利用爬虫获取网上医院药品价格信息 (上)
在对比医院业务数据中的各类药品价格的时候,面对着成千上百种的药品。因而想到使用爬虫来自动获取网上的药品价格,保存下来导入数据库中就可以方便地比较院方的药品采购价格了。
通过百度搜索“药品价格查询”,在众多的网站中,这里选择了药价查询网(http://www.china-yao.com/),主要是因为这个网站不需要用户注册就可以查询药品价格,另外查询结果显示界面比较简洁,编写爬虫较为省心。
随便在该站点搜索药品“氟氯西林钠阿莫西林胶囊”,查看生成结果页面的源代码(如下):

<?php
$url=$_SERVER["PHP_SELF"];
if(strpos($url,"templet")){
exit();
}else if(!isset($_SESSION['HTTP_REFERER'])){
exit();
}
?><!DOCTYPE html>
<html>
···此处代码已省略···
<tbody>
<!-- <tr>-->
<!-- <td>氟氯西林钠阿莫西林胶囊</td>-->
<!-- <td>Bangalore</td>-->
<!-- <td>560001</td>-->
<!-- <td>Tanmay</td>-->
<!-- <td>Bangalore</td>-->
<!-- <td>560001</td>-->
<!-- </tr>-->
<tr>
<td>氟氯西林钠阿莫西林胶囊</td>
<td>胶囊剂</td>
<td>0.25g(0.125g/0.125g)*12</td>
<td>5.1 </td>
<td>37.3 </td>
<td>湖南中南科伦药业有限公司</td>
</tr><tr>
<td>氟氯西林钠阿莫西林胶囊</td>
<td>胶囊剂</td>
<td>0.25g(按氟氯西林0.125g,阿莫西林0.125g)*12</td>
<td>5.1</td>
<td>34.8</td>
<td>湖南中南科伦药业有限公司</td>
</tr>
···此处代码已省略···
<div class="col-xs-12 text-center">
<ul class="pagination">
<li class="active"><a href="?act=search&typeid=1&keyword=氟氯西林钠阿莫西林胶囊&page=1">1</a></li><li><a href="?act=search&typeid=1&keyword=氟氯西林钠阿莫西林胶囊&page=2">2</a></li><li><a href="?act=search&typeid=1&keyword=氟氯西林钠阿莫西林胶囊&page=3">3</a></li>
··此处代码已省略···
从代码的第一行可以看出该站使用的是PHP,url为“http://www.china-yao.com/?act=search&typeid=1&keyword=%E6%B0%9F%E6%B0%AF%E8%A5%BF%E6%9E%97%E9%92%A0%E9%98%BF%E8%8E%AB%E8%A5%BF%E6%9E%97%E8%83%B6%E5%9B%8A”,其中“keyword=”后跟的是“氟氯西林钠阿莫西林胶囊”的utf8编码格式,该药品的价格信息比较多,总共有3页,点开第三页后,此时url变为“http://www.china-yao.com/?act=search&typeid=1&keyword=%E6%B0%9F%E6%B0%AF%E8%A5%BF%E6%9E%97%E9%92%A0%E9%98%BF%E8%8E%AB%E8%A5%BF%E6%9E%97%E8%83%B6%E5%9B%8A&page=3”,就是在原url地址的基础上增加了“&page=3”,其中数字3表示第三页。而页码数存在于代码(<ul class="pagination"> ······ </ul>)之间。很显然,我们只需要把url中“keyword=”和“&page=”后面的信息替换掉就可以组合出带有我们需要信息的页面的url。之后把生成的url进行utf8编码后发送给网站,生成带有查询结果的页面,筛选出(<tbody> ······ </tbody>)之间的信息进行保存。
好了,了解到这些之后,下面我们就开始写代码了。
一、使用到的软件工具
Python 2.7
Eclipse
二、导入需要用到的模板
1 from bs4 import BeautifulSoup 2 import urllib2 3 from myLog import MyLog 4 import time 5 import xlwt 6 import csv 7 import random
其中myLog是一个自定义模板,其实就是对logging模板的简单格式化,代码如下:
1 import logging
2 import getpass
3 import sys
4
5 class MyLog(object):
6 def __init__(self):
7 self.user = getpass.getuser()
8 self.logger = logging.getLogger(self.user)
9 self.logger.setLevel(logging.DEBUG)
10 self.logFile = sys.argv[0][0:-3] + '.log'
11 self.formatter = logging.Formatter('%(asctime)-12s %(levelname)-8s %(name)-10s %(message)-12s
')
12 self.logHand = logging.FileHandler(self.logFile, encoding='utf8')
13 self.logHand.setFormatter(self.formatter)
14 self.logHand.setLevel(logging.DEBUG)
15 self.logHandSt = logging.StreamHandler()
16 self.logHandSt.setFormatter(self.formatter)
17 self.logHandSt.setLevel(logging.DEBUG)
18 self.logger.addHandler(self.logHand)
19 self.logger.addHandler(self.logHandSt)
20
21 def debug(self,msg):
22 self.logger.debug(msg)
23
24 def info(self,msg):
25 self.logger.info(msg)
26
27 def warn(self,msg):
28 self.logger.warn(msg)
29
30 def error(self,msg):
31 self.logger.error(msg)
32
33 def critical(self,msg):
34 self.logger.critical(msg)
35
36 if __name__ == '__main__':
37 mylog = MyLog()
三、简单构建好框架,写出需要用到的主要函数和方法,代码如下:
1 class Item(object):
2 mc = None #名称
3 jx = None #剂型
4 gg = None #规格
5 ghj = None #供货价
6 lsj = None #零售价
7 scqy = None #生成企业
8
9 class GetInfor(object):
10 def __init__(self):
11 self.log = MyLog()
12 self.starttime = time.time()
13 self.log.info(u'爬虫程序开始运行,时间: %s' % time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(self.starttime)))
14 self.medicallist = self.getmedicallist('name.txt')
15 self.items = self.spider(self.medicallist)
16 self.pipelines_csv(self.items)
17 self.endtime = time.time()
18 self.log.info(u'爬虫程序运行结束,时间: %s' % time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(self.endtime)))
19 self.usetime = self.endtime - self.starttime
20 self.log.info(u'用时 %d时 %d分%d秒' % (self.usetime//3600,(self.usetime%3600)//60,(self.usetime%3600)%60))
21
22 def getmedicallist(self,filename):
23 '''从文件name.txt中导出所有需要查询的药品的名称
24 '''
25 medicallist = []
26 with open(filename,'r') as fp:
27 s = fp.read()
28 for name in s.split():
29 medicallist.append(name)
30 self.log.info(u'从文件%s 中读取药品名称成功!获取药品名称 %d 个' % (filename,len(medicallist)))
31 return medicallist
32
33 def spider(self,names):
34 items = []
35 pass
36 return items
37
38 def pipelines_xls(self,medicallist):
39 pass
40
41 def pipelines_csv(self,medicallist):
42 pass
43
44 def getresponsecontent(self,url):
45 try:
46 response = urllib2.urlopen(url.encode('utf8'))
47 except:
48 self.log.error(u'返回 URL: %s 数据失败' % url)
49 return ''
50 else:
51 self.log.info(u'返回URL: %s 数据成功' % url)
52 return response
53
54 if __name__ == '__main__':
55 GetInfor()
Item包含了网站查询结果中所含的元素,方便到时候用来提取数据。GetInfor为爬虫主程序。getmedicallist用来从文本“name.txt”中提取需要查询的药品名称(该文件是先从医院数据库中导出的医院所涉及到的药品名称),返回含有药品名称的列表。spider用于在网上爬取药品价格信息,将所有信息保存到列表items中,并返回。pipelines_xls和pipelines_csv分别用于将保存下来的数据保存到xls和csv格式的文件中。getresponsecontent从spider中分离出来主要是为了方便后期的扩展。
四、添加SPIDER的代码
我们使用方法getmedicallist获取到所有需要查询的药品名称后,在这里通过变量names来读取,如下:
1 for name in names:
2 if name != '':
3 self.log.info(u'尝试爬取%s 信息' % name.decode('GBK'))
4 url = 'http://www.china-yao.com/?act=search&typeid=1&keyword='+name.decode('GBK')
5 htmlcontent = self.getresponsecontent(url)
不加“&page=n”的情况下,只返回查询结果第一页的信息。但查询结果总共有多少页?我们需要先提取出这个最大页数。
在页面代码
<ul class="pagination"> <li class="active"><a href="?act=search&typeid=1&keyword=氟氯西林钠阿莫西林胶囊&page=1">1</a></li><li><a href="?act=search&typeid=1&keyword=氟氯西林钠阿莫西林胶囊&page=2">2</a></li><li><a href="?act=search&typeid=1&keyword=氟氯西林钠阿莫西林胶囊&page=3">3</a></li>
的这一段之中,有我们需要的页码值,而我们只需要最后一页,也就是最大值。
1 def spider(self,names):
2 n = 1
3 items = []
4 for name in names:
5 if name != '':
6 url = 'http://www.china-yao.com/?act=search&typeid=1&keyword='+name.decode('GBK')
7 htmlcontent = self.getresponsecontent(url)
8 soup = BeautifulSoup(htmlcontent,'lxml')
9 tagul = soup.find('ul',attrs={'class':'pagination'})
10 print tagul
11 tagpage = tagul.find_all('a')
12 for page in tagpage:
13 print '###',page.get_text().strip()
14 n += 1
15 if n>15:
16 Break #先简单测试下前15种药品是否能正常返回我们需要的页码数
17 return items
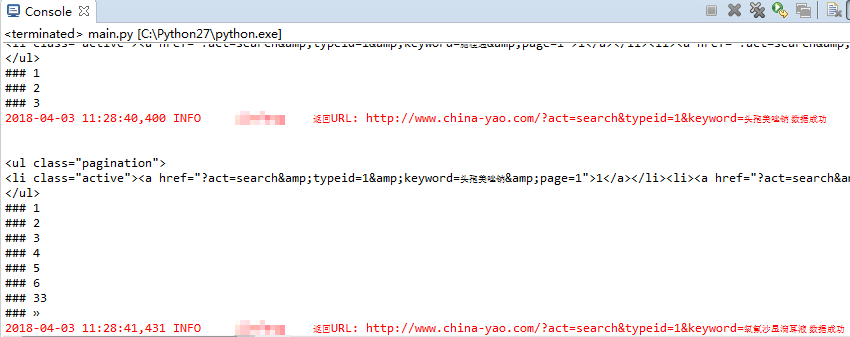
从运行结果来看,效果还算满意,通过tagul.find_all('a')得到的列表最后一条基本都是结果页面最后一页的页码。但如果结果页面过多的时候,可以看到最后一页的页码不在列表的最后,而是处于列表的倒数第二行。修改增加如下代码,利用try来让程序自动选择提取最后一行还是倒数第二行。
1 if len(tagpage) == 0: 2 page = 0 3 else: 4 try: 5 page = int(tagpage[-1].get_text().strip()) 6 except: 7 page = int(tagpage[-2].get_text().strip())
获取到最后一页查询结果的页码值后,我们就可以组合出完整的url地址了。遍历所有的url组合,提取出tbody之间的药品价格信息。方法spider的完整代码如下:
1 def spider(self,names):
2 items = []
3 for name in names:
4 if name != '':
5 self.log.info(u'尝试爬取%s 信息' % name.decode('GBK'))
6 url = 'http://www.china-yao.com/?act=search&typeid=1&keyword='+name.decode('GBK')
7 htmlcontent = self.getresponsecontent(url)
8 soup = BeautifulSoup(htmlcontent,'lxml')
9 tagul = soup.find('ul',attrs={'class':'pagination'})
10 tagpage = tagul.find_all('a')
11 self.log.info(u'此药品信息共%d 页' % len(tagpage))
12 time.sleep(1)
13 if len(tagpage) == 0:
14 page = 0
15 else:
16 try:
17 page = int(tagpage[-1].get_text().strip())
18 except:
19 page = int(tagpage[-2].get_text().strip())
20 for i in range(1,page+1):
21 newurl = url+'&page='+str(i)
22 newhtmlcontent = self.getresponsecontent(newurl)
23 soup = BeautifulSoup(newhtmlcontent,'lxml')
24 tagtbody = soup.find('tbody')
25 tagtr = tagtbody.find_all('tr')
26 self.log.info(u'该页面共有记录 %d 条,开始爬取' % len(tagtr))
27 for tr in tagtr:
28 tagtd = tr.find_all('td')
29 item = Item()
30 item.mc = tagtd[0].get_text().strip()
31 item.jx = tagtd[1].get_text().strip()
32 item.gg = tagtd[2].get_text().strip()
33 item.ghj = tagtd[3].get_text().strip()
34 item.lsj = tagtd[4].get_text().strip()
35 item.scqy = tagtd[5].get_text().strip()
36 items.append(item)
37 self.log.info(u'页面%s 数据已保存' % newurl)
38 sleeptime = random.randint(7,12)
39 time.sleep(sleeptime) #给程序适当降速,防止被服务器拦截
40
41 self.log.info(u'数据爬取结束,共获取 %d条数据。' % len(items))
42 return items
五、保存收集到的数据
添加方法pipelinespipelines_xls和pipelines_csv的代码
1 def pipelines_xls(self,medicallist):
2 filename = u'西药药品价格数据.xls'.encode('GBK')
3 self.log.info(u'准备保存数据到excel中...')
4 book = xlwt.Workbook(encoding = 'utf8',style_compression=0)
5 sheet = book.add_sheet(u'西药药品价格')
6 sheet.write(0,0,u'名称'.encode('utf8'))
7 sheet.write(0,1,u'剂型'.encode('utf8'))
8 sheet.write(0,2,u'规格'.encode('utf8'))
9 sheet.write(0,3,u'供货价'.encode('utf8'))
10 sheet.write(0,4,u'零售价'.encode('utf8'))
11 sheet.write(0,5,u'生产企业'.encode('utf8'))
12 for i in range(1,len(medicallist)+1):
13 item = medicallist[i-1]
14 sheet.write(i,0,item.mc)
15 sheet.write(i,1,item.jx)
16 sheet.write(i,2,item.gg)
17 sheet.write(i,3,item.ghj)
18 sheet.write(i,4,item.lsj)
19 sheet.write(i,5,item.scqy)
20 book.save(filename)
21 self.log.info(u'excel文件保存成功!')
22
23 def pipelines_csv(self,medicallist):
24 filename = u'西药药品价格数据.csv'.encode('GBK')
25 self.log.info(u'准备保存数据到csv中...')
26 writer = csv.writer(file(filename,'wb'))
27 writer.writerow([u'名称'.encode('utf8'),u'剂型'.encode('utf8'),u'规格'.encode('utf8'),u'供货价'.encode('utf8'),u'零售价'.encode('utf8'),u'生产企业'.encode('utf8')])
28 for i in range(1,len(medicallist)+1):
29 item = medicallist[i-1]
30 writer.writerow([item.mc.encode('utf8'),item.jx.encode('utf8'),item.gg.encode('utf8'),item.ghj.encode('utf8'),item.lsj.encode('utf8'),item.scqy.encode('utf8')])
31 self.log.info(u'csv文件保存成功!')