ELK学习
#配置Filebeat来发送日志行到Logstash
在你创建Logstash管道之前,你需要先配置Filebeat来发送日志行到Logstash。Filebeat客户端是一个轻量级的、资源友好的工具,
它从服务器上的文件中收集日志,并将这些日志转发到你的Logstash实例以进行处理。
Filebeat设计就是为了可靠性和低延迟。Filebeat在主机上占用的资源很少,而且Beats input插件将对Logstash实例的资源需求降到最低
Filebeat和Logstash实例是分开的,它们分别运行在'不同的机器上'
filebeat.inputs:
- type: log
paths:
- /usr/local/programs/logstash/logstash-tutorial.log
output.logstash:
hosts: ["localhost:5044"]
#先关闭监控,再删除.monitoring索引
PUT _cluster/settings
{
"transient": {
"xpack.monitoring.collection.enabled": false
}
}
#命令行查看索引
[root@db01 ~]# ll /service/es/data/nodes/0/indices/
total 0
drwxr-xr-x 6 elasticsearch elasticsearch 47 Aug 13 21:21 0WzU0MIbRqObaI9y881o3A
drwxr-xr-x 8 elasticsearch elasticsearch 65 Aug 13 21:21 2I3Kzw0WSS6EDiyl0Xv5mA
一、ELK介绍
1.什么是ELK
ELK是三个软件
1.E:elasticsearch java程序 存储,查询日志
2.L: logstash java程序 收集、过滤日志,消耗内存多,功能多
3.K: kibana java程序 提供web服务,将数据页面化
4.F: filebeat go 收集、过滤日志,消耗内存少,功能较少
2.ELK作用
1.收集: 收集所有服务器的'日志'
2.传输: 把日志稳定的传输到ES或者其他地方
3.存储: 'ES'能有效快速的存储日志数据
4.分析: 通过web页面分析数据,kibana,空闲的时候可以进行备份等
5.监控: 监控集群架构,kibana
3.ELK优点
1.处理方式灵活:elasticsearch是实时全文索引,具有强大的搜索功能,filebeat logstash redis elasticsearch 可以组合使用(#管道配置灵活)
2.配置相对简单:elasticsearch全部使用'JSON 接口',logstash使用'模块配置',kibana的'配置文件部分更简单'。
3.检索性能高效:基于优秀的设计,虽然每次查询都是实时,但是也可以达到百亿级数据的查询秒级响应。
4.集群线性扩展:elasticsearch和logstash都可以灵活线性扩展
5.前端操作绚丽:kibana的前端设计比较绚丽,而且操作简单
4.为什么使用ELK
#收集所有的日志
web服务日志
业务服务日志
系统日志
#统计、分析:,可以根据ip做图(时间 访问次数)
1.统计访问量,wc
2.统计访问量前10的IP,wc|sort|head
3.站点访问次数最多的URL
4.查询一上午以上三个值
5.查询一下午以上三个值
6.对比一下上下午用户访问量
7.对比这一周,每天用户增长还是减少
#故障响应
二、ELK搭建
1.ES搭建,参考01
2.搭建 Logstash
1)安装java环境
#上传
[root@db01 ~]# rz jdk-8u181-linux-x64.rpm
#安装
[root@db01 ~]# rpm -ivh jdk-8u181-linux-x64.rpm
[root@db03 local]# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
2)时间同步
[root@web01 ~]# ntpdate time1.aliyun.com
3)安装Logstash
1.上传包
[root@web01 ~]# rz logstash-6.6.0.rpm
2.安装
[root@web01 ~]# rpm -ivh logstash-6.6.0.rpm
3.授权,logstash操作的文件的权限必须是logstash
[root@web01 ~]# chown -R logstash.logstash /usr/share/logstash/
#启动程序
/usr/share/logstash/bin/logstash
#配置环境变量
[root@web01 ~]# vim /etc/profile.d/logstash.sh
export PATH=/usr/share/logstash/bin/:$PATH
[root@web01 ~]# id logstash
uid=664(logstash) gid=664(logstash) groups=664(logstash)
#要收集哪台机器上的日志,就把logstash安装在哪台机器
3.logstash介绍
1)输入 过滤 输出插件介绍
一个Logstash管理它通常有一个或多个input, filter 和 output 插件
#输入:采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择 ,可以在'同一时间从众多常用来源捕捉事件'。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
#过滤器:实时解析和转换数据
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
Logstash 能够'动态地转换和解析数据',不受格式或复杂度的影响:
利用 Grok 从非结构化数据中派生出结构
从 IP 地址破译出地理坐标
将 PII 数据匿名化,完全排除敏感字段
整体处理不受数据源、格式或架构的影响
编码解码插件本质是一种流过滤器,配合输入插件或输出插件使用
#输出:选择你的存储,导出你的数据
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方
| INPUT支持事件源 | OUTPUT支持输出源 | CODEC编解码器支持编码 |
|---|---|---|
| azure_event_hubs(微软云事件中心) | elasticsearch(搜索引擎数据库) | avro(数据序列化) |
| beats(filebeat日志收集工具) | email(邮件) | CEF(嵌入式框架) |
| elasticsearch(搜索引擎数据库) | file(文件) | es_bulk(ES中的bulk api) |
| file(文件) | http(超文本传输协议) | Json(数据序列化、格式化) |
| generator(生成器) | kafka(基于java的消息队列) | Json_lines(便于存储结构化) |
| heartbeat(高可用软件) | rabbitmq(消息队列 OpenStack) | line(行) |
| http_poller(http api) | redis(缓存、消息队列、NoSQL) | multiline(多行合为一条) |
| jdbc(java连接数据库的驱动) | s3*(存储) | plain(纯文本,事件间无间隔) |
| kafka(基于java的消息队列) | stdout(标准输出) | rubydebug(ruby语法格式) |
| rabbitmq(消息队列 OpenStack) | tcp(传输控制协议) | |
| redis(缓存、消息队列、NoSQL) | udp(用户数据报协议) | |
| s3*(存储) | ||
| stdin(标准输入) | ||
| syslog(系统日志) | ||
| tcp(传输控制协议) | ||
| udp(用户数据报协议) |
#Logstash 每读取一次数据的行为叫做事件,每行都是es中的一条数据
#file插件可以配置多个,file插件中,每行内容在es中都是一条数据
#Multiline codec 插件,这个插件可以将多行日志信息合并成一行,作为一个事件处理。
2)Logstash输入输出测试
#收集标准输入到标准输出测试,选项 -e 的意思是允许你从命令行指定配置
[root@web01 ~]# logstash -e 'input { stdin {} } output { stdout {} }'
#测试输入
123456
{
#时间戳
"@timestamp" => 2020-08-13T01:34:24.430Z,
#主机
"host" => "web01",
#版本
"@version" => "1",
#内容
"message" => "123456"
}
#收集标准输入到标准输出指定格式,codec => rubydebug }的意思是输出到控制台
[root@web01 ~]# logstash -e 'input { stdin {} } output { stdout { codec => rubydebug } }'
123456
{
"message" => "123456",
"@version" => "1",
"@timestamp" => 2020-08-13T01:39:40.837Z,
"host" => "web01"
}
3)Logstash收集标准输入到文件
#收集标准输入到文件
[root@web01 ~]# logstash -e 'input { stdin {} } output { file { path => "/tmp/test.txt" } }'
#收集标准输入到文件,年月日
[root@web01 ~]# logstash -e 'input { stdin {} } output { file { path => "/tmp/test_%{+YYYY-MM-dd}.txt" } }'
4)Logstash收集标准输入到ES
#收集标准输入到ES
[root@web01 ~]# logstash -e 'input { stdin {} } output { elasticsearch { hosts => ["10.0.0.51:9200"] index => "/tmp/test_%{+YYYY-MM-dd}" } }'
#随便输入些内容,回车
#kibana查看索引数
4.kibana搭建,参考文章01
1)安装java环境
2)安装kibana
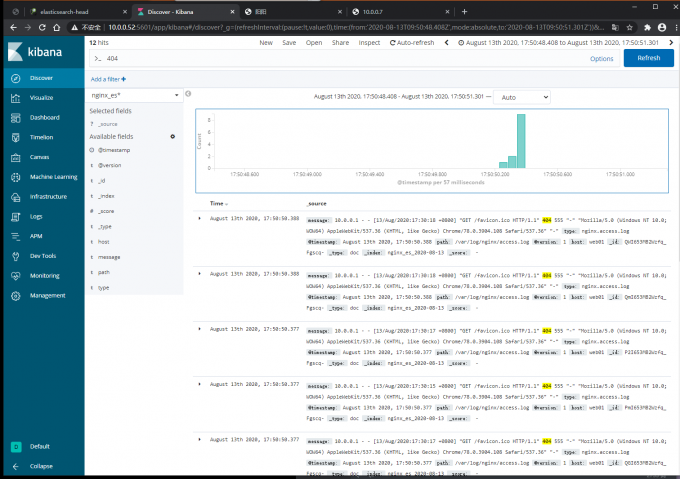
3)kibana页面
1.时间区域
2.日志列表区域
3.搜索区域
4.数据展示区
三、Logstash使用
Logstash是一个开源的数据收集引擎,可以水平伸缩,而且logstash'整个ELK当中拥有最多插件的一个组件',其可以接收来自不同来源的数据并统一输出到指定的且可以是多个不同目的地。
logstash原理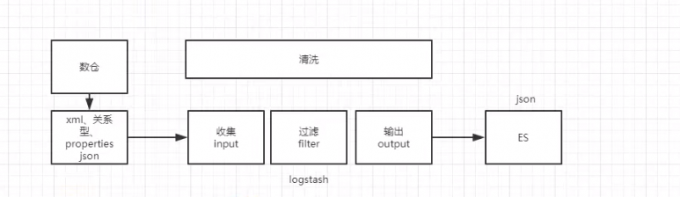
logstash消息队列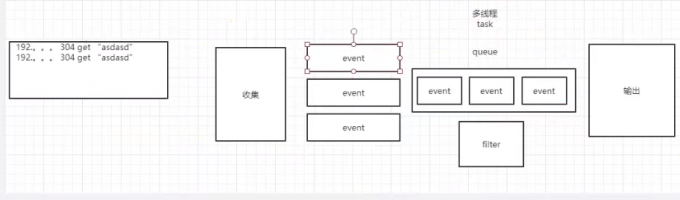
1.logstash的配置文件
#默认的配置文件
[root@web01 ~]# rpm -qc logstash
/etc/logstash/logstash.yml
#一般不使用,只有用system管理时才使用
2.收集文件中的日志到文件
1)配置
#收集message.conf配置文件制定的path,输出到文件
[root@web01 ~]# vim /etc/logstash/conf.d/message_file.conf
input {
file {
path => "/var/log/messages"
start_position => "beginning"
}
}
output {
file {
path => "/tmp/message_file_%{+YYYY-MM-dd}.log"
}
}
#不指定的话,logstash就从开始拿日志,不指定的话,就只拿新的日志
start_position => "beginning"
2)启动
#检测配置
[root@web01 ~]# logstash -f /etc/logstash/conf.d/message_file.conf -t
#启动
[root@web01 ~]# logstash -f /etc/logstash/conf.d/message_file.conf &
#修改完配置文件以后无需停止然后重启Logstash
[root@web01 ~]# logstash -f first-pipeline.conf --config.reload.automatic
3)查看是否生成文件
[root@web01 tmp]# ll
total 4
-rw-r--r-- 1 root root 1050 Aug 13 11:24 message_file_2020-08-13.log
3.收集文件中的日志到ES
1)配置
#收集message.conf配置文件制定的path,输出到es
[root@web01 ~]# vim /etc/logstash/conf.d/message_es.conf
input {
file {
path => "/var/log/messages"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["10.0.0.51:9200","10.0.0.52:9200","10.0.0.53:9200"]
index => "message_es_%{+YYYY-MM-dd}"
}
}
2)启动
[root@web01 ~]# logstash -f /etc/logstash/conf.d/message_es.conf &
[root@web01 ~]# echo 123 >> /var/log/messages
3)查看kibana页面索引数量
4.启动 多个 logstash收集日志 ,多个实例
1)创建多个数据目录
[root@web01 ~]# mkdir /data/logstash/{message_file,message_es} -p
#授权
[root@web01 ~]# chown -R logstash.logstash /data/
2)启动时指定数据目录
[root@web01 ~]# logstash -f /etc/logstash/conf.d/message_es.conf --path.data=/data/logstash/message_es &
[1] 18693
[root@web01 ~]# logstash -f /etc/logstash/conf.d/message_file.conf --path.data=/data/logstash/message_file &
[2] 18747
3)验证
查看文件(/tmp/message_file_%{+YYYY-MM-dd}.log)和ES页面(kibana中索引数量)
5.一个logstash收集多个日志
1)配置
[root@web01 ~]# vim /etc/logstash/conf.d/more_file.conf
#收集日志,导入文件
input {
file {
type => "messages_log"
path => "/var/log/messages"
start_position => "beginning"
}
file {
type => "secure_log"
path => "/var/log/secure"
start_position => "beginning"
}
}
output {
if [type] == "messages_log" {
file {
path => "/tmp/messages_%{+YYYY-MM-dd}"
}
}
if [type] == "secure_log" {
file {
path => "/tmp/secure_%{+YYYY-MM-dd}"
}
}
}
#收集日志,导入es
input {
file {
type => "nginx.access.log"
path => "/var/log/nginx/access.log"
start_position => "beginning"
}
file {
type => "tomcat.log"
path => "/var/log/tomcat/localhost_access_log.*.txt"
start_position => "beginning"
}
}
output {
if [type] == "nginx.access.log" {
elasticsearch {
hosts => ["10.0.0.51:9200","10.0.0.52:9200","10.0.0.53:9200"]
index => "nginx_es_%{+YYYY-MM-dd}"
}
}
if [type] == "tomcat.log" {
elasticsearch {
hosts => ["10.0.0.51:9200","10.0.0.52:9200","10.0.0.53:9200"]
index => "tomcat_es_%{+YYYY-MM-dd}"
}
}
}
#启动
[root@web01 ~]# logstash -f /etc/logstash/conf.d/message_es.conf &
--node.name NAME
指定Logstash实例的名字。如果没有指定的话,默认是当前主机名。(#指定主机名)
-f, --path.config CONFIG_PATH
从指定的文件或者目录加载Logstash配置。如果给定的是一个目录,则该目录中的所有文件将以字典顺序连接,然后作为一个配置文件进行解析。(#配置文件)
-e, --config.string CONFIG_STRING
用给定的字符串作为配置数据,语法和配置文件中是一样的。(#命令行)
--modules
运行的模块名字
-l, --path.logs PATH
Logstash内部日志输出目录
--log.level LEVEL
日志级别
-t, --config.test_and_exit
检查配置语法是否正确并退出 (#检查语法)
-r, --config.reload.automatic
监视配置文件的改变,并且当配置文件被修改以后自动重新加载配置文件。(#reload)
-config.reload.interval RELOAD_INTERVAL
为了检查配置文件是否改变,而拉去配置文件的频率。默认3秒。
--http.host HTTP_HOST
Web API绑定的主机。REST端点绑定的地址。默认是"127.0.0.1"
--http.port HTTP_PORT
Web API http端口。REST端点绑定的端口。默认是9600-9700之间。
--log.format FORMAT
指定Logstash写它自身的使用JSON格式还是文本格式。默认是"plain"。
--path.settings SETTINGS_DIR
设置包含logstash.yml配置文件的目录,比如log4j日志配置。也可以设置LS_SETTINGS_DIR环境变量。默认的配置目录是在Logstash home目录下。
-h, --help
打印帮助
作业:
1.搭建Nginx和Tomcat
2.使用logstash收集Nginx和Tomcat的日志
3.kibana展示日志