1 CART回归树生成算法
一个决策树对应着输入空间的划分以及在划分空间的输出值,意思就是输入样本X在通过整个决策树后会落到哪个叶子结点,而划分空间的输出值就是该叶子结点对应的输出值。假设已经生成了一颗决策树,该决策树将输入空间划分成M个单元R1,R2,R3...RM,即决策树有M个叶子结点,并且在每一个叶子结点Rm上有一个固定的输出值Cm,于是回归模型就表示为:

其中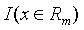 为指示函数,指示函数的定义为:
为指示函数,指示函数的定义为:
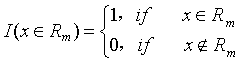
回归模型的含义为,对于一个样本X,它的输出是样本X对应的叶子结点的输出。
对于每个叶子节点上的预测输出值为该叶子节点上所有训练样本的输出的平均值。
下面是在构建决策树时如何选取最优的特征值的最优分割点作为分支依据。
对于训练样本任意的特征A,对于特征A任意的划分点S,可以将训练集划分为两个数据集D1和D2,求出使D1和D2各自集合的均方误差最小的该特征的划分点,按照此方法求所有特征的最优的划分点,然后比较所有特征的划分点的均方误差,取均方误差最小的特征的划分点作为决策树的分支。比较绕,举个栗子你就明白:
假设有一个训练集,该训练集有4个特征A, B, C, D, 以特征值A为例,特征值A的取值是连续的,按从大到小排为[1, 2, 3, 4, 5],则特征A的划分点就有4个,分别为1.5, 2.5, 3.5, 4.5,然后求每个划分点划分出来的两部分数据的均方误差之和(均方误差:每个样本的输出减去该样本所属的数据区域所有样本输出的均值,然后求和),最后比较求出特征A均方误差最小的划分点a,该划分点的均方误差为Ea。通过上述方法可求出特征B的划分点b对应的均方误差Eb,特征C的划分点c对应的均方误差Ec,特征D的划分点d对应的均方误差Ed,最后从Ea,Eb,Ec,Ed中选出最小的对应的特征,则该特征的最优划分点即为本轮决策树的分支依据。公式为:
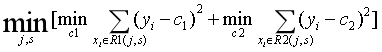
其中j是待选的划分样本,s为待选的特征划分点,c1为区域R1所有样本输出均值,c2位区域R2所有样本输出的均值。
最小二乘回归树生成算法:
输入:训练数据集D;
输出:回归树T
在训练数据集D所在的输入空间中,递归的将每个区域划分为两个子区域并决定每个子区域上的输出值,构建二叉树。
(1)选择最优的切分特征 j 和划分点s
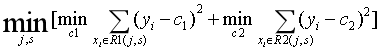
遍历特征 j ,对固定的划分特征 j 扫描划分点s,选择使上式达到最小值的划分对(j, s)
(2)用选定的划分对(j, s)划分区域并决定相应的输出值,输出值为划分的区域的所有样本输出的均值;
(3)继续对两个子区域调用步骤(1)(2),直至满足停机条件;
(4)将输入空间划分为M个区域,生成决策树。
2 CART分类树生成算法
CART分类树用基尼指数选择最优的特征,同时决定该特征的最优二值切分法。
基尼指数的定义:
在分类问题中,假设有K个类别,样本点属于第k类的概率为pk,则概率分布的基尼指数定义为:

对于二分类问题,若样本点属于第1个类的概率是p, 属于另一类的概率是(1-p),则概率分布的基尼指数为:
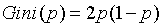
对于样本集合D,其基尼指数为:
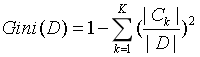
这里,Ck是D中属于第k类的样本子集,K是类的个数。
如果样本集合D根据特征A是否取某一个可能值a被分割成D1, D2两个部分,则在特征A的条件下,集合D的基尼指数为:
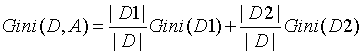
基尼指数Gini(D)表示集合D的不确定性,基尼指数Gini(D, A)表示经A=a分割后集合D的不确定性。基尼指数值越大,样本集合的不确定性也就越大。
CART分类树算法:
输入:训练数据集D,和停机条件
输出:CART分类树
根据训练数据集,从根节点开始,递归的对每个节点进行以下操作,构建二叉树;
(1)设根节点的训练数据集为D,计算现有特征对该数据集的基尼指数。此时对每一个特征A,对其可能取的每一个值a,根据样本点对A=a的测试为是或否,将D分割成D1和D2两个部分,利用上面的公式计算A=a的基尼指数。
(2)在所有可能的特征A以及它们所有可能的切分点a中,选择基尼指数最小的特征及其对应的切分点作为最优特征与最优切分点,依最优特征和最优切分点,从现节点生成两个子结点,将训练数据集依特征分配到两个子结点中去。
(3)对两个子结点递归的调用(1)(2),直至满足停机条件。
(4)生成CART分类决策树。
停机条件:
(1)结点中的样本个数小于预定阈值
(2)样本集的基尼指数小于预定阈值(结点中的样本基本属于同一类)
(3)没有多余的特征
3 CART树剪枝算法
CART算法有两个部分组成:首先从生成算法产生的决策树T0的叶结点开始剪枝,直到T0的根结点,形成一个子树序列{T0, T1, ..., Tn};然后通过交叉验证法在独立的验证数据集上对子树序列进行测试,从中选出最优子树。
首先先介绍算法的第一步也是最重要的一步:剪枝,形成子树序列
在剪枝形成子树序列时,不是一视同仁都要剪掉,要计算子树的损失函数,来评价是否可剪。子树的损失函数定义为:
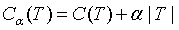
其中T为任意子树,C(T)为对训练数据的预测误差,该预测误差可以是回归树的均方误差,也可以是分类树的基尼指数,|T|为子树的叶结点数, >=0是一个参数,
>=0是一个参数,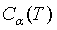 为参数是
为参数是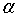 时的子树T的整体损失函数。参数
时的子树T的整体损失函数。参数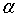 权衡训练数据的拟合程度和模型的复杂度。
权衡训练数据的拟合程度和模型的复杂度。
具体的,从整体树T0开始剪枝,对T0的任意内部结点t,以t为根节点的子树Tt的损失函数为:
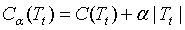
若树T为分类树,则C(Tt)为以内部节点t的Gini指数,是该结点的所有叶结点的Gini指数加权之和。
若将以t为根结点的子树Tt的所有叶结点全部剪掉,则以t为单结点树的损失函数为:

当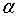 等于零时,在某一个
等于零时,在某一个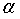 有:
有:
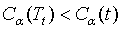
当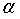 增大时,在某一个
增大时,在某一个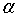 有:
有:
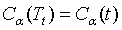
在这个使 的
的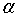 ,则有
,则有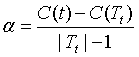 ,此时Tt和t有相同的损失函数,而t的结点少,因此t比Tt更可取,就可以对Tt剪枝。
,此时Tt和t有相同的损失函数,而t的结点少,因此t比Tt更可取,就可以对Tt剪枝。
为此,对T0中每一个内部结点t,都可以计算:
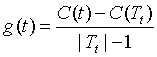
g(t)表示剪之后整体损失函数减少的程度。在T0中剪去g(t)最小的Tt,将得到的子树作为T1,同时将最小的g(t)设为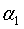 ,T1位区间[
,T1位区间[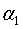 ,
, 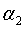 ]的最优子树。
]的最优子树。
如此剪下去,直至根结点。在这一过程中,不断的增加 的值,产生新的区间。
的值,产生新的区间。
然后再介绍算法的第二步:在剪枝得到的子树序列中T0, T1, ... Tn中通过交叉验证选取最优子树 。
。
利用独立的验证集,测试子树序列T0, T1, ... Tn中各颗子树的平均误差或基尼指数。平方误差或基尼指数最小的决策树别认为是最优的决策树,在子树序列中,每颗子树T0, T1, ... Tn都对应一个参数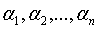 ,所以,当最优子树Tk确定时,对应的
,所以,当最优子树Tk确定时,对应的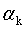 也就确定了,即得到了最优决策树
也就确定了,即得到了最优决策树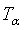
。
CART剪枝算法:
输入:CART算法生成的决策树T0
输出:最优决策子树
(1)设k=0,T=T0;
(2)设 为正如穷
为正如穷
(3)自下而上地对各内部结点t计算C(Tt),|Tt|以及
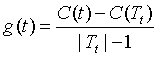
这里,Tt表示以t为根节点的子树,C(Tt)是对训练数据的预测误差,|Tt|是Tt的叶节点个数。
(4)对g(t) = 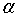 的内部结点t进行剪枝,并对叶节点t以多数表决法决定其类别,得到树T;
的内部结点t进行剪枝,并对叶节点t以多数表决法决定其类别,得到树T;
(5)设k=k+1,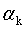 =
=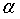 ,Tk=T;
,Tk=T;
(6)如果Tk不是由根节点及两个叶节点构成的树,则回到步骤(2);否则令Tk=Tn;
(7)采用交叉验证的方法在子树序列中T0,T1,...,Tn选取最优的子树。
本篇随笔主要参考李航老师的统计学习方法