1.函数递归
什么是函数递归
函数递归是函数嵌套的一种,是在函数调用阶段,直接或者间接的又调用自身
函数递归的演示
直接调用自身
def func(n): print('递归函数的演示%s'%n) print(n) func(n+1) # 又调用了本身 func(1)

间接调用自身
# index()函数内部调用了func()函数 def index(n): print(n) func(n+1) print(n) # func()函数内部又调用了index()函数,导致了递归出现了死循环 def func(n): print(n) index(n+1) index(1)
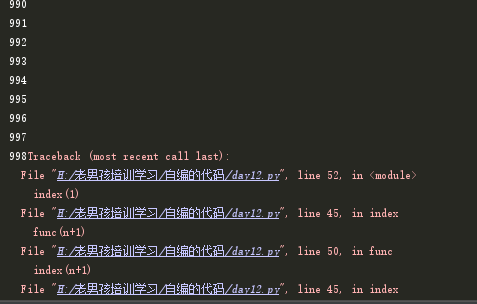
在函数内部又调用了自身,导致了重复调用,类似死循环,但是为了防止内存的溢出,python解释器对函数的递归做了限制,大概只能递归998次左右
我们可以通过添加sys模块人为的更改递归的限制此时
# sys模块 import sys print(sys.getrecursionlimit()) # 输出递归限制 sys.setrecursionlimit(2000) # 可以更改递归限制

函数递归的运用
递归可以在函数内帮我们完成类似循环的操作,但是我们不可能让一个函数无限制的递归下去,这时候我们需要给递归限制一个条件
递归分为两个阶段
回溯:函数递归时必须有一个明确的结束条件,并且每次递归的问题复杂程度慢慢下降,这样才能解决问题,否则便是毫无意义的死循环
递推:到达结束条件之后,一步步的往回推,获取最终结果
问题1:第一个人是20岁,他比第二个人小2岁,以此类推第10个人是多少岁
''' age1 = 20 age2 = age1 + 2 age3 = age2 + 2 age4 = age3 + 2 ... age(n) = age(n-1) + 2 ''' def index(n): if n == 1: # 结束条件 return 20 return index(n-1)+2 res = index(10)

问题2:循环输出l = [1,[2,[3,[4,]]]]
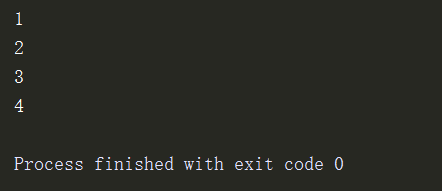
l = [1,[2,[3,[4,]]]] for i in l: if type(i) is int: print(i) else: for i1 in i: if type(i1) is int: print(i1) else: for i2 in i1: if type(i2) is int: print(i2) else: for i3 in i2: if type(i3) is int: print(i3)
可以使用for循环来输出,但是这样做很繁琐,一旦数字过大,便很难输出结果
利用递归解决
def index(l): for i in l: if type(i) is int: print(i) else: index(i) index(l)
注意:
使用递归函数不要考虑循环的次数 只需要把握结束的条件即可
2.算法之二分法
什么是算法
算法是解决问题高效的方法
问题:求一个数是否在一个列表中
l = [1,2,3,4,5,6,7,8,9] x = 9 print(x in l) # 第一种 for i in l: # 第二种 if x == i: print('%s在列表中'%x) else: pass
这两种方法都是基于for循环,即把每个数字都取出来一个个的进行对比,如果要求的是最后一个数字,则需要比较9次,这样的效率比较低
二分法查找:在有序列表中,先求出列表中间那个数,与被比较数比较,如果大于被比较数,则把小于中间数的数字作为列表,再求这个列表的中间数,再进行比较,直至找到这个数,这样的方法查找次数减少,查找效率提高
用二分查找法查找一个数
l = [1,2,3,4,5,6,7,8,80,100] def index(x,l): if not l: print('%s这个数不在列表中'%x) return key = len(l)//2 # 求列表中间的索引 if x > l[key]: # 与列表中间索引对应的值进行比较 l_right = l[key + 1:] # 比中间的值大就取右半区 index(x,l_right) elif x < l[key]: l_left = l[0:key] # 比中间的值小就取左半区 index(x,l_left) else: print('%s在列表中'%x) # 相等就打印 index(80,l)

注意:用二分法查找的列表一定是有大小顺序的
3.三元表达式
函数求数字大小
def my_max(x,y): if x > y: return x else: return y res = my_max(5,9) print(res)

三元表达式求数字大小
x = 4 y = 3 res1 = x if x > y else y # 三元表达式表示的是如果条件成立就返回x,条件不成立就返回y print(res1)
三元表达式的固定格式
# 三元表达式的格式: 值/代码1 if 布尔值判断 else 值/代码2 如果条件成立布尔值为True 则 输出值/代码块1 如果条件不成立布尔值为False 则 输出值/代码块2
注意:三元表达式只推荐在只有两个情况的条件下使用,一旦超过两个情况,代码块会变得复杂,不适合使用
4.列表生成式
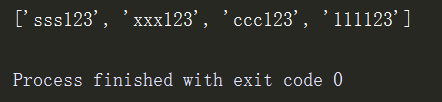
输出一个新列表,并且在每个元素后面添加123
l = ['sss','xxx','ccc','111'] # 普通的方法 l1 = [] for name in l: l1.append('%s123'%name) # 循环输出每个元素,并在每个字符串后面添加123,再添加入新列表 print(l1)
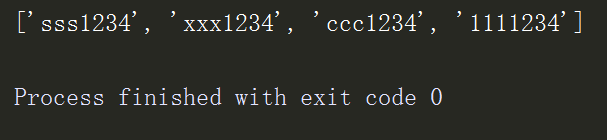
用列表生成式,在每个元素后面添加1234
# 列表生成式的方法 l1 = ['%s1234' %name for name in l] # 直接用列表生成式生成新列表 print(l1)
列表生成式后也可以跟if判断式
l2 = ['%s' %name for name in l1 if name.isdigit() == False] # 把不是纯数字的元素添加到新列表中 print(l2)
先for循环输出列表中的每个元素
交由if判断,条件成立的元素放入新列表
条件不成立的元素直接舍弃
注意:if后面不能再跟else,因为for后面也有else的说法,这样程序不能判断是for的else还是if的else
5.字典生成式和集合生成式
传统方法把两个列表一一对应生成一个字典
# 字典集合生成式 l1 = ['name','pwd','age'] l2 = ['sxc','123','18','123'] d = {} for i,j in enumerate(l1): # 枚举,i相当于列表的索引,j是列表的元素 print(i,j) d[j] = l2[i] print(d)
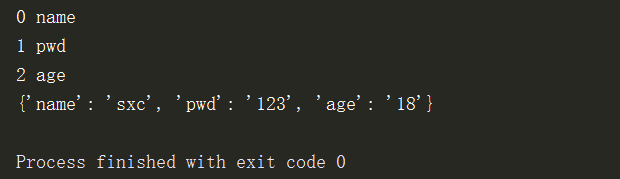
字典生成式
d1 = {i:j for i,j in enumerate(l1,1)} # 字典生成式生成列表
print(d1)
d2 = {i:j for i,j in enumerate(l2,1) if i != 2} # 加if判断条件的表达式,把i==2的情况去掉,后面也不能跟else
print(d2)

注意:和列表生成式类似,字典生成式后也可以跟if判断条件,也不能再跟else
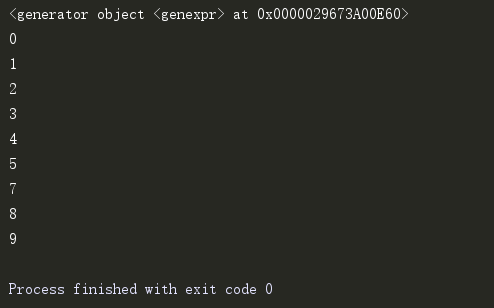
集合生成式
s1 = {i for i in range(10)} # 集合生成式
print(s1)
s2 = {i for i in range(10) if i != 5} # 集合生成式加if判断条件,后面也不能跟else
print(s2)

注意:和列表生成式类似,集合生成式后也可以跟if判断条件,也不能再跟else
生成式表达式:没有元组生成式,只有生成式表达式(相当于一个老母猪)
t1 = (i for i in range(10) if i != 6) # 这样写不是元组生成式,而是生成器表达式,相当于老母猪 print(t1) for i in t1: print(i)
6.匿名函数
匿名函数不再使用def的标准定义一个函数,而是使用lambda来创建匿名函数,匿名函数顾名思义是没有函数名的函数
匿名函数有自己的名称空间,并且只能访问自己参数列表的名称,不能访问其他或者全局名称空间的名称
匿名函数lambda只是一个表达式,函数体比def简单的多,并且他只能封装有限的逻辑表达式
匿名函数的特点:临时存在,用完就没了
求两个数的和
def sum(x,y): return x + y res = sum(1,2) print(res)
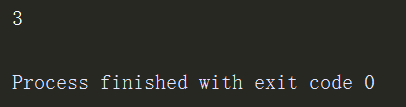
匿名函数求和
res1 = (lambda x,y:x+y)(3,4) # 匿名函数的第一种写法 print(res1) res3 = lambda x,y:x+y # 匿名函数的第二种写法 print(res3) # 这是函数对应的地址空间 print(res3(5,6))
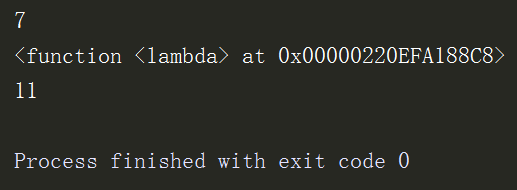
匿名函数的语法:(匿名函数lambda 匿名函数对应的形参 : 匿名函数对应的返回值)(匿名函数的实参)
匿名函数通常不会单独使用,是配合内置函数一起使用的
7.常用的内置函数
Python内置函数有很多

常用的一共约有69个内置函数
max()函数
max(x,y,z...) 方法返回给定参数的最大值,参数可以为序列,内部是基于for循环的
l = [1,2,3,4,5] print(max(l)) # 求最大值,内部是基于for循环的

max()+内置函数lambda的运用
d = { 'sxc':30000, 'zzj':88888888888, 'zzp':3000, 'lzx':1000 } # 求value的最大值,返回对应key的值 print(max(d,key = lambda name :d[name])) # 求value的最小值,返回对应key的值 print(min(d,key = lambda name :d[name]))

map(函数,一个或多个序列)映射
按照序列的索引执行前面的函数
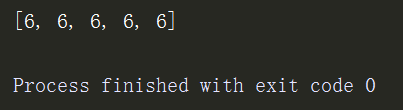
l1 = [1,2,3,4,5] l2 = [5,4,3,2,1] res = map(lambda x,y:x+y,l1,l2) # 定义一个匿名函数,输入两个列表按照索引执行函数 print(list(res))
zip(可迭代的对象)拉链
把多个迭代器内的内容按照索引分别组合成一个个元组,也是基于for循环的
l1 = ['姓名:sxc','姓名:zzj','姓名:zzp'] l2 = ['年龄:18','年龄:19','年龄:20'] l3 = ['密码:123','密码:234','密码:345'] res = zip(l1,l2,l3) print(res) # 老母猪 print(list(res)) # 可以用list来转换输出列表

filter(判断布尔值的函数,可迭代的对象)
用函数判断可迭代的对象的True和False,True的输出,False的丢弃
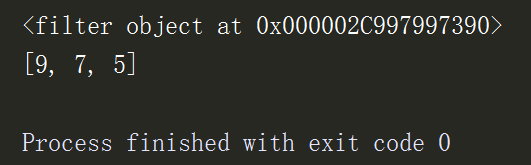
l = [9,7,5,3,1] res = filter(lambda x:x > 4,l) # 输出布尔值为True的l中的元素 print(res) print(list(res))
sorted(可迭代对象,key,reverse)升序,降序
对可迭代对象的升序降序,reverse = True降序,reverse = False升序
sorted与list.sort的不同是前者重新创建了一个列表,后者把原列表重新声明了,相当于修改了原列表
l = [1,2,3,4,5,6] res = sorted(l,reverse=True) # 降序 print(res)

reduce(函数,可迭代对象,初始值) 函数会对参数序列中元素进行累积
两个及以上的可迭代对象的数据按照函数累积,可以指定初始值
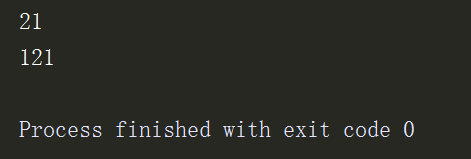
from functools import reduce l = [1,2,3,4,5,6] res = reduce(lambda x,y:x+y,l) # 不指定初始值1+2+3+4+5+6 print(res) res1 = reduce(lambda x,y:x+y,l,100) # 初始值指定为100,100+1+2+3+4+5+6 print(res1)
12