一 背景
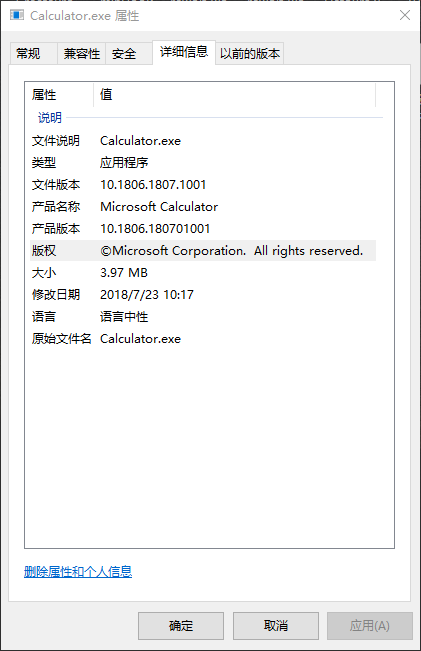
前几天, 在公司写的获取文件描述的一段小程序出现了点小问题, 对于一般文件是正常的, 对于win10 C:Program FilesWindowsApps目录下的通用程序,就是死活获取不到, 但是系统确是可以读出来的, 截图如下, 左边是能获取到的, 右边是比较各色的

之前用的方法参考
https://blog.csdn.net/liwen930723/article/details/49471459
vs跟踪调试了一下有问题的, 整个属性都获取到了, languageCharset也获取到了, 然后就是FileDescription死活获取不到, 但是看了看前边保存整个属性的内存, 文件描述就好好的躺在那, 左思右想不得要领, 于是拿调试器调试了一下系统是怎么获取的.原来系统是有备选方案的, 关键点就在 languageCharset上, 系统是先用从文件中读出来的languagecharset, 去获取, 获取不到再依次用0x040904B0,0x40904E4 ,0x04090000 去获取, 于是我按照这个逻辑试了一下, 真的就获取到了, 本文开头的问题就这么解决了, 但是你看系统给的备选值貌似存在某些规律, 而且 之前那个获取出来的languageCharset正好是0x00004B0, 于是又到网上去搜了搜, 结果发现, 正如这个东西的名字languagecharset, 高16bit 表示languageID, 低16bit表示codepage,
languageID: https://blog.csdn.net/tuwen/article/details/4160153
codepage: https://baike.baidu.com/item/codepage/416287
0x409 表示英语,
0x4E4 表示西欧拉丁字母ISO-8859-1
0x4B0 表示UCS-2LE Unicode 小端序
因为0x00004B0 表示语言的部分为0, 所以系统显示的就是语言为中性, 备选的都是英语的codepage组合, 问题到这终于圆满解决了.
不过, 本以为所有的显示"语言中性"的都这德行, 然而并不是, 所以我推测应该是某些编译器在生成这部分信息的时候出现了问题, 导致 languageCharset 跟其他信息不一致. 但是微软居然填这种坑, 所以我大胆的推测, 这个要么是当初定这个结构标准的时候没有设计好, 要么就真的微软自家的某些编译器组件的问题