readConcern
-
问题综述:(在读取数据的过程中需要关注以下两个问题)
-
- 从哪里读?即关注数据节点的位置。
-
- 什么样的数据可以读?关注数据的隔离性。
-
-
第一个问题是由 readPreference 来解决的。
-
readPreference 在很早的版本就有了。
-
readPreference 以下五个可选值:
-
- primary:只选择主节点;
-
- primaryPreferred:优先选择主节点,如果不可用则选择从节点;
-
- secondary:只选择从节点;
-
- secondaryPreferred:优先选择从节点,如果从节点不可用则选择主节点;
-
- nearest:选择最近的节点(ping mongod服务器哪个最近就用哪个);
-
-
场景举例:
- 用户下订单后马上将用户转到订单详情页面——primary/primaryPreferred。因为此时从节点可能还没复制到新订单;
- 用户查询自己下过的订单——secondary/secondaryPreferred。查询历史订单对实效性通常没有太高的要求;
- 生成报表——secondary。报表对实效性要求不高,但资源需求大,可以在从节点单独处理,避免对线上用户造成影响;
- 将用户上传的图片分发到全世界,让各地用户能够就近读取——nearest。每个地区的应用选择最近的节点读取数据;
-
readPreference 与 Tag
- readPreference 只能控制使用一类节点。Tag则可以将节点选择控制到一个或几个节点。考虑以下场景:
- 一个5节点的复制集;
- 3个节点(1主2从)硬件较好,专用于服务线上用户(OLTP);
- 2个节点(2从)硬件较差,专用于生成报表(OLAP);
- 可以使用Tag来达到这样的控制目的:
- 为3个较好的节点打上 {purpose:"online"};
- 为2个较差的节点打上 {purpose:"analyse"};
- 在线应用读取时指定online,报表读取时指定reporting。
- readPreference 只能控制使用一类节点。Tag则可以将节点选择控制到一个或几个节点。考虑以下场景:
-
readPreference 配置
-
通过 MongoDB 的连接串参数:
mongodb://host1:27017,host2:27017,host3:27017/?replicatSet=rs&readPreference=secondary -
通过 MongoDB驱动程序API:
MongoCollection.withReadPreference(ReadPreference readPref)- Mongo Sehll(单个操作时指定):
db.collection.find({...}).readPref("secondary") -
-
readPreference 实验:从节点读
-
主节点写入{x:1},观察该数据在各个节点立即可见。
- 在两个从节点分别执行 db.fsyncLock() 来锁定写入(同步)。
- 主节点写入 {x:2}
- db.test.find({a:123})
- db.test.find({a:123}).readPref("secondary")
- 解除从节点锁定 db.fsyncUnlock()
- db.test.find({a:123}).readPref("secondary")
-
注意事项:
- 指定 readPreference 时应注意高可用的问题。例如将 readPreference 指定 primary,则发生故障转移不存在 primary 期间将没有节点可读。如果业务允许,则应选择 primaryPreferred;
- 使用 Tag 时也会遇到同样的问题,如果只有一个节点拥有一个特定 Tag,则在这个节点失效时将无节点可读。这在有时候时期望结果,有时候不是。例如:
- 如果报表使用的节点失效,即使不生成报表,也不希望将报表负载转移到其他节点上,此时只有一个节点有报表 Tag 是合理的选择。
- 如果线上节点失效,通常希望有替代节点,所以应该保持多个节点有同样的 Tag;
- Tag 有时需要与优先级、选举权综合考虑。例如做报表的节点通常不会希望它作为主节点,则优先级应该为0。
-
-
-
第二个问题是由 readConcern 来解决。
- 什么是 readConcern ?
-
在 readPreference 选择了指定的节点后,readConcern 决定这个节点上的数据哪些是可读的,类似于关系数据库的隔离级别。
-
可选值包括:
- available 读取所有可用的数据,什么都不管;(从节点读取时默认 avaliable)
- local 读取所有可用且属于当前分片的数据;(主节点读取时默认 local)
- local 和 avaliable 在没有分片集群的情况下是几乎一致的。
- 但是在分片迁移(chunk)的过程中,可能会存在数据同时出现在两个分片集的情况,这时可能会出现数据重复的问题。
- majority 读取在大多数节点上提交完成的数据;(推荐使用)
- linearizable 可线性化读取文档,保证这次的读是可以读到上一次的写的;
- snapshot 读取最近快照中的数据,差不多可以达到关系型数据库中序列化的级别,隔离级别最高的;
-
注意事项:
- 在主节点读取数据时默认 readConcern 是 local,在从节点读取数据时默认的 readConcern 是 avaliable的(出于向前兼容);
- MongoDB <= 3.6 不支持对从节点使用 {readConcern: "local"};
- 虽然看上去总应该选择 local,但会在对结果集过滤过程产生额外消耗。在一些无关紧要的场景(如统计)下,也可以考虑使用 avaliabel。
-
readConcern: "majority"
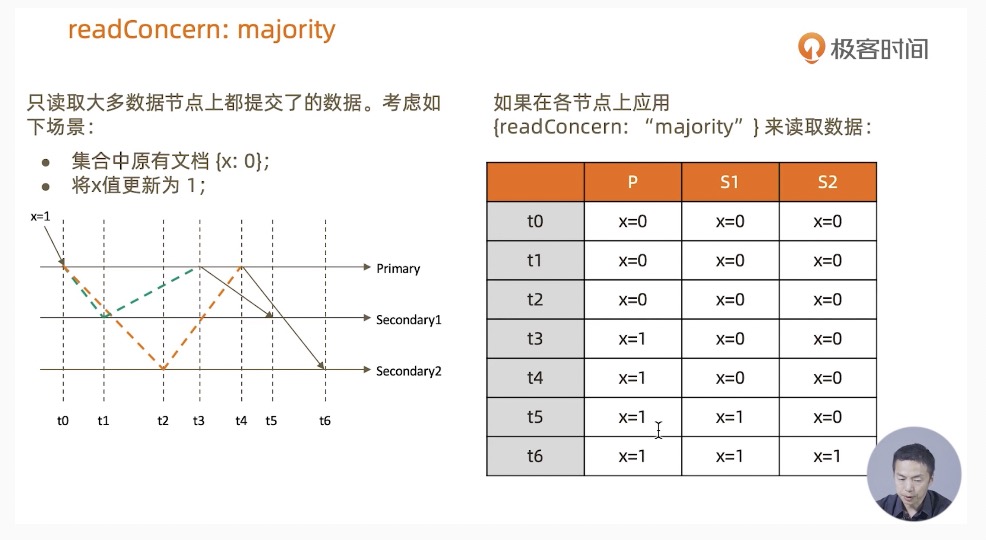
-
实验:readConcern: "majority" vs "local"
-
安装3节点复制集。
-
注意在配置文件内 replication 的参数 enableMajorityReadConcern 需要打开。
replication: replSetName: rs0 enableMajorityReadConcern: true-
将复制集中两个从节点使用 db.fsyncLock() 锁住写入(模拟同步高延迟)。
db.test.save({"a":1}) # 主节点:写入。 db.fsyncLock() # 两个从节点:分别执行。 db.test.find().readConcern("local") db.test.find().readConcern("majority") # 此时会阻塞 db.fsyncUnlock() # 在一个从节点上解除写锁。 db.test.find().readConcern("majority") # 这次可以成功读取。 -
结论:
- 使用 local 参数,则可以直接查询到写入数据。
- 使用 majority,只能查询到已经被多数节点确认过的数据。
- update 与 remove 与上同理。
-
-
readConcern: majority 与 脏读
- MongoDB 中的回滚:
- 写操作在到达大多数节点前都是不安全的,一旦主节点崩溃,从节点还没复制到此次操作,则刚才的写操作就丢失了。
- 把一次写操作视为一个事务,从事务的角度,可以认为事务被回滚了。
- 所以从分布式系统的角度来看,事务的提交被提升到了分布式集群多个节点级别的提交,而不再是单个节点上的提交。
- 在可能发生回滚的前提下考虑脏读问题:
- 如果在一次写操作到达大多数节点前读取了这个写操作,然后因为系统故障该操作回滚了,则发生了脏读问题;
- 使用 {readConcern:"majority"} 可以有效避免脏读。
- MongoDB 中的回滚:
-
readConcern 如何实现安全的读写分离
-
考虑如下场景:
-
向主节点写入一条数据,立即在从节点读取这条数据。
-
错误方式:
db.orders.insert({old:101,sku:"kite",q:1}) db.orders.find({old:101}).readPref("secondary")- 正确方式:writeConcern + readConcern majority 来解决:
db.orders.insert({old:101,sku:"kite",q:1}, {writeConcern:{w:"majority"}}) db.orders.find({old:101}).readPref("secondary").readConcern("majority") -
-
小测试
- readConcern 主要关注读的隔离性,ACID 中的 Isolation,但是是分布式数据库特有的概念。
- readConcern:"majority" 相应于事务中隔离级别中的 Read Committed。
-
-
readConcern:"linearizable" 略
-
readConcern:"snapshot"
- 只在多文档事务中生效。
- 讲一个事务的 readConcern 设置为 snapshot,将保证在事务中的读:
- 不出现脏读;
- 不出现不可重读;
- 不出现幻读。
- 因为所有的读都将使用同一个快照,直到事务提交为止该快照才被释放。
-
- 什么是 readConcern ?