一、手写数字识别简介
手写数字识别是指给定一系列的手写数字图片以及对应的数字标签,构建模型进行学习,目标是对于一张新的手写数字图片能够自动识别出对应的数字。图像识别是指利用计算机对图像进行处理、分析和理解,以识别各种不同模式的目标和对像的技术。机器学习领域一般将此类识别问题转化为分类问题。
阿拉伯数字作为唯一被世界各国通用的符号,所以对手写体数字识别的研究基本.上与文化背景无关,各地的研究工作者可以说是基于同一-平台开展工作的,有利于研究的比较和探讨。
手写数字识别应用广泛,如税表系统,银行支票自动处理和邮政编码自动识别等。在以前,这些工作需要大量的手工录入,投入的人力物力都相对较多,而且劳动强度较大。为了适应无纸化办公的需要,大大提高工作效率,研究实现手写数字识别系统是必须要做的。
由于数字类别只有0-9共10个,比其他字符识别率较高,可将其用于验证新的理论或做深入的分析研究。许多机器学习和模式识别领域的新理论和算法都是先用手写数字识别进行检验,验证其理论的有效性,然后才会将其应用到更为复杂的领域当中。在这方面的典型例子就是人工神经网络和支持向量机。
二、手写数字识别核心内容
1)数字的绘制
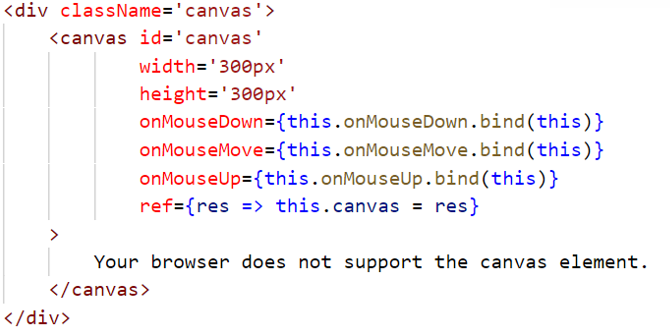
在Canvas画板绘制数字的窗口中实现数字的手写,利用清除按钮可实现数字的清除工作。
2)数字的预处理
在手写数字图像识别系统中,图像的预处理跟一般图像系统不同,我们不需要对图像进行灰度化处理、去噪处理等基本操作,我们利用程序保存的坐标值就可以对生成一张二值化图像,相当于图像处理系统的二值化处理。
将画布内容转化成base64,构建一个json格式的数据,将图片提交到后端
(Base64编码是从二进制到字符的过程,可用于在HTTP环境下传递较长的标识信息。采用Base64编码具有不可读性,需要解码后才能阅读。)
3) 数字的识别
识别过程就是输入的模型得到输出,具体过程就是首先cnn提取特征,再将特征输入到全连接层,概率是神经网络的输出,因为数字有10个,所以是10分类问题,网络就会输出10个logits,10个logits经过softmax()就得到了概率
4)前后端分离

前后端分离是目前一种非常流行的开发模式,它使项目的分工更加明确:
后端:负责处理、存储数据
前端:负责显示数据
前端和后端开发人员通过 接口 进行数据的交换。
前后端都各自有自己的开发流程,构建工具,测试集合
关注点分离,前后端变得相对独立并解耦合
5) 使用react书写前端界面
react是一个JavaScript类库,可用于创建Web用户交互界面。它引入了一种新的方式来处理浏览器DOM。
react只关注数据,不关心dom(即文档对象模型,它允许脚本(js)控制Web页面、窗口和文档)。
react是数据驱动的,只要数据改变,视图会自动更新,因此开发速度更快,也更简单高效。

6)鼠标监听事件
初始化当前画板的画笔状态,drawline=false。
getContext方法返回一个用于在画布上绘图的环境,在这里的2d是指绘制的是二维图形。
Context.linewidth=6,是指画笔宽度为6.
当鼠标按下时(onmousedown),把DrawLine设为true,表示正在画。
当按下鼠标的时候,鼠标移动(onmousemove)就把点记录下来并画出来。
鼠标松开的时候(onmouseup),把DrawLine为false,表示图至绘制。
如果鼠标移动过快,浏览器跟不上绘画速度,点与点之间会出现间隙,所以我们需要将画出的点连起来(line.to)。


7)识别按钮处理
使用toDateURL将canvas画布的内容转化成图片发送到后端处理识别并将识别结果显示
json的作用(json是一种与语言无关的数据交换的格式)
前端的图片通过canvas的toDataURL转化成了base64
json传的是base64的图片,后端把base64转化成png
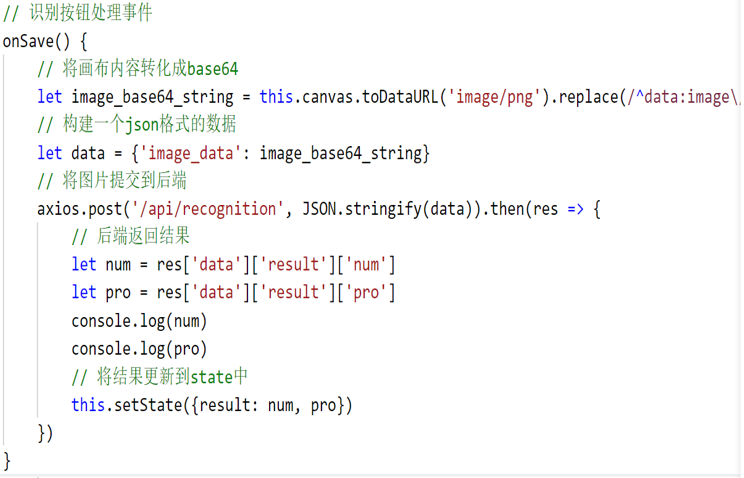
8)清空画布按钮
beginPath( )是重新开始新路径,而把之前的路径都清空掉。
clearRect( ) 方法清空给定矩形内的指定像素。
通过 setTransform( ) 重置并创建新的变换矩阵,然后再次绘制图形。
三、使用深度学习框架pytorch搭建lenet5网络
LeNet-5网络堪称卷积神经网络(CNN)的经典之作,它最早是在1998年在论文中提出的。LeNet-5主要是用作识别手写字符,虽然它的识别性能很高,但是在其发表之后的数十年里LeNet-5并没有流行起来,最主要的原因还是因为当时计算机的计算能力很有限,人们对于训练规模如此之小的网络也会感到略显艰难。Lenet-5网络的规模虽然很小,但是它却已经基本蕴含了卷积层、池化层、全连接层等知识。
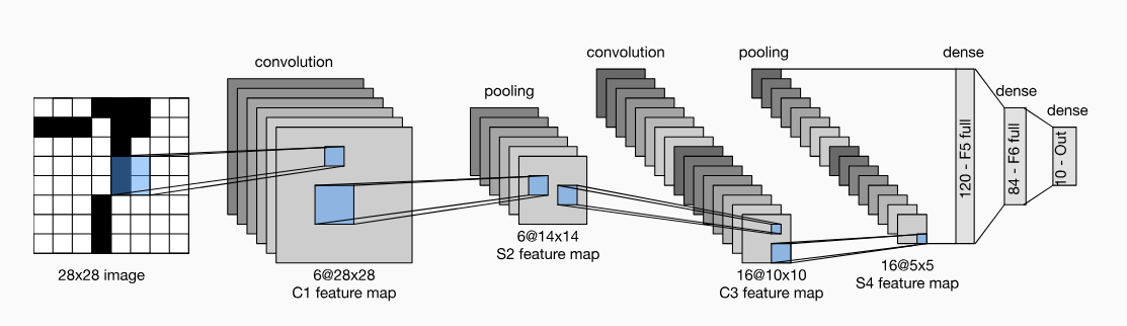
该模型有1个输入层、2个卷积层、2次Max Pooling、2个全连接层和1个输出层。
- 输入层INPUT:1个channel,图片size是32×32。
- 卷积层C1:6个channel,特征图的size是28×28,即每个卷积核的size为(5,5),stride为1。
- 下采样操作S2: 6个channel,特征图的size是14×14,即Max Pooling窗口size为(2,2)。
- 卷积层C3:16个channel,特征图的size是10×10,即每个卷积核的size为(5,5),stride为1。
- 下采样操作S4:16个channel,特征图的size是5×5,即Max Pooling窗口size为(2,2)。
- 全连接层F5:120个神经元。
- 全连接层F6: 84个神经元。
- 输出层OUTPUT: 10个神经元。
四、使用轻量级的flask框架搭建一个后端服务处理数据
Flask是一个基于Python开发的一个微型框架,其用于接收http请求并对请求进行预处理,然后触发Flask框架,开发人员基于Flask框架提供的功能对请求进行相应的处理,并返回给用户。
flask服务器接收到前端传来的图片加以处理后调用训练的模型进行识别并将识别结果返回到前端。
搭建服务器代码
五、使用mnist数据集训练lenet5网络得到手写体数字识别模型
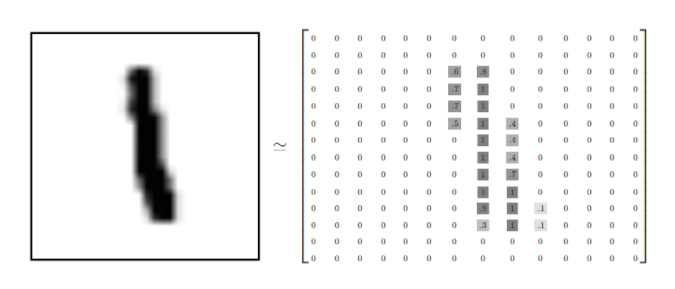
MNIST 数据集来自美国国家标准与技术研究所,共有7万张图片。其中6万张用于训练神经网络,1万张用于测试神经网络。每张图片是一个28*28像素点的0~9的手写数字图片。
白底黑字的图片,白底用0表示,黑字用0~1之间的浮点数表示,越接近1,颜色越黑;若为黑底白字的图片,则反之。
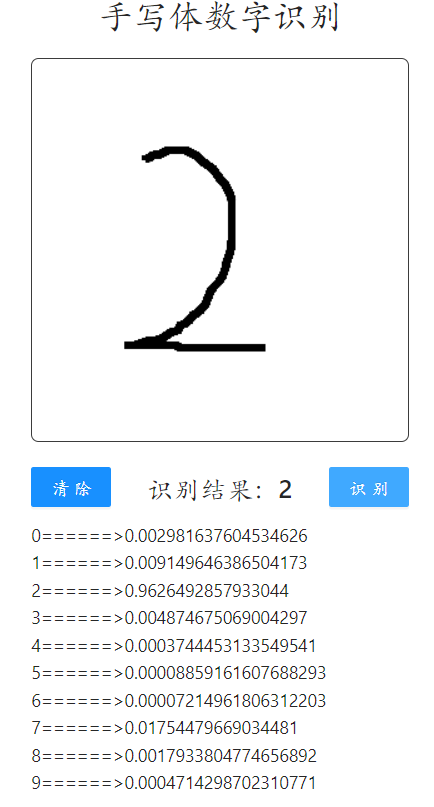
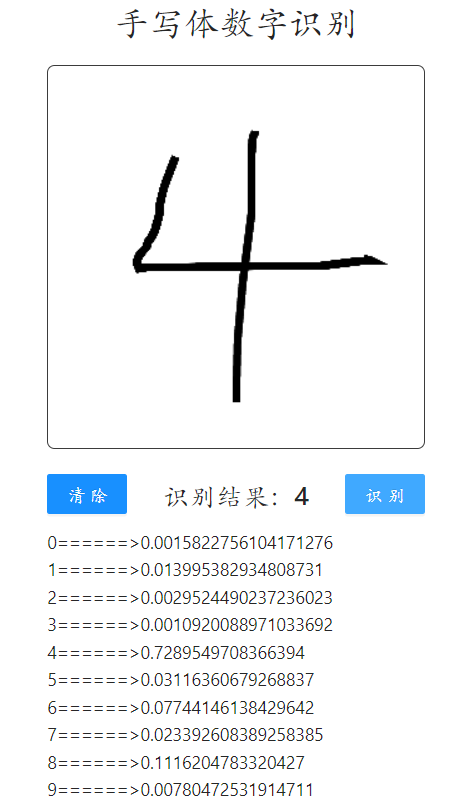
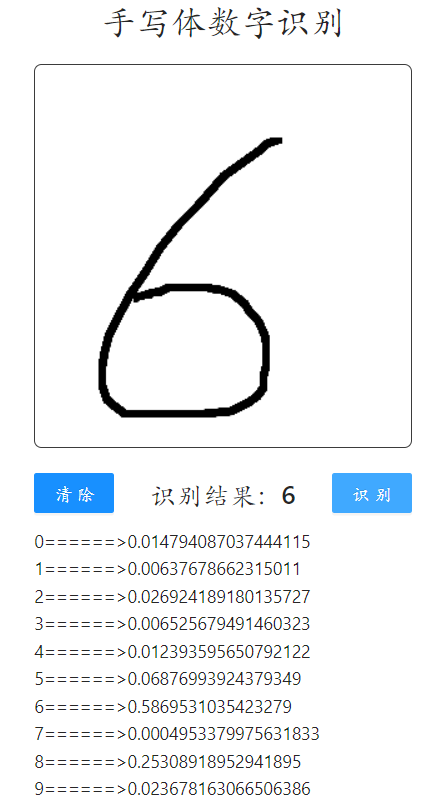
六、结果演示