GROUPING SETS可以实现在一个SQL语句中对多个维度同时做聚合计算,省去了对多个聚合结果UNION ALL的操作,非常方便。
with
a as (
select 'a' col1,'aa' col2,1 num
union all
select 'a' col1,'ab' col2,2 num
union all
select 'a' col1,'ab' col2,3 num
union all
select 'b' col1,'bb' col2,4 num
union all
select 'b' col1,'bb' col2,5 num
union all
select 'b' col1,'bc' col2,6 num
)
select
col1,
col2,
sum(num) num_sum
from a
group by col1,col2
grouping sets (col1,col2,(col1,col2));
Hive Lateral View用法:
侧视图LATERAL VIEW函数结合EXPLODE()函数能够在Hive实现一行转多行的效果。
SET mapreduce.job.queuename=root.default;
WITH a AS (
SELECT array('a','b') col_1, array(1,2,3) col_2
union all
SELECT array('c','d') col_1, array(4,5,6) col_2
),
b AS (
SELECT array('a','b') col_1, '1,2,3' col_2
union all
SELECT array('c','d') col_1, '4,5,6' col_2
)
SELECT c,num FROM b LATERAL VIEW explode(split(col_2,',')) x AS num
LATERAL VIEW explode(col_1) y AS c;
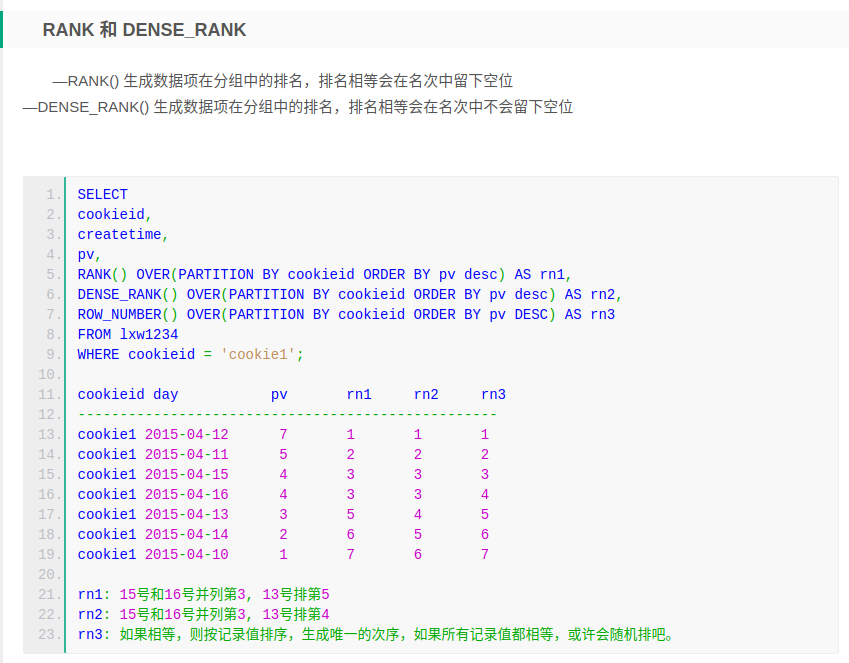
各种分组排序的使用效果:rank、dense rank、row_number(),其实用得最多的还是row_number()排序,方便又容易理解。你知道如何用row_number()函数计算用户连续活跃的天数吗?
Hive 窗口函数LAG
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
WITH a AS (
SELECT array('a','b') col_1, array(1,2,3) col_2
union all
SELECT array('c','d') col_1, array(4,5,6) col_2),
b as (SELECT c_1,c_2 FROM a
LATERAL VIEW explode(col_2) x AS c_2
LATERAL VIEW explode(col_1) y AS c_1)
SELECT c_1,c_2,row_number() OVER(PARTITION BY c_1 ORDER BY c_2 DESC) rnk
,LAG(c_2,1,999) OVER(PARTITION BY c_1 ORDER BY c_2 DESC) AS last_1
FROM b;
怎样写 in/exists 语句?左半连接函数的效率比select * FROM a where userid in (select userid from b)更高。
WITH a AS (
SELECT 'a' col_1, 1 col_2
union all
SELECT 'b' col_1, 2 col_2
union all
SELECT 'c' col_1, 3 col_2
),
b AS (
SELECT 'a' col_1, 1 col_2)
SELECT * from a LEFT SEMI JOIN b ON a.col_1=b.col_1;