3.2 程序编码
> gcc -Og -o p p1.c p2.c
编译选项 -Og 告诉编译器使用会生成符合原始 C 代码整体结构的机器代码的优化等级。使用较
髙级别优化产生的代码会严重变形,以至于产生的机器代码和初始源代码之间的关系非常难以理
解。
实际上 gcc 命令调用了一整套的程序,将源代码转化成可执行代码。首先,C 预处理器扩展源代
码,插人所有用 include 命令指定的文件,并扩展所有声明指定的宏。其次,编译器产生两个源
文件的汇编代码,名字分别为 pl.s 和 p2.s 接下来,汇编器会将汇编代码转化成二进制目标代码
文件 pl.o 和 p2.oÿ 目标代码是机器代码的一种形式,它包含所有指令的二进制表示,但是还没
有填入全局值的地址。最后,链接器将两个目标代码文件与实现库函数(例如 printf)的代码合并
,并产生最终的可执行代码文件 p (由命令行指示符-o p 指定的)。
3.2.2 代码示例
$ gcc -Og -S mstore.c
在命令行上使用 -S 选项,就能看到 C 语言编译器产生的汇编代码。这会使 GCC 运行编译器,产
生一个汇编文件 mstore.s 但是不做其他进一步的工作。
$ gcc -Og -c mstore.c
如果我们使用 -C 命令行选项,GCC 会编译并汇编该代码。这就会产生目标代码文件 mstore.o,
它是二进制格式的,所以无法直接査看。
要查看机器代码文件的内容,有一类称为反汇编器(disassembler)的程序非常有用。这些程序根
据机器代码产生一种类似于汇编代码的格式。在 Linux 系统中,带 -d 命令行标志的程序
OBJDUMP 可以充当这个角色:
# 对目标文件进行反汇编
$ objdump -d mstore.o
# 对可执行文件进行反汇编
$ objdump -d prog
# 对可执行文件进行反汇编,并把结果输出到 prog.txt 中
$ objdump -d prog > prog.txt
# Disassembly of section .init:
#
# 函数 _init
# 0804869c <_init>:
# 偏移量 所占字节数 等价的汇编语言指令
# 804869c: 55 push %ebp
# 804869d: 89 e5 mov %esp,%ebp
# 804869f: 83 ec 08 sub $0x8,%esp
# 80486a2: e8 0d 02 00 00 call 80488b4 <call_gmon_start>
# 80486a7: e8 64 02 00 00 call 8048910 <frame_dummy>
# 80486ac: e8 af 0e 00 00 call 8049560 <__do_global_ctors_aux>
# 80486b1: c9 leave
# 80486b2: c3 ret
反汇编器使用的指令命名规则与 GCC 生成的汇编代码使用的有些细微的差别。在我们的示例中,它省略了很多指令结尾的 q 这些后缀是大小指示符,在大多数情况中可以省略。相反,反汇编器给
call 和 ret 指令添加了 q 后缀,同样,省略这些后缀也没有问题。
3.2.3 关于格式的注释
.s 文件里包含的所有以 . 开头的行都是指导汇编器和链接器工作的伪指令。我们通常可以忽略这些行。另一方面,也没有关于指令的用途以及它们与源代码之间关系的解释说明。
// void multstore(long x, long y, long *dest)
// x in %rdi, y in %rsi, dest in %rdx
/*
* multstore:
* pushq %rbx Save %rbx
* moveq %rdx, %rbx Copy dest to %rbx
* call mult2 Call mult2(x, y)
* movq %rax, (%rbx) Store result at *dest
* popq %rbx Restore %rbx
* ret Return
*/
3.3 数据格式
由于是从 16 位体系结构扩展成 32 位的,Intel 用术语 字(word) 表示 16 位数据类
型。因此,称 32 位数为 双字(double words), 称 64 位数为 四字(quad words)。
/*
x86-x64 系统中,指针长 8 字节
-----------汇编代码后缀
char 1B b
short 2B w
int 4B l
double 4B l
float 4B s
long 8B q
char* 8B q
*/
大多数 GCC 生成的汇编代码指令都有一个字符的后缀,表明操作数的大小。例如,数据传送指令有
四个变种:movb(传送字节)、 movw(传送字)、 movl(传送双字)和 movq(传送四字)。后
缀 l 用来表示双字,因为 32 位数被看成是 长字(long word)注意,汇编代码也使用后缀 l
来表示 4 字节整数和 8 字节双精度浮点数。这不会产生歧义,因为浮点数使用的是一组完全不同
的指令和寄存器。
3.4 访问信息
一个 X86-64 的中央处理单元(CPU)包含一组 16 个存储 64 位值的通用目的寄存器。
这些寄存器用来存储整数数据和指针。它们的名字都以 %r 开头,不过后面还跟着一些不同的命名
规则的名字,这是由于指令集历史演化造成的。最初的 8086 中有 8 个 16 位的寄存器,即下图
中 %ax 到 %bp。 每个寄存器都有特殊的用途,它们的名字就反映了这些不同的用途。扩展到
IA32 架构时,这些寄存器也扩展成 32 位寄存器,标号从 %eax 到 %ebp。扩展到 x86-64 后,
原来的 8 个寄存器扩展成 64 位,标号从%rax 到 %rbx 除此之外,还增加了 8 个新的寄存器,
它们的标号是按照新的命名规则制定的:从 %r8 到 %r15。

指令可以对这 16 个寄存器的低位字节中存放的不同大小的数据进行操作。字节级操作可以访问最
低的字节,16 位操作可以访问最低的 2 个字节,32 位操作可以访问最低的 4 个字节,而 64 位
操作可以访问整个寄存器。
很多指令比如:复制和生成 1 字节、2 字节、4 字节和 8 字节值。当这些指令以寄存器作为目标
时,对于生成小于 8 字节结果的指令,寄存器中剩下的字节会怎么样? 对此有两条规则:
- 生成 1 字节和 2 字节数字的指令会保持剩下的字节不变;
- 生成 4 字节数字的指令会把髙位 4 个字节置为 0。
后面这条规则是作为从 IA32 到 X86-64 的扩展的一部分而采用的。
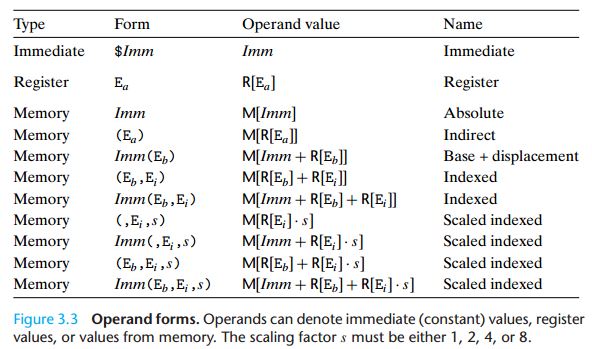
3.4.1 操作数指示符
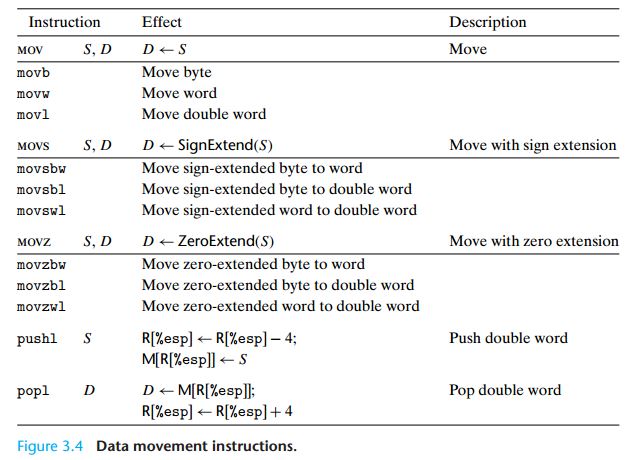
3.4.2 数据传送指令
3.4.4 压入和弹出数据
3.5 算术和逻辑操作
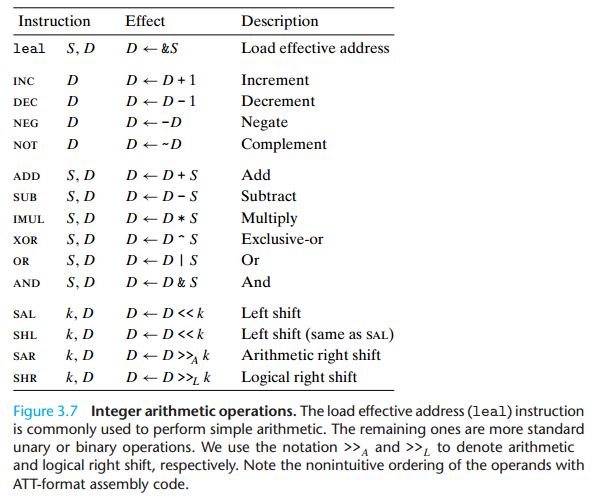
3.5.1 加载有效地址
加栽有效地址(load effective address)指令 leaq 实际上是 movq 指令的变形。它的指令形式是从内
存读数据到寄存器,但实际上它根本就没有引用内存。它的第一个操作数看上去是一个内存引用,但该指令并不是
从指定的位置读人数据,而是将有效地址写人到目的操作数。
如果寄存器 %rdx 的值为 x,那么指令 leaq 7(%rdx,%rdx,4) ,%rax 将设置寄存器 %rax 的值为
5x+7。编译器经常发现 leaq 的一些灵活用法,根本就与有效地址计算无关。目的操作数必须是一个寄存器。
3.6 控制
3.6.1 条件码
除了整数寄存器,CPU 还维护着一组单个位的条件码(condition code)寄存器,它们描述了最近的算术或逻辑操作的属性。可以检测这些寄存器来执行条件分支指令。最常用的条件码有:
CF: 进位标志。最近的操作使最高位产生了进位。可用来检査无符号操作的溢出。
ZF: 零标志。最近的操作得出的结果为 0。
SF: 符号标志。最近的操作得到的结果为负数。
OF: 溢出标志。最近的操作导致一个补码溢出—— 正溢出或负溢出。
除了 lea 指令,所有算术和逻辑操作都会设置条件码。
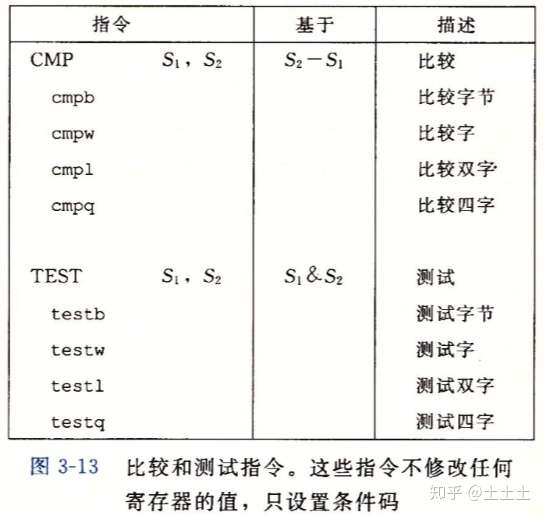
而下图中的 cmp 和 test 指令,只设置条件码而不改变任何其他寄存器。
cmp 指令根据两个操作数 之差来设置条件码。除了只设置条件码而不更新目的寄存器之外,cmp 指令与 sub 指令的行为是一样的。如果两个操作数相等,这些指令会将零标志设置为 1,而其他的标志可以用来确定两个操作数之间的大小关系。
test 指令的行为与 and 指令一样,除了它们只设置条件码 而不改变目的寄存器的值。test 指令的典型用法是:
-
两个操作数是一样的:例如,
testq %rax,%rax用来检查 %rax 是负数,零,还是正数。 -
其中的一个操作数是一个掩码:用来指示哪些位应该被测试。
3.6.1 访问条件码
条件码通常不会直接读取,常用的使用方法有三种:
-
可以根据条件码的某种组合,将一个字节设置为 0 或 1
-
可以条件跳转到程序的某个其他的部分
-
可以有条件地传送数据
对于情况 1,描述的指令根据条件码的某种组合,将一个字节设置为 0 或者 1。我们将这一整类指令称为 set 指令。它们之间的区别就在于它们考虑的条件码的组合是什么,这些指令名字的不同后缀指明了它们所考虑的条件码的组合。这些指令的后缀表示不同的条件而不是操作数大小,了解这一点很重要。例如,指令 setl 和 setb 表示 “小于时设置(set less)” 和 “低于时设置(set below)” 而不是 “设置长字(set long word)” 和 “设置字节(set byte)”。
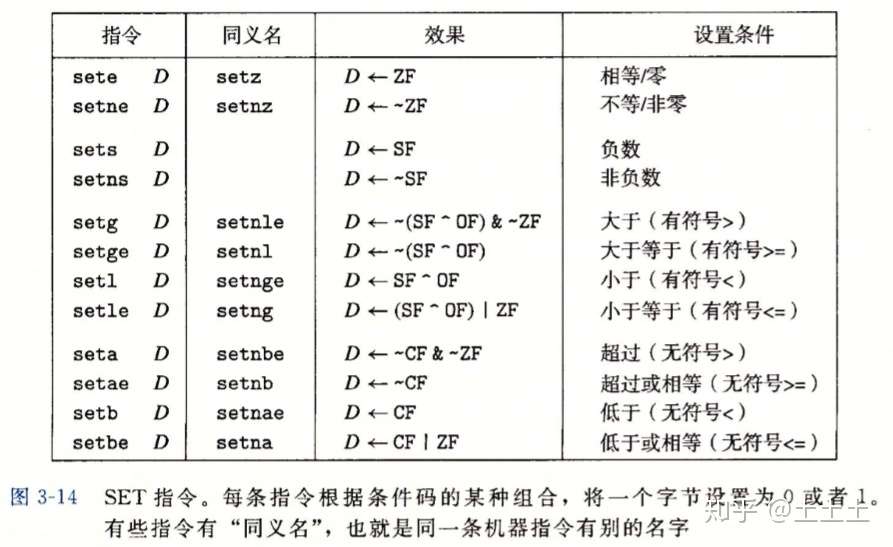
一条 set 指令的目的操作数是低位单字节寄存器元素之一(%XXl),或是一个字节的内存位置,指令会将这个字节设置成 0 或者 1。为了得到一个 32 位或 64 位结果,我们必须对高位清零。
一个计算 C 语言表达式 a< b 的典型指令序列如下所示,这里 a 和 b 都是
long 类型:
int comp(data_t a, data_t b)
a in %rdi, b in %rsi
comp:
cmpq %rsi, %rdi Compare a:b
setl %al Set low-order byte of %eax to 0 or 1
movzbl %al, %eax Clear rest of %eax (and rest of %rax)
ret
注意 cmpq 指令的比较顺序。 虽然参数列出的顺序先是 %rsi(b) 再是 %rdi(a), 实际上比较的是 a 和 b。还要记得,movzbl 指令不仅会把 %eax 的高 3 个字节清零,还会把整个寄存器 %rax 的高 4 个字节都清零。
3.6.3 跳转指令
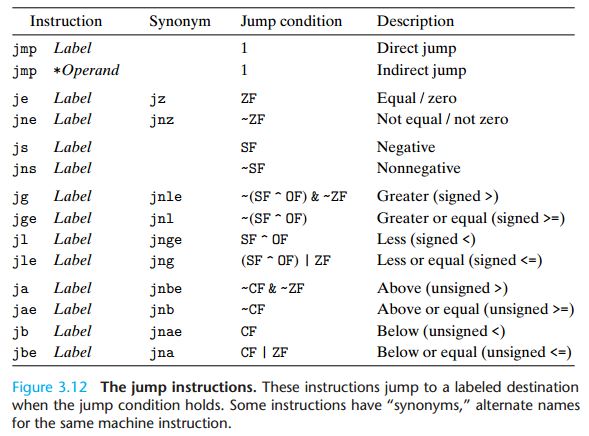
3.6.8 switch 语句
switch 语句里有个奇怪的跳转指令:
jmp *0x4005c3(, %rsi, 8) Go to *gt[index]
这条语句是在选择跳转到哪个分支。
switch 语句可以根据一个整数索引值进行多重分支(multiway branching) 在处理具有多种可能结果的测试时,这种语句特别有用。它们不仅提高了 C 代码的可读性,而且通过使用跳转表 (jump table) 这种数据结构使得实现更加高效。跳转表是一个数组,表项 i 是一个代码段的地址,这个代码段实现当开关索引值等于时程序应该采取的动作。程序代码用开关索引值来执行一个跳转表内的数组引用,确定跳转指令的目标。
和使用一组很长的 if-else 语句相比,使用跳转表的优点是执行开关语句的时间与开关情况的数量无关。GCC 根据开关情况的数量和开关情况值的稀疏程度来 翻译开关语句。当开关情况数量比较多(例如 4 个以上),并且值的范围跨度比较小时,就会使用跳转表。
原始的 C 代码有针对值 100、102-104 和 106 的情况,但是开关变量 n 可以是任意整数。编译器首先将 n 减去 100, 把取值范围移到 0 和 6 之间,创建一个新的程序变量:index, 补码表示的负数会映射成无符号表示的大正数,利用这一事实,将 index 看作无符号值,从而进一步简化了分支的可能性。因此可以通过测试 index 是否大于 6 来判定index 是否在 0-6 的范围之外。
执行 switch 语句的关键步骤是通过跳转表来访问代码位置。语句引用了跳转表 jt。 GCC 支持计算 goto (computed goto),是对 C 语言的扩展。jmp 指令的操作数有前缀 *,,表明这是一个间接跳转,操作数指定一个内存位置,索引由寄存器 %rsi 给出,这个寄存器保存着 index 的值。
汇编代码中,跳转表在 .rodata (只读数据)里。
.section .rodata
.align 8 Align address to multiple of 8
.L4:
.quad .L3 Case 100: loc_A
.quad .L8 Case 101: loc_def
.quad .L5 Case 102: loc_B
.quad .L6 Case 103: loc_C
.quad .L7 Case 104: loc_D
.quad .L8 Case 105: loc_def
.quad .L7 Case 106: loc_D
跳转表是一个数组,每个数组元素大小为 8 个字节(装的 64b 地址嘛)。
值得注意的是,跳转表必须是 “连续的”。意思是,即使某些 index 有缺失,比如有 case 100,102,103,没有 101。但跳转表里的第 1 项(从 0 开始算)并不是 case 102,而是 default case。也就是说,当 case 101 命中时,我们跳转到 default。
如何看跳转表有几个 case 呢?看比较的时候跟几比就行了。
作业题 3.63
怎么看一个 case 从哪开始?按照查找表顺序往下看。e.g. case 60 在一条空语句上面,是 x * 8 的操作。case 60 结束之后没有 retq,于是继续走到 case 62,所以 60 和 62 结果一样。而 case 61 命中空语句,然后返回,啥都没干,很合理。
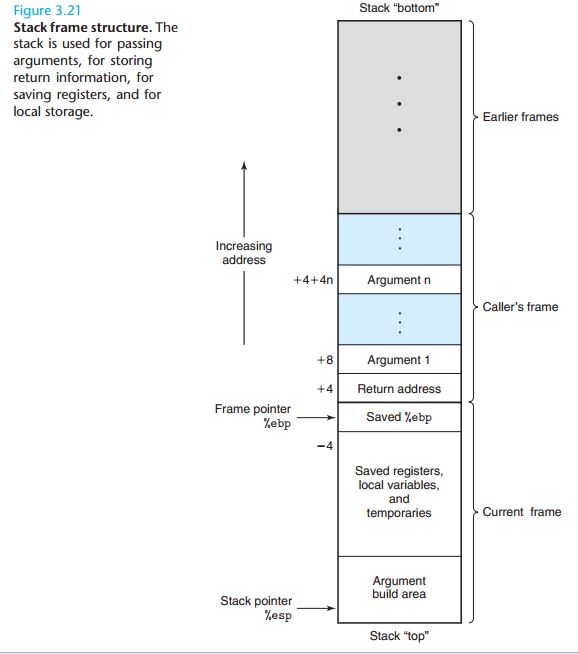
3.7 过程
栈帧的通用结构
3.9 异质的数据结构
3.9.3 数据对齐
许多计算机系统对基本数据类型的合法地址做出了一些限制,要求某种类型对象的地址必须是某个值 K(通常是 2、4 或 8)的倍数。这种对齐限制简化了形成处理器和内存系统之间接口的硬件设计。例如,假设一个处理器总是从内存中取 8 个字节,则地址必须为 8 的倍数。如果我们能保证将所有的 double 类型数据的地址对齐成 8 的倍数,那么就可以用一个内存操作来读或者写值了。否则,我们可能需要执行两次内存访问,因为对象可能被分放在两个 8 字节内存块中。
无论数据是否对齐,X86-64 硬件都能正确工作。不过,Intel 还是建议要对齐数据以提高内存系统的性能。对齐原则是 任何 K 字节的基本对象的地址必须是 K 的倍数。可以看到这条原则会得到如下对齐:
| 类型 | 大小 / byte | 地址要求(二进制表示) |
|---|---|---|
| char | 1 | 无要求 |
| short | 2 | 最低 1 位必须是 0 |
| int, float | 4 | 最低 2 位必须是 00 |
| double, long, char* | 8 | 最低 3 位必须是 000 |
| long double | 16 | 最低 4 位必须是 0000 |
确保每种数据类型都是按照指定方式来组织和分配,即每种类型的对象都满足它的对齐限制,就可保证实施对齐。编译器在汇编代码中放人命令,指明全局数据所需的对齐。例如,3.6.8 节开始的跳转表的汇编代码声明在第 2 行包含下面这样的命令:
.align 8
这就保证了它后面的数据(在此,是跳转表的开始)的起始地址是 8 的倍数。因为每个表项长 8 个字节,后面的元素都会遵守 8 字节对齐的限制。
struct S1 {
char c;
int i[2];
double v;
};
// 结构体的数据对齐:以结构体中最大的成员为对齐单位
// 最大成员为 double 型的 v,占 8 byte,所以 S1 按 8 byte 对齐,分配 3*8 = 24 byte for it
3.10 在机器级程序中将控制与数据结合起来
3.10.2 应用:使用 GDB 调试器
# 启动 gdb 调试 prog 程序
$ gdb prog
# 以下命令在启动 gdb 可用,即 $ 后出现 (gdb) 提示
# 命令可以简写,比如 run 写成 r,break 写成 b,
# print /x 写成 p /x
# --------------------------------------------------
# 运行程序
$ run
# 运行程序时输入命令行参数
$ run -t xxx
# 退出 gdb
$ quit
# --------------------------------------------------
# 断点打在函数 multstore 处
$ break multstore
# 断点打在地址 0x400540 处
$ break * 0x400540
# --------------------------------------------------
# 执行 1 条指令
$ stepi
# 执行 n 条指令
$ stepi n
# 执行 1 条指令,不进入函数内
$ nexti
# 继续执行
$ continue
# 运行到当前函数返回
$ finish
# --------------------------------------------------
# 反汇编当前函数
$ disas
# 反汇编函数 multstore
$ disas multstore
# 反汇编地址 0x400540 附近的函数
$ disas 0x400540
# --------------------------------------------------
# 输出 %rax 的内容
$ print $rax # 十进制
$ print /x $rax # 十六进制
$ print /t $rax # 二进制
# 以十六进制输出 %rax 的内容加上 8
$ print /x ($rax+8)
# 输出位于 0x400540 地址处的长整数
$ print *(long*) 0x400540
# 输出从 0x400540 地址处开始的 20 个字节(往高地址走)
$ x/20b 0x400540
#(gdb) help x
# Examine memory: x/FMT ADDRESS.
# ADDRESS is an expression for the memory address to examine.
# FMT is a repeat count followed by a format letter and a size letter.
# Format letters are o(octal), x(hex), d(decimal), u(unsigned decimal),
# t(binary), f(float), a(address), i(instruction), c(char) and s(string),
# T(OSType), A(floating point values in hex).
# Size letters are b(byte), h(halfword), w(word), g(giant, 8 bytes).
# The specified number of objects of the specified size are printed
# according to the format.
#
# Defaults for format and size letters are those previously used.
# Default count is 1. Default address is following last thing printed
# with this command or "print".
3.10.4 对抗缓冲区溢出攻击
- 栈破坏检测
最近的 GCC 版 本在产生的代码中加爲了一种栈保护者(stack protector)机制,来检测缓冲区越界。其思想
是在栈帧中任何局部缓冲区与栈状态之间存储一个特殊的金丝雀 (canary)值。这个金丝雀值是在程序每次运行
时随机产生的,因此,攻击者没有简单的办法能够知道它是什么。在恢复寄存器状态和从函数返回之前,程序检査
这个金丝雀值是否被该函数的某个操作或者该函数调用的某个函数的某个操作改变了。如果是的,那么程序异常
中止。
# gs:0x14 即金丝雀值
# lab2 里面的代码
Dump of assembler code for function sscanf:
=> 0xf7e23f60 <+0>: endbr32
0xf7e23f64 <+4>: push %ebp # %ebp 入栈,phase_5 的栈空间入口
0xf7e23f65 <+5>: push %edi # %edi 入栈(函数的第一个参数)
0xf7e23f66 <+6>: push %esi # %esi 入栈(函数的第二个参数)
0xf7e23f67 <+7>: push %ebx # %ebi 入栈(函数的第三个参数)
0xf7e23f68 <+8>: call 0xf7f15279
0xf7e23f6d <+13>: add $0x193093,%ebx
0xf7e23f73 <+19>: sub $0xc8,%esp
0xf7e23f79 <+25>: mov %gs:0x14,%eax # canary
0xf7e23f7f <+31>: mov %eax,0xb8(%esp)
// ...
0xf7e23fdf <+127>: add $0x20,%esp
0xf7e23fe2 <+130>: mov 0xac(%esp),%edx
0xf7e23fe9 <+137>: xor %gs:0x14,%edx # canary
// ...
0xf7e23ffc <+156>: ret
0xf7e23ffd <+157>: call 0xf7ee66c0 <__stack_chk_fail>
End of assembler dump.