1.对数据库数据的计数统计,尽量在数据库查询时候就使用count()进行统计,避免返回List到项目中统计List大小
2.对于数据库中表中字段数据过长,例如存储的是text类型而不是verchar类型的,可以创建新的实体去接收mybatis的查询结果,返回部分要用到的数据即可,不用将一整条数据全部返回给项目
3.对于List的分割操作,可以避免使用subList()方法进行分割,因为subList()会创建新的List集合去接收分割结果,内存开销大。可以使用remove仅操作原List完成分割。
参考地址:【https://www.cnblogs.com/sxdcgaq8080/p/9376947.html】
4.在保证代码命名可以有效看懂的情况下,尽量减少源代码的码量,从细微的地方减少编译后class文件的大小。
5.而减少编译后class文件大小的最有效的方法,就是1》代码逻辑清晰,程序流程设计完美,是最有效减少码量的方法 2》尽量抽离重复代码,提高代码的高可用行,也是减少码量的不二法门
6.mybatis的IN查询,如果list过大,应该进行List的切割,IN查询分批次查询,避免拼接sql语句过长
7.mybatis sql查询时,尽量少使用
where 1=1
<if> and ......</if>
因为1=1写在where第一位,则数据表中如果有索引的话,那根据最左原则,表上创建的Index就失效了。
优化方案:https://www.cnblogs.com/sxdcgaq8080/p/9412167.html
8.java中使用StringBuffer进行append操作时,需要注意:
方式1:
for (String s : split) { // public static final String LINE_FEED_CHAR = System.getProperty("line.separator"); StringBuffer content = new StringBuffer(); content.append(s + SecurityCodeBusinessOrderServiceImpl.LINE_FEED_CHAR); }
效率要比下面这种效率高:
方式2:
content.append(s).append(SecurityCodeBusinessOrderServiceImpl.LINE_FEED_CHAR);
原因是因为:
SecurityCodeBusinessOrderServiceImpl.LINE_FEED_CHAR
是常量,所以直接进行拼接可以直接从常量池中获取到。
而方式2要append()两次,则方法栈就会压入两次,如果循环操作1000,则append()入方法栈就有2000次
9.项目上线之前,所有的System.out.println()都要替换为log4j或logger,否则轻则影响性能,重则服务挂掉
开发代码中要使用log.info代替System.out.println()。
因为system.out.print()的
1》加锁机制,导致同步输入,影响服务性能【性能对比:https://www.cnblogs.com/sxdcgaq8080/p/9646802.html】
2》输出信息的分类、格式化及永久保存
这些劣势决定!!
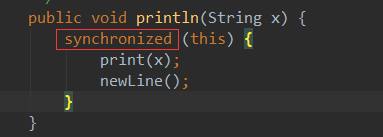
10.