SQLFlow是一款专业的数据血缘关系分析工具,在大型数据仓库中,完整的数据血缘关系可以用来进行数据溯源、表和字段变更的影响分析、数据合规性的证明、数据质量的检查等。
一、SQLFlow 是怎样工作的
- 从数据库、版本控制系统、文件系统中获取 SQL 脚本。
- 解析 SQL 脚本,分析其中的各种数据库对象关系,建立数据血缘关系。
- 以各种形式呈现数据血缘关系,包括交互式 UI、CSV、JSON、GRAPHML 格式。
二、SQLFlow 的组成
- Backend, 后台由一系列 Java 程序组成。负责 SQL 的解析、数据血缘分析、可视化元素的布局、身份认证等。
- Frontend,前端由一系列 javascript、html 代码组成。负责 SQL 的递交、数据血缘关系的可视化展示。
- Grabit 工具,一个 Java 程序。负责从数据库、版本控制系统、文件系统中收集 SQL 脚本,递交给后台进行数据血缘分析。
- Restful API,一套完整的 API。让用户可以通过 Java、C#、Python、PHP 等编程语言与后台进行交互,完成数据血缘分析。
三、在线工具连接:https://sqlflow.gudusoft.com/?utm_source=cnblogs&utm_medium=blog&utm_campaign=my-nick-name#/
四、SQLFlow的job功能
1、job能做什么
SQLFlow的job功能是为客户提供的固定血缘追溯场景所设计的,比如你有多个固定的分析逻辑,需要在工作中反复使用,此时你只需要根据具体的分析需求进行设置job即可。该job产生的逻辑关系图属于静态的,不会虽仓库中对象结构变化而变化,这样可以更好的帮助您进行版本追溯及管理。

上图中,做数字标记的job作业,属性1是在工具右侧面板上显示job分析的逻辑关系图,属性2可以分享该job,属性3是删除该job。
2、如何创建job
如下图所示:从工具job功能导航到job list页面,点击【upload】进行Create Job;
其中,sql source的可选来源有三种:upload file、from database、upload file+from database
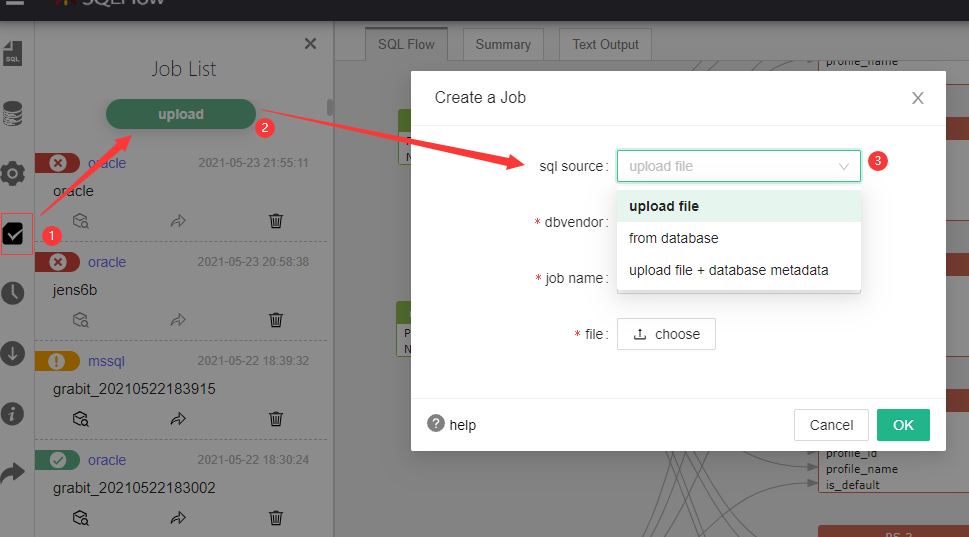
这里以常用的from database方式做Create Job演示:
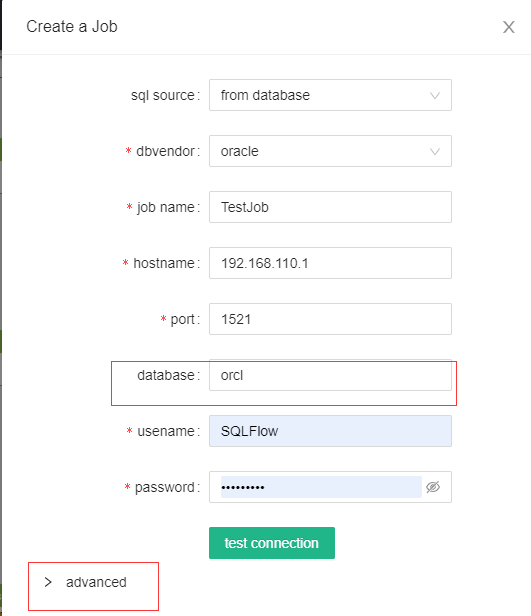
下图中,是Create Job需要填写的相关信息,其中*为必填项,有些数据库的database属性不是必填项,所以他不属于必填项。
dbvendor:需要选择的数据库种类;
job name:一个自定义的好记的job名称
hostname:IP或机器名
port:端口号
database:catalog name,即dbname。
usename:用户名
password:密码
【test connection】可以帮助您进行连接测试。
advanced的选项如下:
extractedDbsSchemas:所提取的特定schema
excludedDbsSchemas:包含的schema
extractedStoredProcedures:所提取的存储过程名称
extractedViews:所提取的视图名称
备注:高级选项都不是必填项!

当您所有信息填写正确后,点击【OK】即可成功创建job。
谢谢!