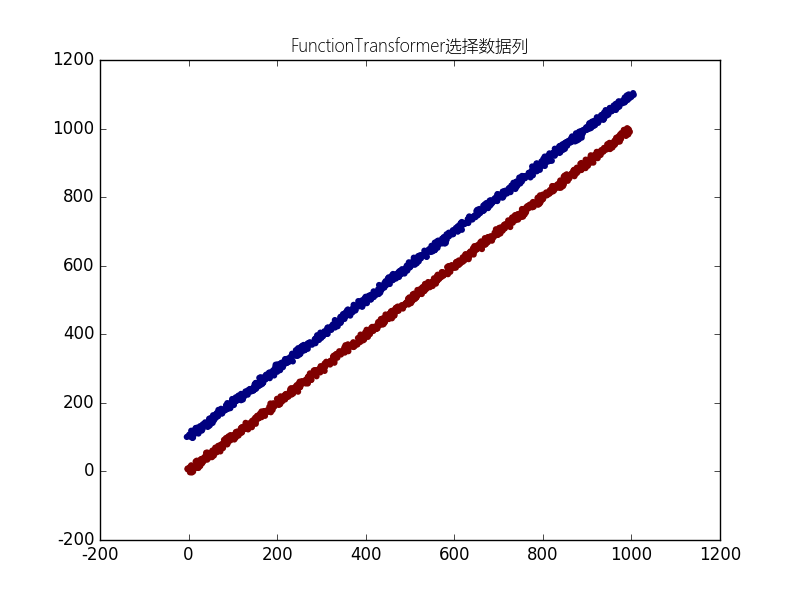
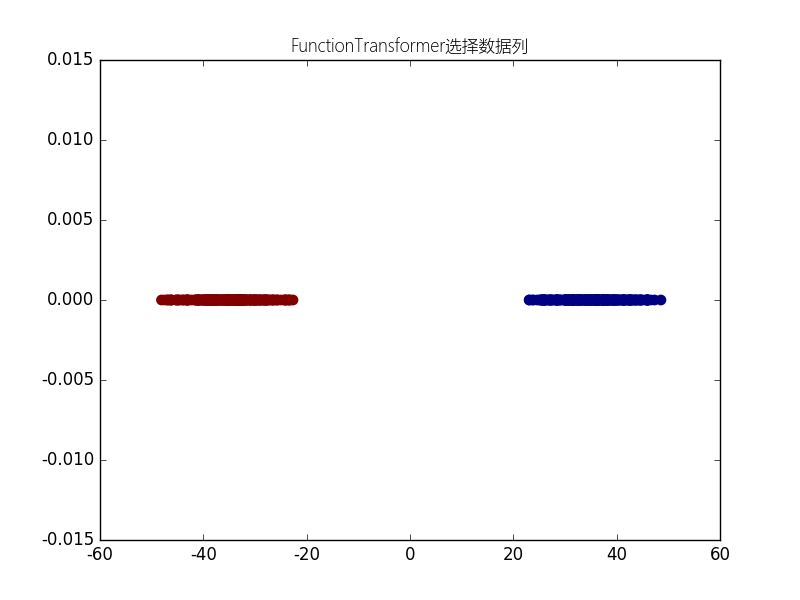
本例展示怎样在一个管道中使用FunctionTransformer.如果你知道你的数据集的第一主成分与分类任务无关,你可以使用FunctionTransformer选取除PCA转化的数据的第一列之外的全部数据.
# coding:utf-8
from pylab import *
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import FunctionTransformer
myfont = matplotlib.font_manager.FontProperties(fname="Microsoft-Yahei-UI-Light.ttc")
mpl.rcParams['axes.unicode_minus'] = False
def _generate_vector(shift=0.5, noise=15):
return np.arange(1000) + (np.random.rand(1000) - shift) * noise
def generate_dataset():
"""
本数据集是两条斜率为1的直线,一个截距为0,一个截距为100
"""
return np.vstack((
np.vstack((
_generate_vector(),
_generate_vector() + 100,
)).T,
np.vstack((
_generate_vector(),
_generate_vector(),
)).T,
)), np.hstack((np.zeros(1000), np.ones(1000)))
def all_but_first_column(X):
return X[:, 1:]
def drop_first_component(X, y):
"""
创建一个具有PCA(主成分分析)和列选择器的管道,
并使用它转换数据集
"""
pipeline = make_pipeline(
PCA(), FunctionTransformer(all_but_first_column),
)
X_train, X_test, y_train, y_test = train_test_split(X, y)
pipeline.fit(X_train, y_train)
return pipeline.transform(X_test), y_test
if __name__ == '__main__':
X, y = generate_dataset()
lw = 0
plt.figure()
plt.scatter(X[:, 0], X[:, 1], c=y, lw=lw)
plt.title(u"FunctionTransformer选择数据列",fontproperties=myfont)
plt.figure()
X_transformed, y_transformed = drop_first_component(*generate_dataset())
plt.scatter(
X_transformed[:, 0],
np.zeros(len(X_transformed)),
c=y_transformed,
lw=lw,
s=60
)
plt.title(u"FunctionTransformer选择数据列",fontproperties=myfont)
plt.show()