编辑距离是求两个文本的相似度的一种算法。
我们将两个字符串 a,b 的 Levenshtein Distance 表示为 lev_{a,b}(|a|, |b|),其中|a| 和 |b| 分别对应a,b 的长度,公式如下

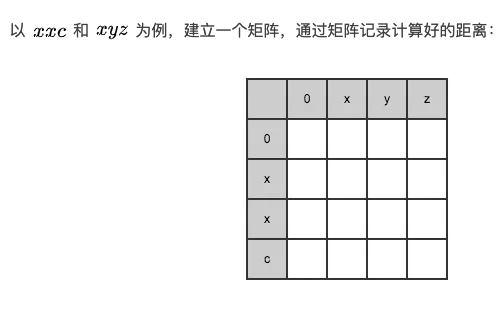
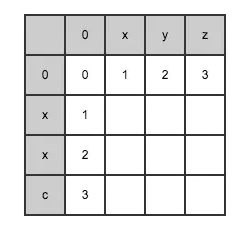
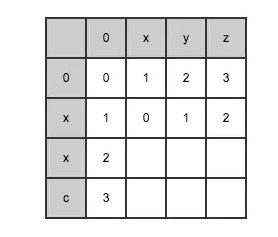
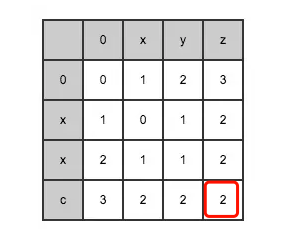
红框中的数字即为最终求取的"xyz"与"xxc"的编辑距离
应用与思考
编辑距离是NLP基本的度量文本相似度的算法,可以作为文本相似任务的重要特征之一,其可应用于诸如拼写检查、论文查重、基因序列分析等多个方面。但是其缺点也很明显,算法基于文本自身的结构去计算,并没有办法获取到语义层面的信息。
由于需要利用矩阵,故空间复杂度为O(MN)。这个在两个字符串都比较短小的情况下,能获得不错的性能。不过,如果字符串比较长的情况下,就需要极大的空间存放矩阵。例如:两个字符串都是20000字符,则 LD 矩阵的大小为:20000 * 20000 * 2=800000000 Byte=800MB