特征选择是指从全部特征中选取一个特征子集,
剔除不相关(irrelevant)或冗余(redundant )特征,可以减少特征个数,提高模型精确度,从而减少运行时间。此外,较少的特征使研究人员易于理解数据产生的过程。
特征选择全过程:
进行特征选择前需要先给出一个评价函数(即评价一个特征子集好坏程度的准则)和 停止准则(一般是一个阈值,当评价函数值达到这个阈值后就可停止搜索)
之后便可以进行搜索特征子集的过程(具体搜索过程见文献1)
得到特征子集后需要在验证数据集上验证选出来的特征子集的有效性
特征选择的准则是信息增益或信息增益比。
eg根据申请人的特征利用决策树决定是否批准贷款申请

从上述数据集我们将年龄作为根节点可以构造一棵决策树,以有工作为根节点也可构造一棵决策树,那那种是最优选择,这就需要用到信息增益了~
###########################################
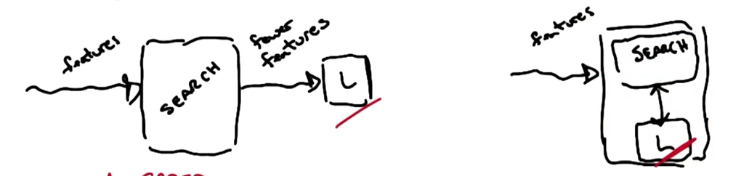
评价函数的作用是评价产生过程所提供的特征子集的好坏,根据其工作原理,主要分为筛选器(Filter)、封装器( Wrapper )两大类
左图为Filter,右图为Wrapper
相关性

正如上图所示,a和b有较强的相关性,a和e有较弱的相关性(因为a是e的补集),c是无关性特征(但并非无用)
相关性大都是对信息量而言,有用性是对误差、模型、学习等而言的
参考文献:
- http://www.cnblogs.com/heaad/archive/2011/01/02/1924088.html
- https://classroom.udacity.com