切记:seq命令用于产生从某个数到另外一个数之间的所有整数。sed才是处理文本的命令
在遇到扩展符号时,需要添加特定参数,| () +[] 为扩展符号时,必须添加参数
egrep/grep -E sed -r
windows和linux互传文件,yum install lrzsz -y,直接拖拽就行了
空行的表达式:'/^$/'
- grep命令 可以使用单引号或者双引号
-v --取反
$ --结尾
^ --开头
查看文件中非注释的信息
grep -v "^#" qq.txt通过 ip address s ens33获取到ip地址,因为你使用扩展符号,所以要用egrep
ip address s ens33 | egrep "([0-9]+.){3}[0-9]+" #获取单行ip地址
#获取单行ip地址
ip address s ens33|egrep "([0-9]+.){3}[0-9]+" -o|head -1批量创建用户
echo syscal{01..10} | xargs -n1 | sed -r 's#(.*)#useradd 1#g'|bash批量创建用户并设置初始密码为123456
seq -w 10| sed -r 's#(.*)# useradd bubu1;echo 123456|passwd --stdin bubu1#g'|bash
seq命令
-w 补零
- sed命令 必须得用单引号使用表达式
- -i 是直接对文件编辑插入操作 &&如果不加这个,脚本中是异步执行的,加了这个就是同步执行
此例子是对本地ip地址进行修改sed -ri 's#IPADDR=(.*)10#IPADDR=111#g' /etc/sysconfig/network-scripts/ifcfg-ens33 && systemctl restart network && echo "服务器地址是:"$(hostname -I)>>~/qq.txt
- -n 根据sed原理可知 默认不输出文本 例子:sed -n '/test/p' ~/qq.txt
上面例子中的格式是固定的,p就是输出处理,print
n和i 一定要注意使用,否则会问题的,修改文件一定要备份源文件
- p print 输出信息
sed -n '1,3p' ~/qq.txt #输出1到3行
- i insert 插入信息
sed '1ithis is insert' qq.txt #在第一行之前插入信息因为i是直接修改文件的。所以修改之前记得备份文件,可以使用-i.bak的方法,这样编辑之前创建bak文件了
- a append 附加信息
sed '$athis is insert' qq.txt #在最后一行之后插入信息
- -e 需要多次执行sed命令时,用-e进行区分
sed -e '/bulusi/athis is new data' -e "/yangci/i ddw" qq.txt
- d 删除信息
#删除第一行到第三行 sed '1,3d' qq.txt
#删除第三行到最后一行 sed '3,$d' qq.txt
#删除带有test的行 sed '/test/d' qq.txt
#删除第一行和第三行
sed '1d;3d' qq.txt
#不显示空行,相当于把行给删除了
sed '/^$/d' qq.txt
#对带有#号进行修改 原有的格式是#,但可以/进行代替,所以含有#号的文本就可以修改了
sed 's/#best/bast/g'
#获取ip地址
ip addr s eth0|sed -rn '3s#^.*net (.*)/20.*#1#gp'
- 题目
1.批量修改命名文件,在目录下有base1.txt~base10.txt,批量修改为base1~10.txt
find ~/base/ -type f|sed -r 's#(.*).(.*)#mv 1.2 1.jpg#g'|bash
#另一种方法,主要区别就是,&符号的使用,&是将找到信息放出来,可以理解为集合
find ~/base/ -type f|sed -r 's#(.*)txt#mv & 1jpg#g'|bash
#也可以使用rename命令
rename .txt .jpg base*.txt2.将目录下test.c文件中将 printf(" ******** ");改为print("*******")
代码片段
注意:特色符号要用修饰,不然不能准确让系统识别,匹配正则时)("符号都要修饰
 View Code#include <stdio.h> #include <stdlib.h> #include <signal.h> #include <sys/wait.h> #include <unistd.h> #include <sys/types.h> int flag_wait=1; void stop1() { flag_wait=0; printf(" Child process1 is killed by parent!"); } void stop2() { flag_wait=0; printf(" Child process2 is killed by parent!"); } void stop() { printf(" 手动中断 "); } int main() { pid_t pid1,pid2; //如果出现终止操作,则调用stop函数。 //signal监听到中断信号后,会重新回到原来执行的地方,也就是sleep(5)下一行代码 signal(2,stop); while((pid1=fork())==-1); //主进程 if(pid1>0) { while((pid2=fork())==-1); // 主进程执行 if(pid2>0) { sleep(5); kill(pid1,16); kill(pid2,17); wait(0); wait(0); printf(" Parent process is killed! "); exit(0); } else { // 子进程2执行 signal(17,stop2); while(flag_wait); exit(0); } } else { // pid1子进程执行 signal(16,stop1); while(flag_wait); exit(0); } return 0; }sed -r 's#printf("\n(.*))#print("\n1)#g' test.c
View Code#include <stdio.h> #include <stdlib.h> #include <signal.h> #include <sys/wait.h> #include <unistd.h> #include <sys/types.h> int flag_wait=1; void stop1() { flag_wait=0; printf(" Child process1 is killed by parent!"); } void stop2() { flag_wait=0; printf(" Child process2 is killed by parent!"); } void stop() { printf(" 手动中断 "); } int main() { pid_t pid1,pid2; //如果出现终止操作,则调用stop函数。 //signal监听到中断信号后,会重新回到原来执行的地方,也就是sleep(5)下一行代码 signal(2,stop); while((pid1=fork())==-1); //主进程 if(pid1>0) { while((pid2=fork())==-1); // 主进程执行 if(pid2>0) { sleep(5); kill(pid1,16); kill(pid2,17); wait(0); wait(0); printf(" Parent process is killed! "); exit(0); } else { // 子进程2执行 signal(17,stop2); while(flag_wait); exit(0); } } else { // pid1子进程执行 signal(16,stop1); while(flag_wait); exit(0); } return 0; }sed -r 's#printf("\n(.*))#print("\n1)#g' test.c

- awk
测试文本2020-10-14 192.168.1.2 /api/bbs/login 2020-10-14 192.168.2.2 /api/bbs/login 2020-10-12 192.168.3.2 /api/bbs/login 2020-10-11 192.168.4.2 /api/bbs/login 2020-11-12 192.168.5.2 /api/bbs/login 2020-10-24 192.168.1.2 /api/bbs/login 2020-10-14 192.168.3.2 /api/bbs/home 2020-10-14 192.168.3.2 /api/bbs/menu 2020-11-12 192.168.5.2 /api/bbs/index 2020-10-24 192.168.6.2 /api/bbs/login 2020-10-14 192.168.1.2 /api/bbs/login 2020-10-14 192.168.1.2 /api/bbs/login
- 初学小提示
NR指的是行,大于第二行的信息,NF指的列(Date ip route)这样NF就是3了
awk "NR>2" ip.logawk中使用BEGIN,BEGIN的作用可以理解为表头,END理解为结束后使用的字段。
awk 'BEGIN{ print("Date","ip","route") }{print $0}END{print "操作结束"}' ip.log|column -t
- #输出指定列
下面是固定格式,默认以空格为分隔符,,$0表示的是一整行,$1,$3 是指只显示第一列和第三列
awk '{print $1,$3}' ip.log #指定输出某行的列,/路径需要用进行转义 awk '/api/bbs/login/{print $1,$3}' ip.log
- -F 指定分隔符的类型 这样就以:分隔符,找出第一列和第三列
awk -F ":" '{print $1,$3}' ip.log #取最后一列 awk -F ":" '{print $1,$NF}' ip.log #取最后第二列,一定要加小括号,不然就变成减法操作了 awk -F ":" '{print $1,$(NF-1)}' ip.log#补充知识点 [ ,]里面是空格和逗号,代表的是以空格和为分隔符,分割的列数就是从左到右开始算,+号是多次匹配 uptime|awk -F "[ ,]+" '{print $9}'
- gsub 格式:gsub(/需要替换的字符/,"修改后的信息",将哪列信息进行修改)
#将日期分隔符"-"替换为"#"符号 awk '$1~/2019/{gsub(/-/,"#",$1);print $0}' ip.log
- 练手题目
#题1·找出192.168.1 ip段的访问路径 awk '/192.168.1.*/{print $1,$NF}' ip.log #第二种做法(严谨) ~代表以第二列开始匹配以192.168.1开头的ip地址段 awk '$2~/^192.168.1.*/{print $1,$NF}' ip.log #题2·找出ip后两位为5.2和1.2的ip段的访问时间和路径 解释:(5.2)$ 意思就是以这个结尾的,column -t 专治强迫症 awk '$2~/(5.2)$|(1.2)$/{print $1,$2,$3}' ip.log|column -t #题3·用awk计算出空行的行数 awk 'BEGIN{i=0}/^$/{i++}END{printf("总行数是%d ",i)}' ip.log #题4·统计普通用户和虚拟用户的数量(/etc/passwd 查看用户情况) #普通用户(含有bash就是普通用户) awk 'BEGIN{i=0}$NF~/bash/{i++}END{print i}' /etc/passwd #虚拟用户(加了个!,表示取反) awk 'BEGIN{i=0}$NF!~/bash/{i++}END{print i}' /etc/passwd#题5·统计:符号第二列和第三列的总数
awk -F ":" 'BEGIN{print("第一总额","第二总额");sum1=0;sum2=0}$NF!~/^$/{sum1+=$2;sum2+=$3}END{print sum1,sum2}' ip.log|column -t

#使用三剑客,屏蔽#开头和空行的文本 grep -Ev '^#|^$' ip.log awk '$1!~/^#|^$/{print $1,$2,$3}' ip.log
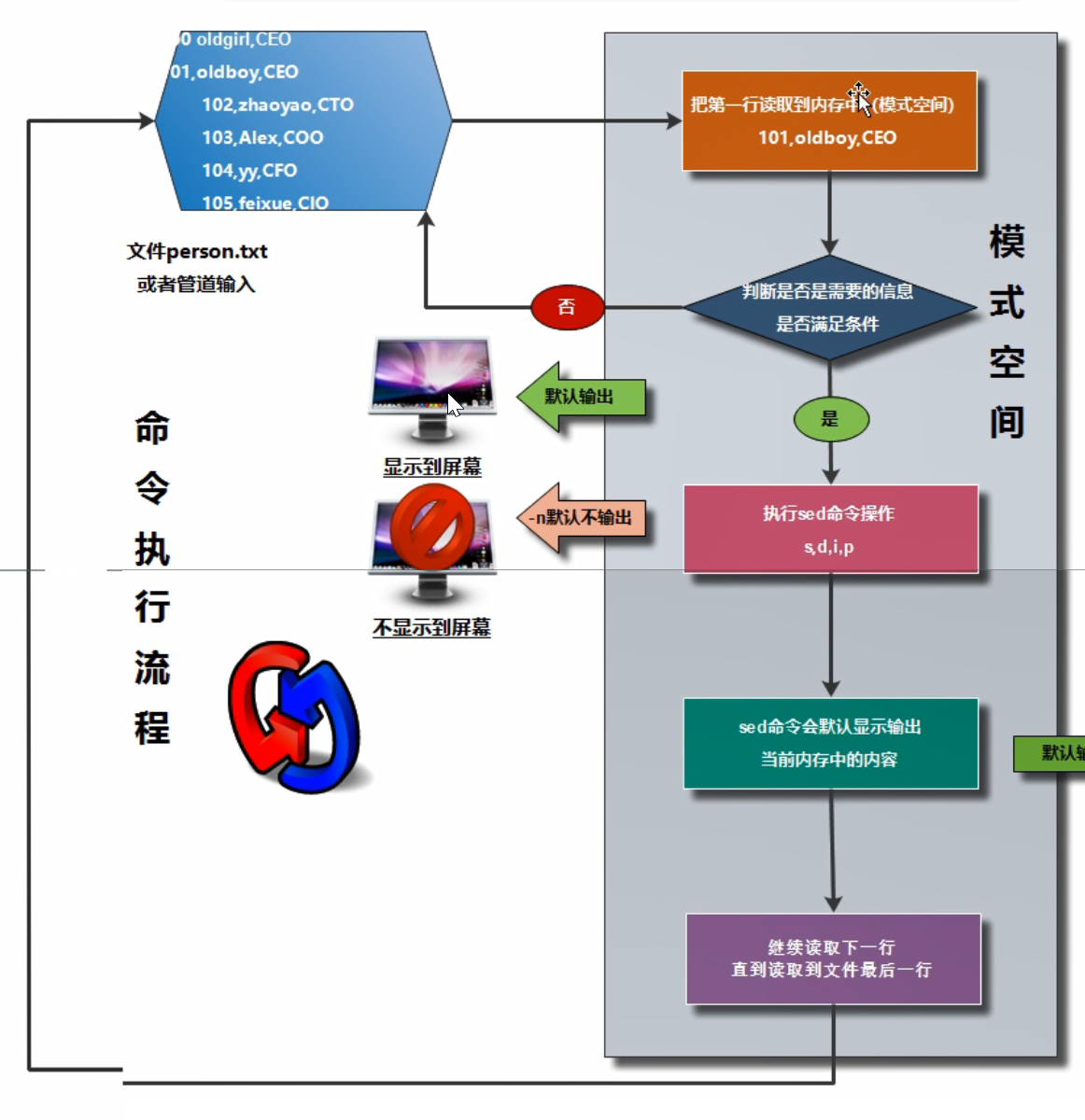
sed原理