

功能:通过xpath爬取彼岸图网的高清美女壁纸
url = 'http://pic.netbian.com/4kmeinv/'
1. 通过url请求整张页面的数据
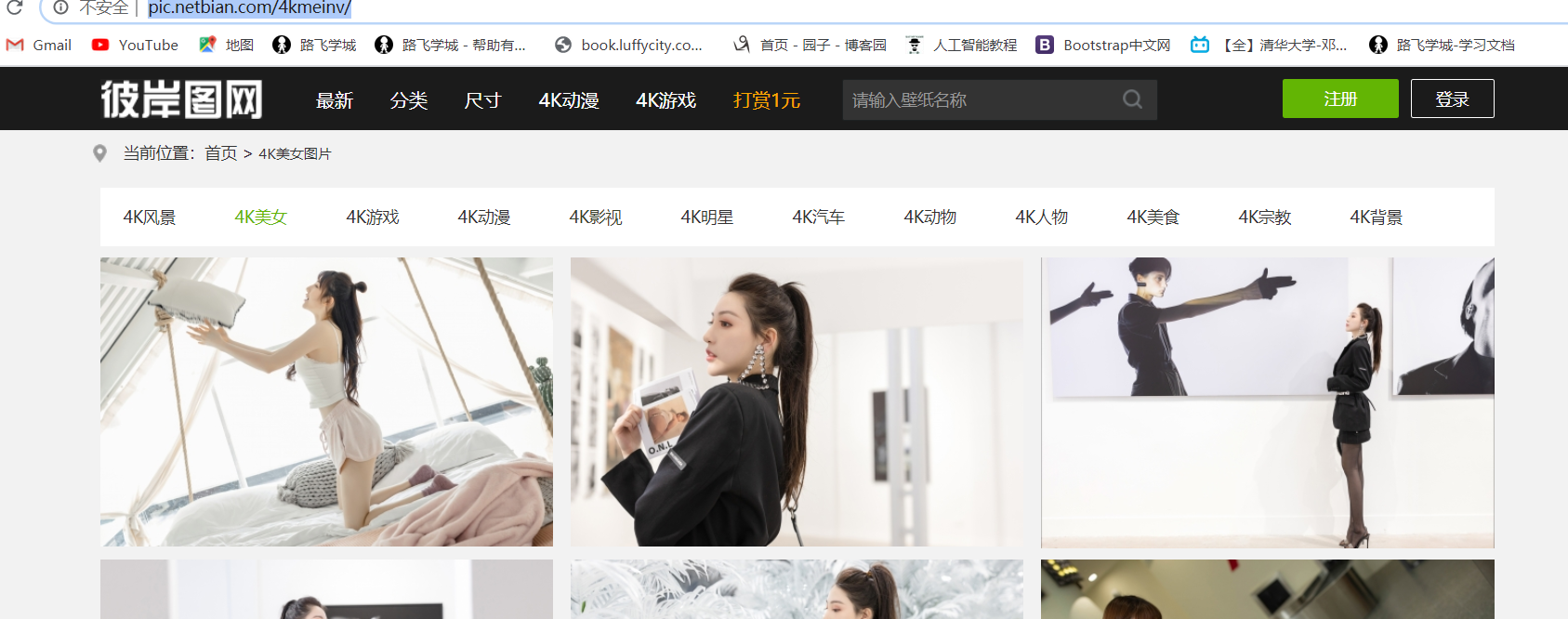
2.通过页面的标签定位图片所在的位置
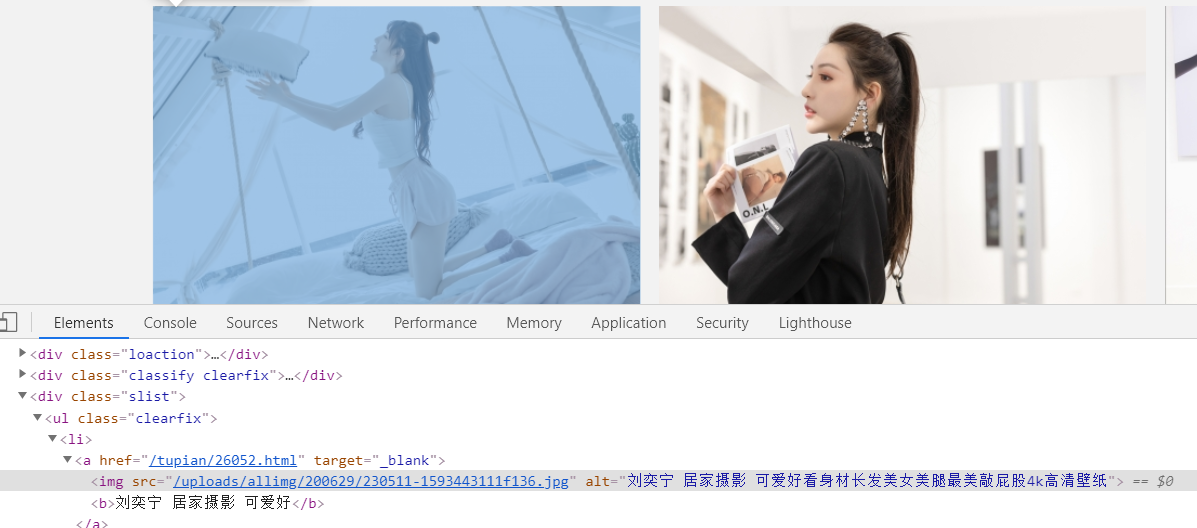
3.找到所有图片的通用的标签
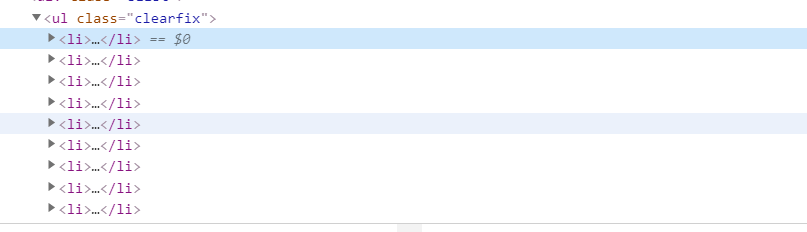
向图片标签的父级查找,可以发现每一张图片都在ul下的li标签下。
4.知道每一个li标签下图片所处的位置
5.思路:通过url拿到整张页面的数据,通过etree进行标签定位,拿到所有的li标签,再循环对每一个li标签下的每一个图片发送请求,拿到图片。
import requests from lxml import etree import os import time if not os.path.exists('./4kPic'): os.makedirs('./4kPic') url ='http://pic.netbian.com/4kmeinv/' headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36', } response = requests.get(url=url,headers=headers)
# 获取网页所有数据 page_text = response.text
# 实例化etree对象 tree = etree.HTML(page_text)
# 找到所有的li标签 li_list = tree.xpath("//div[@class='slist']/ul/li")
# 遍历所有li标签 for li in li_list:
# 局部解析用./表示当前的li标签 img_src = li.xpath('.//img/@src')[0] # 获取图片路径 img_alt = li.xpath('.//img/@alt')[0] # 获取图片名称
# 解决中文乱码问题的通用方式 img_name = img_alt.encode('iso-8859-1').decode('gbk')
# 获取图片完整路径 img_url = 'http://pic.netbian.com'+img_src
try:
# content获取图片的二进制数据 文件传输都是以二进制的形式 img_data = requests.get(url=img_url, headers=headers).content except requests.exceptions.ConnectionError: time.sleep(1) # 数据请求过快会请求失败 可以time.sleep continue
fileName = img_name+'.jpg' with open('4kPic/'+fileName,'wb') as f: f.write(img_data) print(img_name+'--------------爬取成功')
注:解决中文乱码问题的方式
方式1:
response.encoding='utf-8' 有些数据不能直接用utf8编码 这不是一种通用的方式
方式2:
img_name = img_alt.encode('iso-8859-1').decode('gbk') 这种为通用方式