| 算法 | 每次迭代耗时 | 收敛速度 | 参数的敏感性 |
| 梯度下降Gradient | 对大数据集慢 | 较慢 | 适中 |
| 随机梯度下降Stochastic Gradient | 快 | 较快 | 高 |

随机梯度下降能更快地达到较大的对数似然值,但噪声更大
Explore the effects of step sizes on stochastic gradient ascent(步长对随机梯度上升的影响)

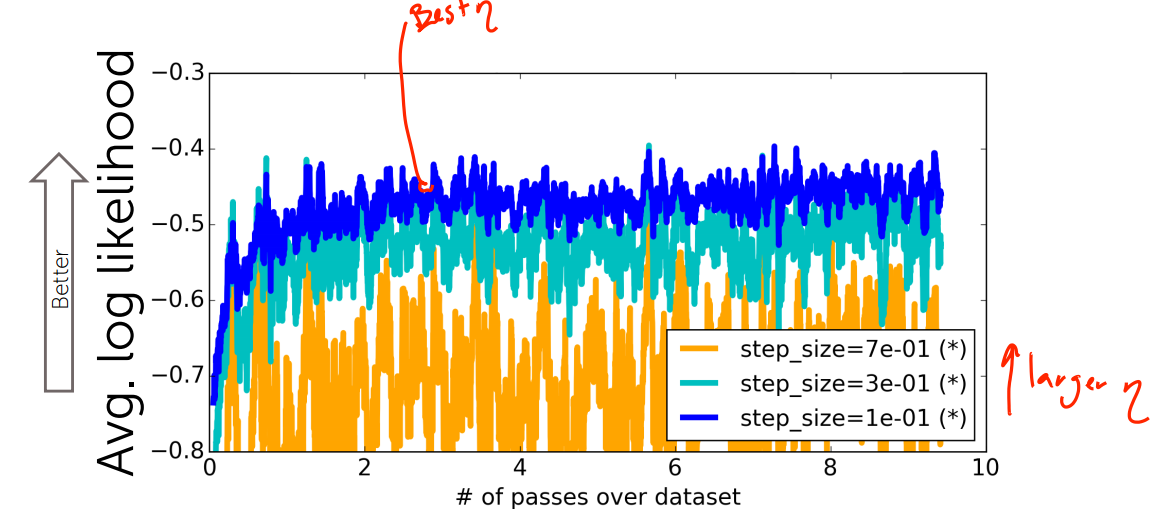

步长太小,收敛速度太慢;步长较大,震荡较大;步长异常大,不收敛
| 算法 | 每次迭代耗时 | 收敛速度 | 参数的敏感性 |
| 梯度下降Gradient | 对大数据集慢 | 较慢 | 适中 |
| 随机梯度下降Stochastic Gradient | 快 | 较快 | 高 |
随机梯度下降能更快地达到较大的对数似然值,但噪声更大
Explore the effects of step sizes on stochastic gradient ascent(步长对随机梯度上升的影响)
步长太小,收敛速度太慢;步长较大,震荡较大;步长异常大,不收敛