l 数据血缘关系(data lineage)
数据血缘属于数据治理中的一个概念,是在数据溯源的过程中找到相关数据之间的联系,它是一个逻辑概念。数据治理中经常提到血缘分析,血缘分析是保证数据融合的一个手段,通过血缘分析实现数据融合处理的可追溯。数据血缘是指数据产生的链路,直白点说,就是我们这个数据是怎么来的,经过了哪些过程和阶段。
l SQLFlow是什么?
SQLFlow 通过分析各种数据库对象定义(DDL)语句、数据操作(DML) 语句、ETL/ELT中使用的存储过程(Proceudre,Function)、 触发器(Trigger)和其他 SQL 脚本,给出完整的数据血缘关系。它不仅可以展现对象间的关系,也可以帮你提取表的字段。
参考链接:https://sqlflow.gudusoft.com/?utm_source=cnblogs&utm_medium=blog&utm_campaign=my-nick-name#/
l 示例说明
新建表
CREATE TABLE Test1(ID INT,NAME VARCHAR(36));
CREATE TABLE Test2(ID INT,NAME VARCHAR(36));
新建视图
CREATE VIEW v_test1 AS SELECT A.NAME FROM Test1 A;
CREATE VIEW v_test2 AS SELECT A.* FROM Test1 A,Test2 B WHERE A.ID=B.ID;
CREATE VIEW v_test3 AS SELECT A.*,b.* FROM Test1 A,Test2 B WHERE A.ID=B.ID;
默认情况下仅显示Dataflow,即数据流,可以从图中清晰的看到每个视图中的具体列是由哪里流过来的。

l 视图v_test1仅包含来源于Test1的name列;
l 视图v_test2包含来源于Test1的ID,name列,虽在视图定义中和Test2进行了关联,但是由于数据全部来源于Test1,所以在Dataflow中并不体现;
l 视图v_test3包含来源于Test1和Test2中所有列。
看到此处,您可能疑惑,视图v_test2展现的虽然只是来源于Test1的数据,但是如果您想了解Test1和Test2是否有关联逻辑,该如何做?
打开【Setting】-【impact】选项,可以看到具体的表间的逻辑关系。
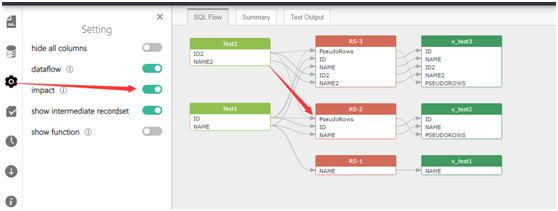
说明:
l SQLFlow数据流使用【实线】显示,逻辑关系使用【虚线】显示;
l 此时的关系集合中多了一个伪列(PseudoRows),用于表示该数据集合是由多表关联而来。
此时您能够更加清晰的看到数据血缘关系以及各原表间的关联关系。