、更新和处理?
- 推荐系统算法和模型相关的问题,即模型如何训练、如何预测、如何达成更好的推荐效果?
可以将这两类问题分为两个部分:“数据和信息”部分逐渐发展为推荐系统中融合了数据离线批处理、实时流处理的数据流框架;“算法和模型”部分则进一步细化为推荐系统中集训练、评估、部署、线上推断为一体的模型框架。推荐系统的技术架构示意图如图1.2所示。

推荐系统的数据部分主要负责用户、物品、场景的信息收集与处理。具体地讲,将负责数据收集与处理的三种平台按照实时性的强弱排序,依次为客户端及服务器实时数据处理、流处理平台准实时数据处理、大数据平台离线数据处理。在实时性由强到弱递减的同时,三种平台的海量数据处理能力则由弱到强。因此,一个成熟的推荐系统的数据流系统会将三者取长补短,配合使用。
在得到原始的数据信息后,推荐系统的数据处理系统会将原始数据进一步加工,加工后的数据出口主要有三个:
- 生成推荐模型所需的样本数据,用于模型的训练和评估。
- 生成推荐模型服务(model serving)所需的“特征”,用于推荐系统的线上推断。
- 生成系统监控、商业智能(Business Intelligence, BI)系统所需的统计型数据。
推荐系统的模型部分是推荐系统的主体。模型的结构一般由“召回层”、“排序层”、“补充策略与算法层”组成。
召回层一般利用高效的召回规则、算法或简单的模型,快速从海量的候选 集中召回用户可能感兴趣的物品。
排序层利用排序模型对初筛的候选集进行精排序。
补充策略与算法层,也被称为再排序层,可以在将推荐列表返回用户之前,为兼顾结果的多样性、流行度、新鲜度等指标,结合一些补充的策略和算法对推荐列表进行一定的调整,最终形成用户可见的推荐列表。
从推荐模型接收到所有候选物品集,到最后产生推荐列表,这一过程一般称为模型服务过程。
在线环境进行模型服务之前,需要通过模型训练(model training)确定模型结构、结构中不同参数权重的具体数值,以及模型相关算法和策略中的参数取值。模型的训练方法又可以根据模型训练环境的不同,分为离线训练和在线更新两部分,其中:离线训练的特点是可以利用全量样本和特征,使模型逼近全局最优点;在线更新则可以准实时地消化新的数据样本,更快的反映新的数据变化趋势,满足模型实时性的需求。
除此之外,为了评估推荐模型的效果,方便模型的迭代优化,推荐系统的模型部分提供了离线评估和线上A/B测试等多种评估模块,用得出的线下和线上评估指标,指导下一步的模型迭代优化。
以上所有模块共同组成了推荐系统模型部分的技术框架。模型部分,特别是排序层模型是推荐系统产生效果的重点,也是业界和学界研究的重心。
四、深度学习对推荐系统的革命性贡献
深度学习对推荐系统的革命性贡献在于对推荐模型部分的改进。与传统的推荐模型相比,深度学习模型对数据模式的拟合能力和对特征组合的挖掘能力更强。此外,深度学习模型结构的灵活性,使其能够根据不同推荐场景调整模型,使之与特定业务数据完美契合。
与此同时,深度学习对海量训练数据及数据实时性的要求,也对推荐系统的数据流部分提出了新的挑战。如何尽量做到海量数据的实时处理、特征的实时提取,线上模型服务过程的数据实时获取,是深度学习推荐系统数据部分需要攻克的难题。