上午刚入手的小说,下午心血来潮想从网站上拉取下来做成电子书,呵呵,瞎折腾~说做就做~
【抓包】
这一步比什么都重要,如果找不到获取真正资源的那个请求,就什么都不用做了~
先是打算用迅雷把所有页面都下载下来然后本地处理,结果发现保存下来的页面都只有界面没有内容~看了看Javascript的代码,原来是ready的时候再ajax发送post到另一个网址取内容。
于是再抓包核实一下。抓包工具真难搞,试了两三个都没成功,最后还是用firefox搞定了~打开页面共发送了50个请求,不过post只有两个,很快就看到http包的内容了。
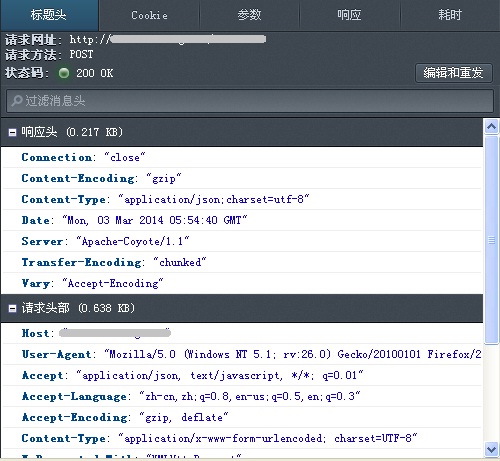
【写程序拉取】
网址,请求的header,表单 都具备了,还等什么,赶紧码字爬取啦~本来还担心要伪装浏览器,要填入cookies内容,调试起来发现是想太多了,直奔网址带上表单就够了~
HttpClient的用法是现炒现卖,官方example的QuickStart.java就够很清晰了。再有就是debug进去看请求和响应。
用法见HttpPost和crawlOnePage(HttpRequestBase)。MyFileWriter就不贴出来献丑了,反正就是个I/O。
遇到并解决的问题:
1.响应回来的资源是gzip压缩过的,要用对应的类去解码;
2.网址序列号中个别缺页,通过判断响应里的状态码跳过即可。
(全文完,以下是代码。)
1 package mycrawl; 2 3 import java.io.IOException; 4 import java.util.ArrayList; 5 import java.util.List; 6 7 import org.apache.http.HttpEntity; 8 import org.apache.http.NameValuePair; 9 import org.apache.http.client.ClientProtocolException; 10 import org.apache.http.client.entity.GzipDecompressingEntity; 11 import org.apache.http.client.entity.UrlEncodedFormEntity; 12 import org.apache.http.client.methods.CloseableHttpResponse; 13 import org.apache.http.client.methods.HttpPost; 14 import org.apache.http.client.methods.HttpRequestBase; 15 import org.apache.http.impl.client.CloseableHttpClient; 16 import org.apache.http.impl.client.HttpClients; 17 import org.apache.http.message.BasicNameValuePair; 18 import org.apache.http.util.EntityUtils; 19 20 import crawl.common.MyFileWriter; 21 22 public class MyCrawl { 23 24 private static CloseableHttpClient httpclient = HttpClients.createDefault(); 25 26 /** 27 * (1)建立post对象,包括网址和表单 (2)循环抓取每页并处理输出 28 * 29 * @param args 30 * @throws IOException 31 */ 32 public static void main(String[] args) throws IOException { 33 final int startChapter = 页面序列号; 34 final int endChapter = 页面序列号;
35 final Integer bookId = bookid; 36 String outPattern = "c:\book*.txt"; 37 MyFileWriter fw = new MyFileWriter(outPattern); 38 39 // 创建post操作 40 HttpPost httpPost = new HttpPost("网址"); 41 List<NameValuePair> nvps = new ArrayList<NameValuePair>(2); 42 43 try { 44 // post的表单内容 45 nvps.add(new BasicNameValuePair("b", bookId.toString())); 46 nvps.add(new BasicNameValuePair("c", "placeholder")); 47 48 for (Integer i = startChapter, j = 0; i <= endChapter; i++, j++) { 49 // 循环抓取连续章节 50 nvps.set(1, new BasicNameValuePair("c", i.toString())); 51 httpPost.setEntity(new UrlEncodedFormEntity(nvps)); 52 53 String outStr = MyCrawl.crawlOnePage(httpPost); 54 if (outStr == null || outStr.isEmpty()) { 55 j--; 56 continue; 57 } 58 // 处理章节标题,懒得去抓取标题页了。 59 outStr = "====== " + MyCrawl.chapterArr[j] + " " 60 + MyCrawl.prettyTxt(outStr); 61 // System.out.println(outStr); 62 fw.rollingAppend(outStr); 63 } 64 fw.getFileWriter().flush(); 65 fw.getFileWriter().close(); 66 System.out.println("已完成"); 67 68 } finally { 69 httpclient.close(); 70 } 71 } 72 73 /** 74 * 抓取单页 75 * 76 * @param req 77 * @return result 78 * @throws ClientProtocolException 79 * @throws IOException 80 */ 81 public static String crawlOnePage(HttpRequestBase req) 82 throws ClientProtocolException, IOException { 83 84 String result; 85 CloseableHttpResponse resp = httpclient.execute(req); 86 87 // 处理返回码 88 int status = resp.getStatusLine().getStatusCode(); 89 if (status < 200 || status >= 300) { 90 System.out.println("[Error] " + resp.getStatusLine().toString()); 91 return ""; 92 } else if (status != 200) { 93 System.out.println("[Warn] " + resp.getStatusLine().toString()); 94 return ""; 95 } 96 97 HttpEntity entity = resp.getEntity(); 98 if (entity instanceof GzipDecompressingEntity) { 99 // 解压缩内容 100 GzipDecompressingEntity gEntity = (GzipDecompressingEntity) entity; 101 result = EntityUtils.toString(gEntity); 102 } else { 103 result = EntityUtils.toString(entity); 104 } 105 106 EntityUtils.consume(entity); 107 resp.close(); 108 return result; 109 } 110 111 /** 112 * 处理换行等特殊字符 113 * 114 * @param txt 115 * @return string 116 */ 117 public static String prettyTxt(String txt) { 118 if (txt == null || txt.isEmpty()) { 119 return ""; 120 } 121 int contentStart = txt.indexOf("content") + 10; 122 int contentEnd = txt.indexOf(" <br/><br/> ","next"); 123 txt = txt.substring(contentStart, contentEnd); 124 return txt.replace("<br/><br/>", " "); 125 } 126 127 // 章节标题 128 private static final String[] chapterArr = new String[] { "第一章", 129 "第二章" }; 130 131 }