requests的Cookie处理
有时相关的需求会让我们去爬取基于某些用户的相关用户信息,例如爬取张三人人网账户中的个人身份信息、好友账号信息等。
那么这个时候,我们就需要对当前用户进行登录操作,登录成功后爬取其用户的相关用户信息。
在浏览器中我们可以很便捷的进行用户登录操作,但是使用requests模块如何进行模拟浏览器行为的登录操作呢?
以爬取人人网的个人信息为例
需求:对人人网进行模拟登录
- 点击登录按钮之后会发起一个post请求
- post请求中会携带登录之前录入的相关的登录信息(用户名,密码,验证码......)
- 验证码:每次请求都会变化
如果直接用requests发起请求,你会发现页面并没有拿到数据
没有请求到对应页面数据的原因:
http/https协议特性:无状态保存,即每一次请求之间都是独立的。发起的第二次基于个人主页页面请求的时候,服务器端并不知道该此请求是基于登录状态下的请求。
因此就要通过会话跟踪技术,即Cookie、Session,来让服务器知道用户的状态信息。
无状态HTTP
HTTP的无状态指的是http协议对事物处理是没有记忆能力的,也就是说服务器不知道客户端是什么状态。
当我们向服务器发送请求后,服务器解析此请求,然后返回对应的响应,服务器负责完成这个过程,而且这个过程是完全独立的,服务器不会记录前后状态的变化,也就是缺少状态记录。
这就意味着如果后续需要处理前面的信息,则必须重传,这导致需要额外传递一些前面的重复请求,才能获取后续响应,然而这种效果显然不是我们想要的。
为了保持前后状态,我们肯定不能将前面的请求全部重传一次,这太浪费资源了,对于这种需要用户登录页面来说,更是棘手。
这时两个保持http连接状态的技术出现了,分别是会话和cookie。会话在服务端,用来保存用户的会话信息。
cookie在客户端,有了cookie,浏览器在下次访问网页时会自动附带上cookie发送给服务器,服务器识别cookie并鉴定出是哪个用户,然后在判断出用户的相关状态,然后返回对应的响应。
会话:会话(对象)是用来存储特定用户进行会话所需的属性及配置信息的。
cookie:指的是某些网站为了辨别用户身份、进行会话跟踪而存储在用户本地终端上的数据。
会话维持:当客户端第一次请求服务器时,服务器会返回一个响应对象,响应头中带有Set-Cookie字段,cookie会被客户端进行存储,该字段表明服务器已经为该客户端用户创建了一个会话对象,用来存储该用户的相关属性机器配置信息。当浏览器下一次再请求该网站时,浏览器会把cookie放到请求头中一起提交给服务器,cookie中携带了对应会话的ID信息,服务器会检查该cookie即可找到对应的会话是什么,然后再判断会话来以此辨别用户状态。
形象案例:当iphone用户第一次向iphone的售后客服打电话咨询相关问题时,售后客服会针对当前用户创建一个唯一的“问题描述”,用来记录当前用户的iphone产品出现的相关问题,然后当用户阐述清楚问题后,售后客服就会将问题记录在所谓的“问题描述”中,并将“问题描述”的唯一编号通过短信告诉该用户。这样的好处就是,下次该用户的产品再次出现问题向售后电话咨询时,提供了“问题描述”的唯一编码后,就不需要在将该产品之前的问题再次进行描述了。此案例中,“问题描述”就相当于是会话,“问题描述”的唯一编码就是会话ID,短信就是cookie。
cookie:用来让服务器端记录客户端的相关状态。
1 . 手动处理:通过抓包工具获取cookie值,将该值封装到headers中。(不建议)
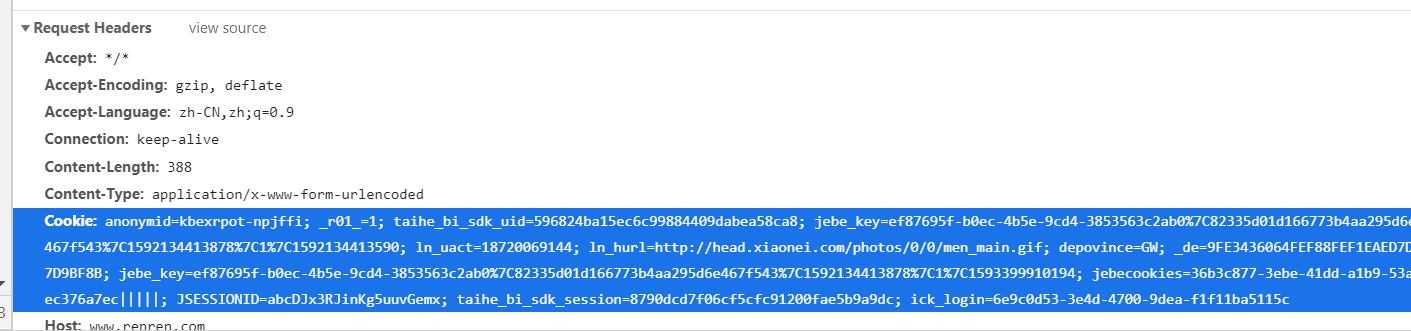
2 . 自动处理:
- cookie值的来源是哪里?
- 模拟登录post请求后,由服务器端创建。
session会话对象:
- 作用:
1.可以进行请求的发送。
2.如果请求过程中产生了cookie,则该cookie会被自动存储/携带在该session对象中。
- 创建一个session对象:session = requests.Session()
- 使用session对象进行模拟登录post请求的发送(cookie就会被存储在session中)
- session对象对个人主页对应的get请求进行发送(携带了cookie)
流程分析
1.进入个人页面,打开抓包工具,找到含登陆信息的包,找到应该请求的url,以及对应携带的参数。
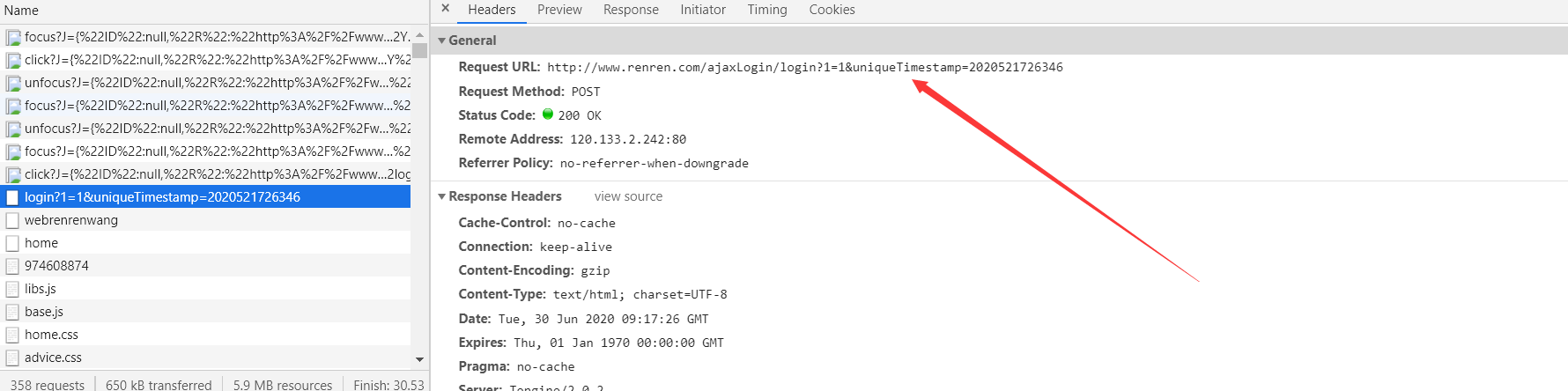
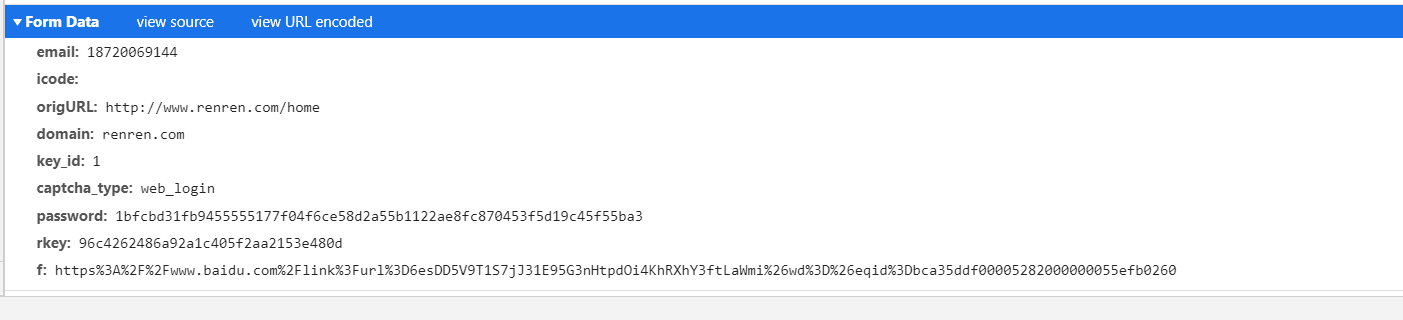
2. 登陆成功后,向个人中心的url发送请求,抓取对应的数据。
代码实现
验证码识别平台 rec_code.py
import json import requests import base64 from io import BytesIO from PIL import Image from sys import version_info def base64_api(uname, pwd, img): img = img.convert('RGB') buffered = BytesIO() img.save(buffered, format="JPEG") if version_info.major >= 3: b64 = str(base64.b64encode(buffered.getvalue()), encoding='utf-8') else: b64 = str(base64.b64encode(buffered.getvalue())) data = {"username": uname, "password": pwd, "image": b64} result = json.loads(requests.post("http://api.ttshitu.com/base64", json=data).text) if result['success']: return result["data"]["result"] else: return result["message"] return "" if __name__ == "__main__": img_path = "C:/Users/Administrator/Desktop/file.jpg" img = Image.open(img_path) result = base64_api(uname='你的账号', pwd='你的密码', img=img) print(result)
爬虫文件
import requests from lxml import etree from PIL import Image from requests_highlevel import rec_code url = 'http://www.renren.com/SysHome.do' session = requests.Session() # Cookie让服务器保存客户端的相关状态 # session对象可以发送请求 如果请求过程中产生了Cookie 会保存在session对象中 # 则用session发送请求就可以自动携带cookie headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36', }
# 将验证码图片下载到本地 page_text = requests.get(url=url, headers=headers).text tree = etree.HTML(page_text) img_src = tree.xpath('//*[@id="verifyPic_login"]/@src')[0] img_data = requests.get(url=img_src,headers=headers).content with open('./code.jpg','wb') as f: f.write(img_data) # 利用三方平台识别验证码 img_path = "code.jpg" img = Image.open(img_path)
result = rec_code.base64_api(uname='Mrterrific', pwd='WQ2017617sxy', img=img) post_url = 'http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=2020501933720' data= { "email": "用户名", "password": "密码", "icode": result, "origURL":"http://www.renren.com/home", "domain": "renren.com", "key_id": "1", "captcha_type": "web_login", "f": "http%3A%2F%2Fwww.renren.com%2F974608874%2Fnewsfeed%2Fphoto" } response = session.post(url=post_url,data=data,headers=headers) print(response.status_code) homr_url = 'http://www.renren.com/974608874' home_text = session.get(url=url,headers=headers).text # http无状态保存 session携带了Cookie with open('home.html','w',encoding='utf-8') as f: f.write(home_text)
代理IP操作
我们在做爬虫的过程中经常会遇到这样的情况,最初爬虫正常运行,正常抓取数据,一切看起来都是那么美好,然而一杯茶的功夫可能就会出现错误,比如403,
这时打开网页一看,可能会看到“您的IP访问频率太高”这样的提示。出现这种现象的原因是网站采取了一些反爬措施。
比如,服务器会检测某个IP在单位时间内请求的次数,如果超过了某个阈值,就会直接拒绝服务,返回一些错误信息,这种情况可以称为封IP。
既然服务器检测的是某个IP单位时间的请求次数,那么借助某种方式来伪装我们的IP,让服务器识别不出是由我们本机发起的请求,不就可以成功防止封IP了吗?一种有效的方式就是使用代理。
什么是代理?
代理实际上指的就是代理服务器,它的功能就是代理网络用户去取得网络信息。形象的说,它是网络信息的中转站。
在我们正常请求一个网站时,是发送了请求给Web服务器,Web服务器把响应传回我们。如果设置了代理服务器,实际上就是在本机和服务器之间搭建了一个桥梁,
此时本机不是直接向Web服务器发起请求,而是向代理服务器发出请求,请求会发送给代理服务器,然后代理服务器再发送给Web服务器,接着由代理服务器再把Web服务器返回的响应转发给本机。
这样我们同样可以正常访问网页,但这个过程中Web服务器识别出的真实IP就不再是我们本机的IP了,就成功实现了IP伪装,这就是代理的基本原理。
代理的作用
突破自身IP访问的限制,访问一些平时不能访问的站点。
隐藏真实IP,免受攻击,防止自身IP被封锁。
相关代理网站
快代理
西祠代理
www.goubanjia.com
代理ip的类型:
- http:应用到http协议对应的url中
- https:应用到https协议对应的url中
代理ip的匿名度:
- 透明:服务器知道该次请求使用了代理,也知道请求对应的真实ip
- 匿名:知道使用了代理,不知道真实ip
- 高匿:不知道使用了代理,更不知道真实的ip
import requests import random if __name__ == "__main__": #不同浏览器的UA header_list = [ # 遨游 {"user-agent": "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)"}, # 火狐 {"user-agent": "Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1"}, # 谷歌 { "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"} ] #不同的代理IP proxy_list = [ {"http": "112.115.57.20:3128"}, {'http': '121.41.171.223:3128'} ] #随机获取UA和代理IP header = random.choice(header_list) proxy = random.choice(proxy_list) url = 'http://www.baidu.com/s?ie=UTF-8&wd=ip' #参数3:设置代理 response = requests.get(url=url,headers=header,proxies=proxy) response.encoding = 'utf-8' with open('daili.html', 'wb') as fp: fp.write(response.content)