基本概念
损失函数:用来衡量预测结果和真实结果之间的差距,其值越小,代表预测结果和真实结果越一致。通常是一个非负实值函数。通过各种方式缩小损失函数的过程被称作 优化。损失函数记作 L(Y,f(x))。
损失函数分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和实际结果的差别,结构风险损失函数是指经验风险损失函数加上正则项。
0-1损失函数:预测值和实际值精确相等则“没有损失”为0,否则意味着“完全损失”为1。
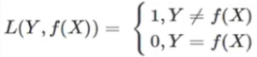
但是相等这个条件太过严格,因此可以放宽条件,即满足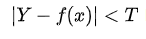 可以认为相等。
可以认为相等。
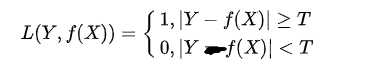
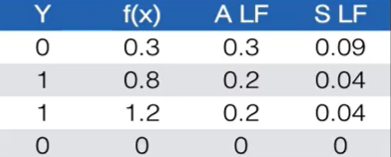
比如,对于相同的预测结果,两个损失函数严格程度不同。设T=0.5,则有:
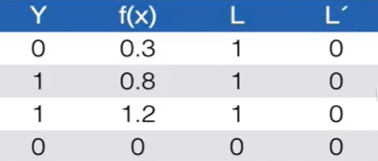
满足,所以,L'的严格程度就降低了,所以没有损失。
绝对值损失函数(Absolute LF):预测结果与真实结果差的绝对值。简单易懂,但是计算不方便。

log对数损失函数(Logarithmic LF)或 对数似然损失函数(log-likehood loss function):对数函数具有单调性,在求最优化问题时,结果与原视目标一致。可将乘法转化为加法。简化计算:
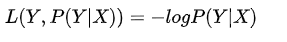
平方损失函数(Quadratic LF):预测结果与真实结果差的平方。
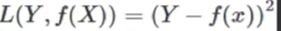
优势:
- 每个样本的误差都是正的,累加不会被抵消
- 平方对于大误差的惩罚大于小误差
- 数学计算简单、友好,导数为一次函数
指数损失函数(Exponential LF):单调性、非负性的优良性质,使得越接近正确结果误差越小:
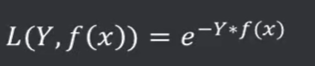
折叶损失函数(Hinge LF):也称铰链损失,对于判定边界附近点的惩罚力度较高,常见于SVM
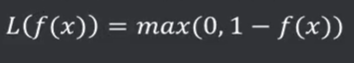

感知损失(perceptron loss)函数:
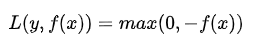
是Hinge损失函数的一个变种,Hinge loss对判定边界附近的点(正确端)惩罚力度很高。而perceptron loss只要样本的判定类别正确的话,它就满意,不管其判定边界的距离。它比Hinge loss简单,因为不是max-margin boundary,所以模型的泛化能力没 hinge loss强。
交叉熵损失函数 (Cross-entropy loss function)
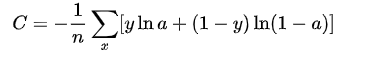
注意公式中 表示样本,
表示实际的标签,
表示预测的输出,
表示样本总数量。
本质上也是一种对数似然函数,可用于二分类和多分类任务中。
二分类问题中的loss函数(输入数据是softmax或者sigmoid函数的输出):
多分类问题中的loss函数(输入数据是softmax或者sigmoid函数的输出):