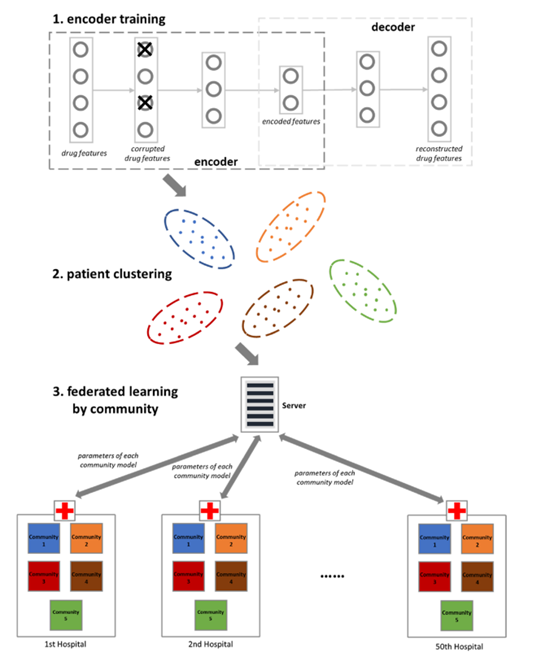
一、论文提出的方法:
使用进入ICU前48h的用药特征作为预测因子预测重症监护患者的死亡率和ICU住院时间。
用到了联邦学习,自编码器,k-means聚类算法,社区检测。
数据集:从50家患者人数超过600人的医院,每个医院抽取560名患者形成最终的28000例数据集,20000作为训练集,8000作为测试集。
二、具体实现:
1.每个医院各自训练自编码器重构药物特征
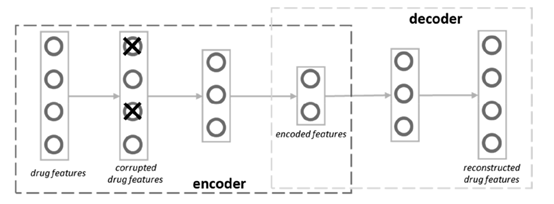
2. 每个医院用将各自data转换为向量表示,然后将所有医院的平均值返回给server
3. Server使用k-means算法作用于训练k-means clustering model:
4. Community-based learning:
(1) server初始化K个neural network models.
(2) 每个医院在自己的数据集学习K个model,并用和确定每个example属于哪个cluster,得到表示每个cluster的size,并用均值更新server.
(3) Server将更新的model重新发送给每个医院进行下一次的训练直到收敛,得到community model.
5. 给定一个测试集,用编码,用定义community,使用community model进行预测
6.Pipline: