Flume是一款优秀的数据采集框架主要包括三个主件source,channel,sink。
source表示接入的数据源 channel表示数据的存储介质 sink表示数据打到什么地方
Flume 具体支持的数据源可以参考该链接:https://www.pianshen.com/article/68101781511/
大致步骤与kafka类似,只是启动的时候不需要先启动zk
可以去该地址:http://archive.apache.org/dist/flume/ 下载对应的版本 本文用的是1.7.0 版本 运行环境是windows
运行的命令如下:
flume-ng.cmd agent -conf ../conf -conf-file ../conf/example.conf -name a1 -property flume.root.logger=INFO,console
(需要先cd到flume-ng.cmd 所在的目录)
为了测试方便,本文用的数据源是netcat ,方便使用telnet去发送数据
本文大致思路如下:用telnet 向33333端口发送数据,flume监听到33333端口发来的数据之后,发送给44444端口,
SparkStreaming 去监听44444端口,接收到telnet发送来的数据,对telnet的数据做一个wordcount 操作,结束。
配置文件如下:
#flume-to-spark.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 33333
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = localhost
a1.sinks.k1.port = 44444
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 1000000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
flume启动成功后如下图:
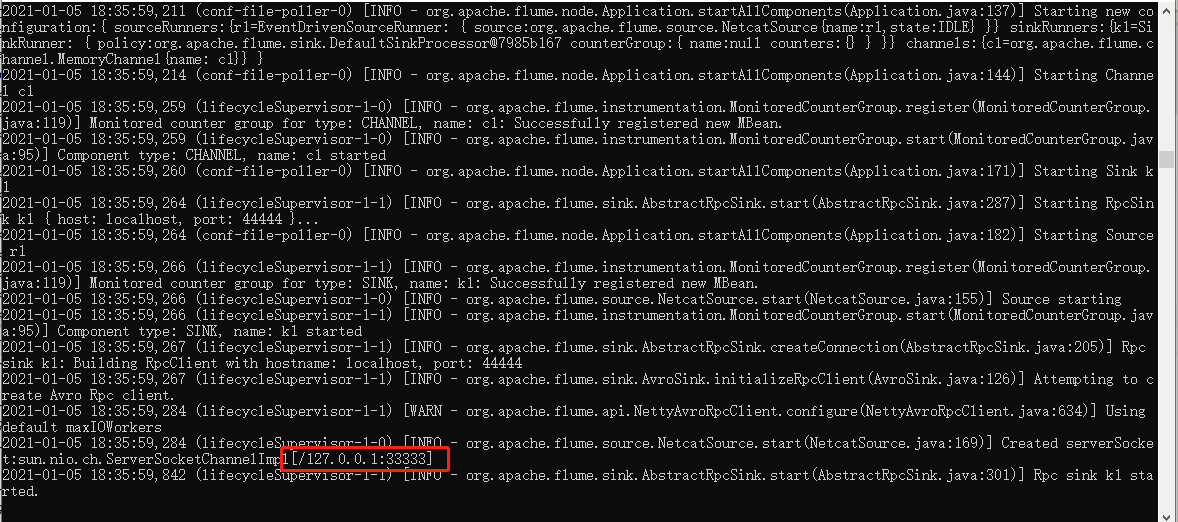
成功监听33333端口
SparkStreaming 代码如下:
package org.apache.spark import org.apache.spark.SparkConf import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming._ import org.apache.spark.streaming.dstream.DStream import org.apache.spark.streaming.flume._ import org.apache.spark.util.IntParam object FlumeEventCount { def main(args: Array[String]) { /** * 监听本地的 44444端口 */ val Array(host, IntParam(port)) = Array("localhost","44444") val batchInterval = Milliseconds(1000) // Create the context and set the batch size val sparkConf = new SparkConf().setAppName("FlumeEventCount").setMaster("local[2]") val ssc = new StreamingContext(sparkConf, batchInterval) // Create a flume stream val pollingStream = FlumeUtils.createStream(ssc, host, port, StorageLevel.MEMORY_ONLY_SER_2) // Print out the count of events received from this server in each batch // event是flume中传输数据的最小单元,event中数据结构:{"headers":"xxxxx","body":"xxxxxxx"} val flume_data: DStream[String] = pollingStream.map(x => new String(x.event.getBody.array()).trim) // 切分每一行 val words: DStream[String] = flume_data.flatMap(_.split(" ")) // 每个单词计为1 val wordAndOne: DStream[(String, Int)] = words.map((_,1)) // 相同单词出现次数累加 val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_+_) // 打印 result.print() // stream.foreachRDD{rdd=>rdd.map(x=>x.toString).foreach(println)} ssc.start() ssc.awaitTermination() } }
首先运行 Spark Streaming代码结果如下:
由于现在还没有发送数据,所以没有任何有价值的信息。
接下来重新打开一个窗口使用telnet 发送数据 命令如下
telnet localhost 33333
发送如下数据

然后在sparkStreaming console 查看
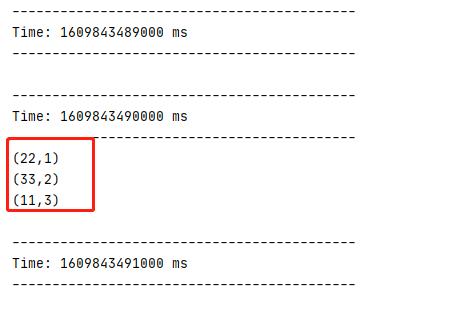
成功统计输入的数据,当然本实例只是做了一个简单地的wordcount操作,在实际的生产环境中,可以根据需求来做。
以上:)