Nginx负载均衡调度算法
| 调度算法 | 概述 |
|---|---|
| 轮询(RR) | 按时间顺序逐一分配到不同的后端服务器(默认) |
| weight(WRR) | 加权轮询,weight值越大,分配到的访问几率越高(默认是1) |
| ip_hash | 每个请求按访问IP的hash结果分配,这样来自同一IP的固定访问一个后端服务器(公网IP),作用于用户登录后 |
| url_hash | 按照访问URL的hash结果来分配请求,是每个URL定向到同一个后端服务器 |
| least_conn | 最少链接数,那个机器链接数少就分发(链接数不等于请求数) |
服务器配置不同的时候 负载均衡服务器(lb)可以使用加权轮询,
#配置ip_hash,缺陷:同一个公网IP,访问量异常的时候,优点是会话保持
upstream load_pass {
ip_hash;
server 10.0.0.7:80 weight=5;
server 10.0.0.8:80;
}
Nginx负载均衡后端状态
后端Web服务器在前端Nginx负载均衡调度中的状态
| 状态 | 概述 |
|---|---|
| down | 当前的server暂时不参与负载均衡(等于注释) |
| backup | 预留的备份服务器(不到万不得已,不会分配请求)(类似于高可用) |
| max_fails | 允许请求失败的次数 |
| fail_timeout | 经过max_fails失败后, 服务暂停时间 |
| max_conns | 限制最大的接收连接数(连接数不是请求数,与请求数无关) |
测试down状态测试该Server不参与负载均衡的调度,和注释类似
upstream load_pass {
#不参与任何调度, 一般用于停机维护
server 10.0.0.7:80 down;
}
测试backup以及down状态
upstream load_pass {
server 10.0.0.7:80 down;
server 10.0.0.8:80 backup;
server 10.0.0.9:80 max_fails=1 fail_timeout=10s;
}
location / {
proxy_pass http://load_pass;
include proxy_params;
}
测试max_fails失败次数和fail_timeout多少时间内失败多少次则标记down
#这个得配合错误返回码,proxy_next_upstream error timeout http_500 http_502 http_503 http_504 http_404 http_403;
upstream load_pass {
server 10.0.0.7:80;
server 10.0.0.8:80 max_fails=2 fail_timeout=10s;
}
测试max_conns最大TCP连接数
upstream load_pass {
server 10.0.0.7:80;
server 10.0.0.8:80 max_conns=100;
}
负载均衡模板
vim /etc/nginx/conf.d/wp.conf
server {
listen 80;
server_name cs.zh.com;
location / {
proxy_pass http://backend;
include proxy_params;
}
}
#include后面的相对路径指定就是/etc/nginx/ 下
vim /etc/nginx/nginx.conf
...
include /etc/nginx/upstream;
include /etc/nginx/conf.d/*.conf;
vim /etc/nginx/upstream
upstream backend {
#server backend1.example.com weight=5;
#server backend2.example.com:8080;
#server unix:/tmp/backend3;
#server backup1.example.com:8080 backup;
#server 10.0.0.7:80 down;
#server 10.0.0.9:80 backup;
server 10.0.0.7;
server 10.0.0.8;
server 10.0.0.9:80 max_fails=1 fail_timeout=10s;
}
vim /etc/nginx/proxy_params
# 客户端的请求头部信息,带着域名来找我,我也带着域名去找下一级(代理机或者代理服务器)
proxy_set_header Host $host;
# 显示客户端的真实ip(和代理的所有IP)
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
#nginx代理与后端服务器连接超时时间(代理连接超时)
proxy_connect_timeout 60s;
#nginx代理等待后端服务器的响应时间
proxy_read_timeout 60s;
#后端服务器数据回传给nginx代理超时时间
proxy_send_timeout 60s;
#nignx会把后端返回的内容先放到缓冲区当中,然后再返回给客户端,边收边传, 不是全部接收完再传给客户端
proxy_buffering on;
#设置nginx代理保存用户头信息的缓冲区大小
proxy_buffer_size 4k;
#proxy_buffer_size 8k;
#proxy_buffers 缓冲区
proxy_buffers 8 4k;
#proxy_buffers 8 8k;
#使用http 1.1协议版本
proxy_http_version 1.1;
#解决集群单点故障的反馈页面影响用户体验,自动跳转到下一个负载均衡主机
#proxy_next_upstream error timeout http_500 http_502 http_503 http_504 http_404;
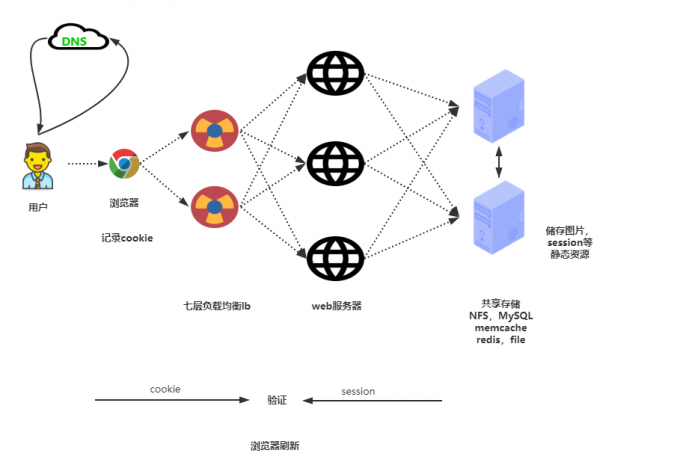
会话保持(也叫session共享)
面试题:
- 开发层面实现
- 记录用户的登录状态,将登录状态保存到我们的redis服务器中(更倾向),nfs共享存储,mysql数据库
- 我们从运维层面实现
- 因为开发没有写会话保持的功能,所以我们只能在nginx中使用upstream模块的ip_hash调度算法,但是这个算法,可能会负载不均衡,有弊端...
什么是session?服务器存储,session是为了保护cookie
什么是cookie?浏览器存储,有生存时间,过了生存时间就要重新登录重新生成
Nginx负载均衡会话保持
在使用负载均衡的时候会遇到会话保持的问题,可通过如下方式进行解决。
-
使用nginx的 ip_hash ,根据客户端的IP,将请求分配到对应的IP上
-
基于服务端的 session 会话共享(NFS,MySQL,memcache,redis,fifile)
在解决负载均衡会话问题,我们需要了解 session 和 cookie 的区别。 浏览器端存的是 cookie ,每次浏览器发请求到服务端时,报文头是会自动添加 cookie 信息的。 服务端会查询用户的 cookie 作为key去存储里找对应的value(session) 同一域名下的网站的 cookie 都是一样的,所以无论几台服务器,无论请求分配到哪一台服务器上同一用户的 cookie 是不变的。也就是说 cookie 对应的 session 也是唯一的。所以,这里只要保证多台业务服务器访问同一个共享存储服务器(NFS,MySQL,memcache,redis,fifile)就行了。
总结
- 需要登录的网站才需要做会话保持
- cookie储存在客户端的浏览器上
- session储存在服务器上
碎碎念
四层负载均衡 OSI 传输层 转发
七层负载均衡 OSI 应用层 代理
四层负载均衡后面的七层负载均衡#server配置一定要相同
四层负载均衡是基于传输层协议包来封装的(如:TCP/IP),那我们前面使用到的七层是指的应用层,他的组装在四层的基础之上,无论四层还是七层都是指的#OSI网络模型
四层负载均衡不识别域名,七层负载均衡识别域名
动静分离好处:动静分离后,即使动态服务不可用,但静态资源不会受到影响。
使用proxy代理模块可实现,专线内网的传输,多台主机的负载均衡,多台主机的动静分离
公网IP :
局域网IP :
弹性IP :
nginx主配置文件支持include,#支持绝对路径或者相对路径(/etc/nginx)
分为通用的include:一般放在/etc/nginx下
不通用的include:可以在/etc/nginx下创建一个专门存放不通用文件的目录
#IP网段划分网段:
用来区分网路上的主机是否在同一网路区段内,在局域网中,每台电脑只能和自己同一网段的电脑互相通讯。
不处於同一网段,则它们之间无法相互连接
所谓的私有地址就是在互联网上不使用,而被用在局域网络中的地址
网际地址分解成两个域后,带来了一个重要的优点:IP数据包从网际上的一个网络到达另一个网络时,选择路径可以基于网络而不是主机。这样可以大大简化路由表
使用复制,或者scp rsync,可以减少集群中的操作
可以使用ssh连接内网中的服务器,和公匙私匙的校验是两种连接的方式
重复登录服务可以初步认为是会话保持的问题
买机器,注册域名,备案
连接数据库不影响scp
知乎的代码不支持session共享
favcion 类似于网站的logo
value就是一个变量