requests模块简介
requests模块:python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高。
作用:模拟浏览器发请求。
requests模块的编码流程
- 指定url
- UA伪装
- 请求参数的处理
- 发起请求
- 获取响应数据
- 持久化存储
UA伪装
User-Agent:请求载体的身份标识,使用浏览器发起的请求,请求载体的身份标识为浏览器,使用爬虫程序发起的请求,请求载体为爬虫程序。
UA检测:相关的门户网站通过检测请求该网站的载体身份来辨别该请求是否为爬虫程序,如果是,则网站数据请求失败。
因为正常用户对网站发起的请求的载体一定是基于某一款浏览器,如果网站检测到某一请求载体身份标识不是基于浏览器的,则让其请求失败。
因此,UA检测是我们整个课程中遇到的第二种反爬机制,第一种是robots协议。
UA伪装:通过修改/伪装爬虫请求的User-Agent来破解UA检测这种反爬机制.
那么如何进行UA伪装?
打开一个页面右击检查,然后打开抓包工具

打开一个包,然后在Headers中找到User-Agent对应的值
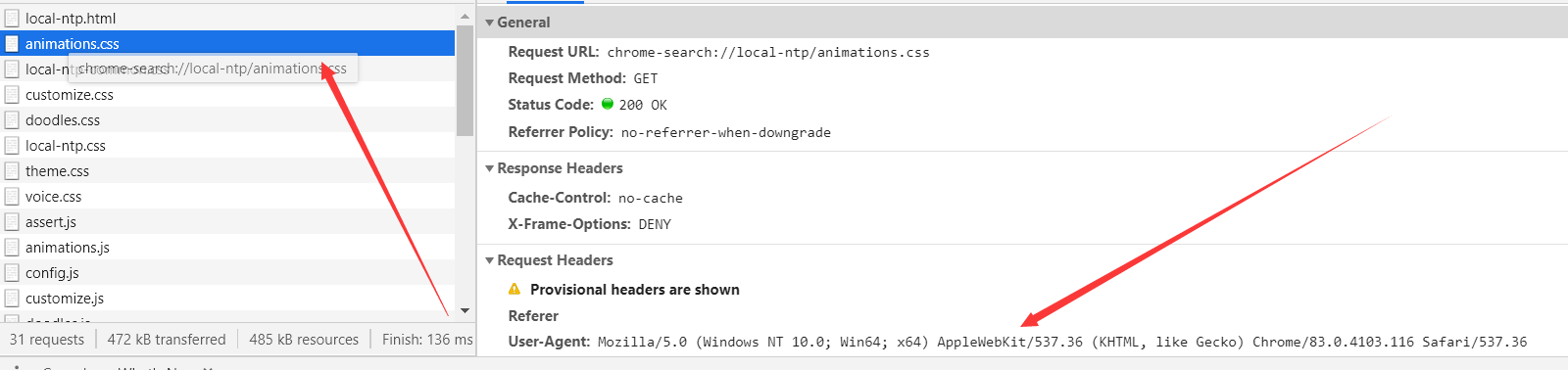
User-Agent就是当前浏览器的身份标识,在发送请求时,对其进行替换,就可以模拟浏览器发送请求以避开UA检测。
示例1 爬虫一血
import requests # 获取网址 url = 'https://www.sogou.com/' # 发送请求 返回一个响应对象 response = requests.get(url=url) # 返回一个字符串格式的响应数据 page_info = response.text # # 持久化存储 with open('files/sogou.html','w', encoding='utf-8') as f: f.write(page_info) print('work is done')
示例2 一个简单的网页采集器
功能: 运行程序 输入关键字 可在files/关键字.html中得到对应的网页文本数据
import requests url = 'https://www.sogou.com/web' key_word = input('Please enter a word: ') # 输入关键字 # UA伪装 伪装成浏览器发送请求 headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36', } # url 携带的参数放入字典中 param = { 'query':key_word } response = requests.get(url=url, params=param, headers=headers) # 向指定url发送请求 并携带所需参数以及对应的附加的头信息 page_info = response.text # 获取网页的文本数据,即源码 fileName = 'files/'+key_word+'.html' with open(fileName,'w', encoding='utf-8') as f: f.write(page_info) print('work is done')
示例3 破解百度翻译
功能:输入中文,获取对应的英文翻译,并以json格式返回并持久化存储。
页面如此

当你输入之后,会发现网页不会刷新,说明翻译是一个ajax请求
打开抓包工具,找到ajax请求的包

这里可能会有多个sug包,找到data中的'k'的值为你输入的值的包
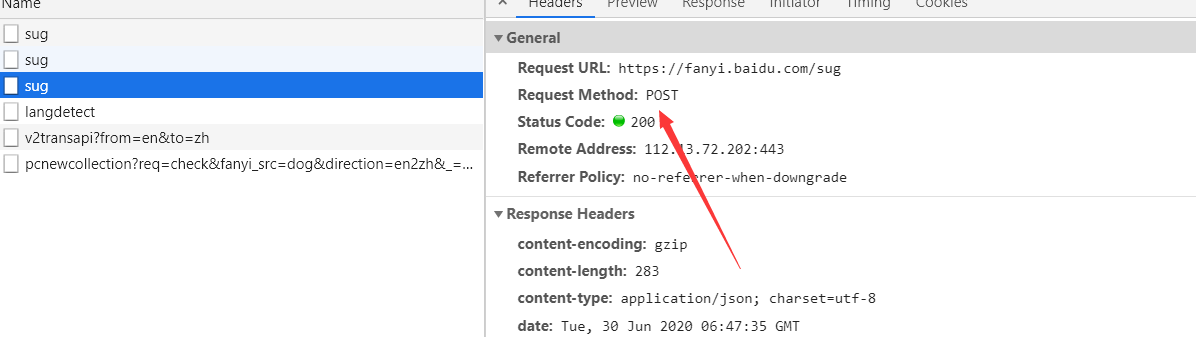
可以看到这里的请求是post请求,那么当你使用requests时也应该使用requests请求

在这个页面的底部会有对应的参数,那么在编写代码时要加上对应的参数。
import requests import json url = 'https://fanyi.baidu.com/sug' # UA伪装 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36' } data = input('Enter a word: ') # 抓包工具中的Hearders 中的Form Data信息 params = { 'kw': data } response = requests.post(url=url, data=params, headers=headers) # 拿到dict对象 在确定服务器返回json数据时使用 dict_obj = response.json() fileName = 'files/'+data + '.json' f = open(fileName, 'w', encoding='utf-8') info_obj = json.dump(dict_obj, f, ensure_ascii=False) # 中文不能用ascii码编码 应将ensure_ascii设为False # with open(fileName,'w',encoding='utf-8') as f: # f.write(json.dumps(dict_obj,ensure_ascii=False)) print('working is done')
至此,破解百度翻译完成。