1 Ceph简述
Ceph是一种性能优越,可靠性和可扩展性良好的统一的分布式云存储系统,提供对象存储、块存储、文件存储三种存储服务。Ceph文件系统中不区分节点中心,在理论上可以实现系统规模的无限扩展。Ceph文件系统使用了较为简单的数据地址管理方法,通过计算的方式直接得到数据存放的位置。其客户端程序只需要根据数据ID经过简单的计算就可以决定数据存放的位置。
2 存储容错机制简述
2.1 副本冗余容错机制
基于副本冗余的容错机制是将原始数据复制成多份,每一份称为一个副本。将这些副本分别存放在集群中的不同节点上,当集群中有些节点出现故障时,只要其余健康节点中任一个节点拥有副本,用户就可以获取该数据。当前众多存储系统(包括Ceph)都采用副本数为3的副本冗余容错机制,这种机制能很好地保证数据可靠性,但也会极大降低存储空间利用率。
在Ceph中,用户可以根据需要创建存储池,并设置存储池中数据的副本数目,每个数据副本被分到不同的对象存储设备(OSD)上,当存储设备中有故障,可以从其他健康的设备上获取数据。
2.2 纠删码容错机制
在存储系统中,纠删码技术主要是通过利用纠删码算法将原始的数据进行编码得到冗余,并将数据和冗余一并存储起来,以达到容错的目的。其基本思想是将k块原始的数据元素通过一定的编码计算,得到m块冗余元素。对于这k+m块的元素,当其中任意的m块元素出错(包括数据和冗余出错)时,均可以通过对应的重构算法恢复出原来的k块数据。基于纠删码的方法与传统的副本冗余技术相比,具有冗余度低、磁盘利用率高等优点。
3 纠删码简述
3.1 纠删码中相关概念
数据块大小指的是数据块进行编码计算时,数据分块(原始数据块Di或校验数据块Cj)的大小,在不同的存储系统中数据块大小不同,在RAID存储系统中,常见的分块大小是4KB~128KB,在分布式存储系统中数据块较大,一般为64MB大小。
条带是纠错编码存储一次性读入或写入数据的大小,在系统码中,一个条带往往包含了k个原始数据块和m个校验块。
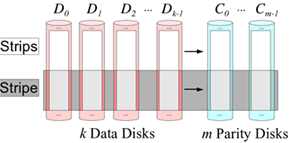
编码矩阵GM 定义了数据是如何编码为冗余数据的,因为纠删码的编码过程可以通过一个编码矩阵GM和分块数据的乘法(点积)来表示。以下图为例,C0 ~ C5 是冗余数据,所有的冗余数据可以表示为GM × D{D0、D1、D2、D3} 的乘法,每一个冗余数据块Ci 是矩阵的对应的一行和数据块的乘积(黄色标示)。编码矩阵中GM每一个元素则是对应原始数据块的乘法系数。编码矩阵的列数对应着原始数据分块个数(k),行数对应着编码后所有数据块个数(n)。
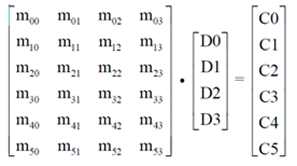
3.2 典型的纠删码类型
3.2.1 范德蒙RS纠删码
RS编码实际上就是利用生成矩阵与数据列向量的乘积来计算得到信息列向量的。其重构算法实际上也是利用未出错信息所对应的残余生成矩阵的逆矩阵与未出错的信息列向量相乘来恢复原始数据的。.但是在RS编码重构原理的推导过程中,有一个条件至关重要,那就是未出错信息所对应的残余生成矩阵在GF(2w)域上必须要满足可逆的条件。更进一步来说,为了满足RS编码在任何情况下均是可重构的,对于任意的ms个元素出错时,均要能够通过重构算法恢复出数据,这就要求对于任意的n个元素(n的含义是指去掉m个出错元素以后剩下的n个未出错的元素),其对应的残余生成矩阵均要在GF(2w)域上满足可逆,这就对RS编码的生成矩阵提出了很高的要求。在生成矩阵中, 要求任意n个行向量均必须在 GF(2w)域上满足线性无关(行向量线性无关是矩阵可逆的充要条件)。
范德蒙矩阵有着良好的特性,在GF(2w)域上,对范德蒙矩阵进行初等变换,将其前n行变为单位矩阵,即可保证生成矩阵可逆,基于这个生成矩阵的RS纠删码为范德蒙RS纠删码。其编码的生成矩阵为:

3.2.2 柯西RS纠删码
柯西RS纠删码用柯西矩阵代替范德蒙矩阵,得到更为简单的生成矩阵。研究者通过简单改造,使解码过程更为简单。柯西码解码不用求大矩阵的逆,而是把乘法除法运算分别转化为有限域上的加法和减法运算,可用异或实现。因此,柯西RS纠删码运算复杂度低于范德蒙RS纠删码。采用柯西矩阵进行 Erasure code 编码过程描述如下:

4 Ceph容错机制
4.1 传统容错机制
Ceph中采用的是副本冗余与纠删码冗余算法的综合容错机制。基于副本冗余策略,用户可以根据需要创建存储池,并设置存储池中数据的副本数目,每个数据副本被分到不同的对象存储设备(OSD)上,当存储设备中有故障,可以从其他健康的设备上获取数据。基于纠删码冗余策略,Ceph添加了几个开源的纠删码库,提供不同的纠删码算法,用户可根据需要选择纠删码算法类型,并创建相应的纠删码池。
4.2 基于冷热数据分层的容错机制
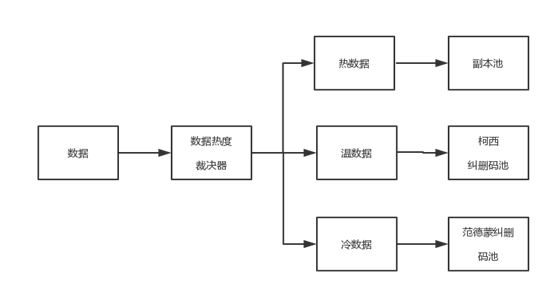
存储中数据可根据访问热度分为三种:热数据、温数据和冷数据。热数据通常需要在高性能、高度可用、高要求的环境下即时存取。温数据处于近线或在线备份环境中,用户需要快速访问这些数据,但访问的次数较少。冷数据通常访问次数极少,通常用于归档备份。针对云存储中数据访问热度不同,提出一种基于数据热度分层的容错机制。
所有数据先按照副本策略存储,本机制对存入系统的数据,实时统计该数据的被访问频率,设定热数据、温数据、冷数据阈值,高于热数据阈值的判断为热数据,低于冷数据阈值则判定为冷数据,在冷热数据阈值之间的判定为温数据。每3个月进行一次数据热度划分,数据被访问频率高于热数据阈值时,判断为热数据,存放在副本池里,该存储池采用副本容错机制。数据访问频率低于冷数据阈值时,判定为冷数据,存放在范德蒙RS纠删码池里,该存储池采用范德蒙RS纠删码容错机制。对于温数据,存放在柯西纠删码池里,该存储池采用改进的柯西RS纠删码容错机制。