Lex简介
Lex
- Lex 代表 Lexical Analyzar, 是一种用来构造词法分析器的工具。它本身也可以称为一个编译器。
- Lex读入词法分析器的规格说明,根据此说明,生成一个用c语言描述的词法分析器。
- 把描述词法分析器的规格说明的语言称为Lex 语言或词法分析器设计语言。
- 用Lex 语言书写的词法分析器规格说明称为Lex 源文件。
- 实用程序Lex 把Lex 源程序翻译成用c语言描述的目标程序,所以通常也称为Lex 编译器。
Lex工作原理
- 一种匹配的常规表达式可能会包含相关的动作。这一动作可能还包括返回一个标记。
- 当 Lex 接收到文件或文本形式的输入时,它试图将文本与常规表达式进行匹配。它一次读入一个输入字符,直到找到一个匹配的模式。
- 如果能够找到一个匹配的模式,Lex 就执行相关的动作(可能包括返回一个标记)。
- 另一方面,如果没有可以匹配的常规表达式,将会停止进一步的处理,Lex 将显示一个错误消息。
Lex 和 C的关系
- Lex 和 C 是强耦合的。一个 .lex 文件(Lex 文件具有 .lex 的扩展名)通过 lex 公用程序来传递,并生成 C 的输出文件。这些文件被编译为词法分析器的可执行版本。
Lex 编程
该部分大部分内容参考:https://sighingnow.github.io/%E7%BC%96%E8%AF%91%E5%8E%9F%E7%90%86/lex_yacc.html
各位博友可以移步该博客做进一步了解Lex和Yacc的相关内容,这里仅仅做了Lex部分的介绍
编程过程:
- 以 Lex 可以理解的格式指定模式相关的动作。
- 在这一文件上运行 Lex,生成扫描器的 C 代码。
- 编译和链接 C 代码,生成可执行的扫描器。
Lex程序的大致结构(三段):
declarations,第一段是 C 和 Lex 的全局声明
%%
translation rules,第二段包括模式(C 代码)
%%
auxiliary procedures,第三段是补充的 C 函数。一般都用main函数。
%%作为段与段之间分隔符号
lex 依次尝试每一个模式,尽可能地匹配最长的输入流。如果有一些内容根本不匹配任何模式,那么 lex 将只是把它拷贝到标准输出。
字符及其含义列表:
A-Z, 0-9, a-z 构成了部分模式的字符和数字。 . 匹配任意字符,除了 。 - 用来指定范围。例如:A-Z 指从 A 到 Z 之间的所有字符。 [ ] 一个字符集合。匹配括号内的 任意 字符。如果第一个字符是 ^ 那么它表示否定模式。 例如: [abC] 匹配 a, b, 和 C中的任何一个。 * 匹配 0个或者多个上述的模式。 + 匹配 1个或者多个上述模式。 ? 匹配 0个或1个上述模式。 $ 作为模式的最后一个字符匹配一行的结尾。 { } 指出一个模式可能出现的次数。 例如: A{1,3} 表示 A 可能出现1次或3次。 用来转义元字符。同样用来覆盖字符在此表中定义的特殊意义,只取字符的本意。 ^ 否定。 | 表达式间的逻辑或。 "<一些符号>" 字符的字面含义。元字符具有。 / 向前匹配。如果在匹配的模版中的“/”后跟有后续表达式,只匹配模版中“/”前 面的部分。 如:如果输入 A01,那么在模版 A0/1 中的 A0 是匹配的。 ( ) 将一系列常规表达式分组。
几个标记声明举例:
数字(number) ([0-9])+ 1个或多个数字
字符(chars) [A-Za-z] 任意字符
空格(blank) " " 一个空格
字(word) (chars)+ 1个或多个 chars
变量(variable) (chars)+(number)*(chars)*(number)*
Lex变量和函数:
- 一些常用的Lex变量如下所示:
yyin FILE* 类型。 它指向 lexer 正在解析的当前文件。 yyout FILE* 类型。 它指向记录 lexer 输出的位置。 缺省情况下,yyin 和 yyout 都指向标准输入和输出。 yytext 匹配模式的文本存储在这一变量中(char*)。 yyleng 给出匹配模式的长度。 yylineno 提供当前的行数信息。 (lexer不一定支持。)
- Lex函数:
yylex() 这一函数开始分析。 它由 Lex 自动生成。 yywrap() 这一函数在文件(或输入)的末尾调用。 如果函数的返回值是1,就停止解析。 因此它可以用来解析多个文件。 代码可以写在第三段,这就能够解析多个文件。 方法是使用 yyin 文件指针(见上表)指向不同的文件,直到所有的文件都被解析。 最后,yywrap() 可以返回 1 来表示解析的结束。 yyless(int n) 这一函数可以用来送回除了前 n 个字符外的所有读出标记。 yymore() 这一函数告诉 Lexer 将下一个标记附加到当前标记后。
- Lex内部预定义宏:
ECHO #define ECHO fwrite(yytext, yyleng, 1, yyout) 也是未匹配字符的默认动作。
一个简单的Lex例子(单词次数统计):
%{
/************************************************************
wc.l
Simple word count program. main is defined in the programs
section since the one in the library calls yyparse instead.
from Parser Generator Example
************************************************************/
int wc = 0; /* word count */
%}
%%
[a-zA-Z]+ { wc++; } // 前半部分是匹配,后半部分对应着动作,如果匹配着是一个单词,wc++
|. { /* gobble up */ } // 如果是换行和.就跳过
%%
int main(void)
{
int n = yylex();
return n;
}
int yywrap(void)
{
printf("word count: %d
", wc);
return 1;
}
Lex实现词法分析器
Parser Generator部分
- 创建一个新的项目
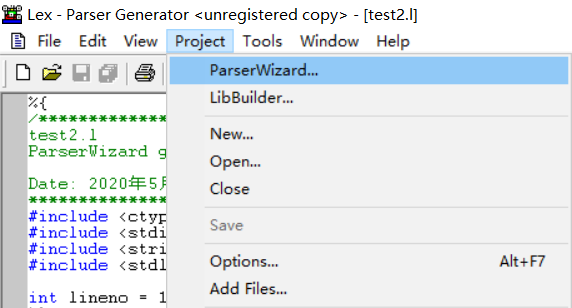
- 有关项目的选项设置
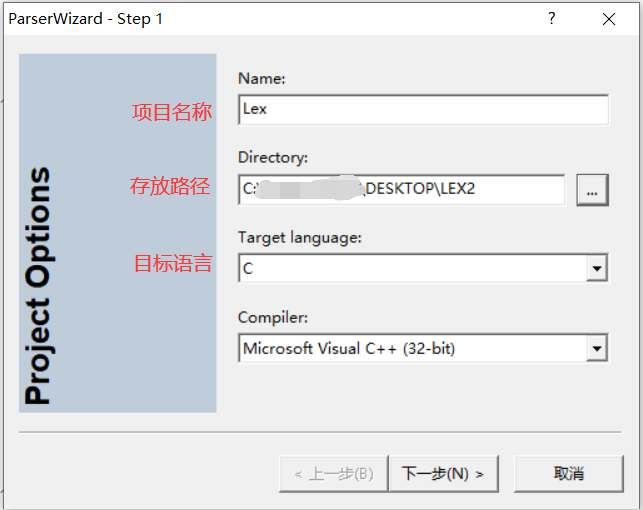
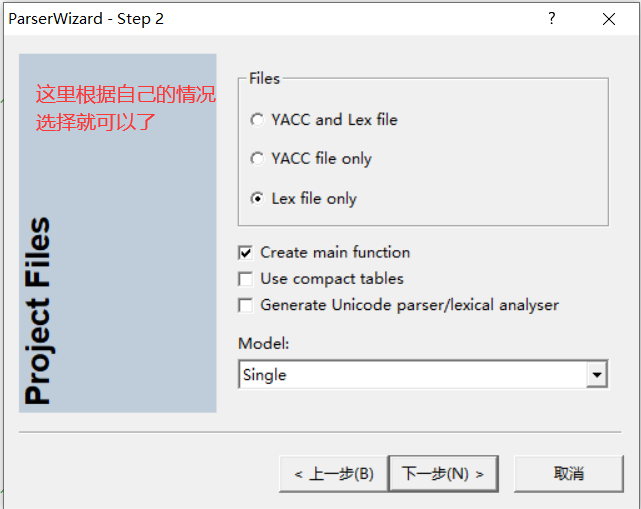
设置完后---下一步---完成
- 完成相关内容编写
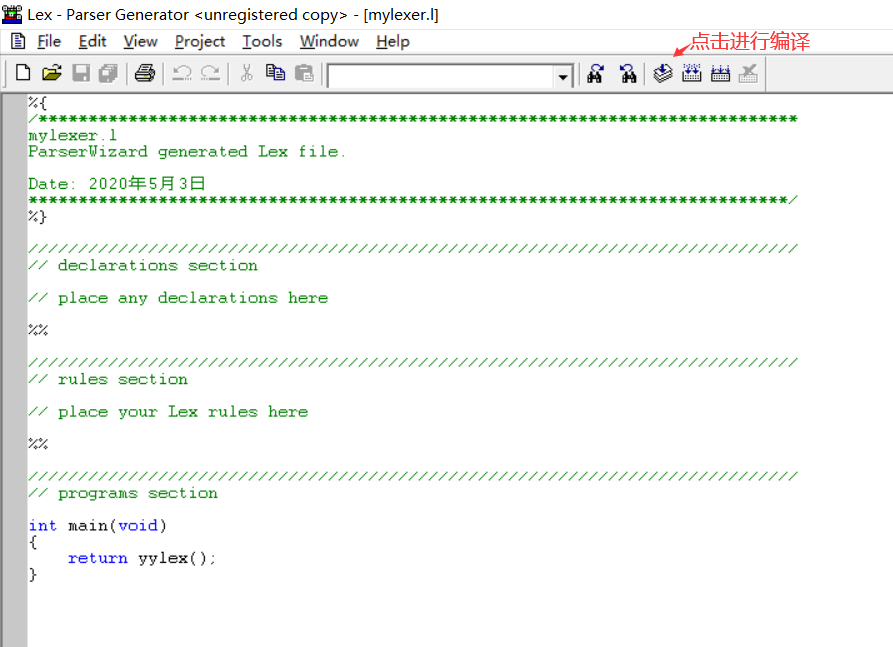
编译后在该项目的路径下生成.h和.c文件,将这两个文件导入VC++中创建的项目中进行后续操作。
VC++部分
- 将上述生成的两个.h和.c文件导入创建好的项目
- 下边的配置参考一下文章完成:VC+ +中 YACC 编译器的应用,张文彬 张晓芳(华中科技大学 湖北 武汉 430074)
- 目录设置
在 VC++中执行以下步骤 每个步骤只需执行一次 ( 1) 选择 Tools 菜单中的 Options 命令 在屏幕上即会出现 Options 对话框 ( 2) 选择 Directories 选项卡 ( 3) 在 ShoW Directories for 下拉列表框中选择 Include Files ( 4) 在 Directories 框中 点击最后的空目录 并填入 Parser generator 的 include 子目录的路径 ( 5) 在 ShoW Directories for 下拉列表框中选择 Library Files ( 6) 在 Directories 框中 点击最后的空目录 并填入 Parser generator 的 libmsdev 子目录的路径 ( 7) 在 ShoW Directories for 下拉列表框中选择 Source Files ( 8) 在 Directories 框中 点击最后的空目录 并填入 Parser generator 的 source 子目录的路径 ( 9) 点击 OK 按钮 Options 对话框将接受设置并关闭VC+ + 现在就可以找到包含文件 yacc. h 和 lex. h 以及 YACC 和 Lex 的库文件。
- 项目设置
对于每个 VC+ + 项目, 都需在 VC+ + 中执行以下步骤, ( 1) 选择 Project 菜单中的 Settings 命令, 在屏幕上即会出现 Project Settings 对话框, ( 2) 在 Settings for 下拉列表框中选择 Win32 Debug, ( 3) 选择 C/C+ + 标签, ( 4) 在 Category 下拉列表框中选择 General, ( 5) 在 Preprocessor Definitions 框中, 在当前文本的最后, 输入 YYDEBUG, ( 6) 选择 Link 标签, ( 7) 在 Category 下拉列表框中选择 General, ( 8) 在 Object/Library Modules 框 中, 在 当 前 文 本 的 后 面, 输 入 yld.lib ylmtd.lib ylmtdlld.lib, ( 9) 在 Settings for 下拉列表框中选择 Win32 Release, ( 10) 重复第8步的工作, ( 11) 点击 OK 按钮, Project Settings 对话框将接受设置并关闭。