模块
模块的基本概念
模块: # 一系列功能的结合体
模块的三种来源
""" 模块的三种来源 1.python解释器内置的模块(os、sys....) 2.第三方的别人写好的模块文件(requests...) 3.自己定义开发的功能模块(你写在py文件里的内容,可以被当成模块导入) """
模块的四种表现形式
""" 模块的四种表现形式 1.用python语言编写的py文件(也就意味着py文件也可以称之为模块:一个py文件也可以称之为模块) 2.已被编译为共享库或者DLL的C或者C++扩展 3.把一系列模块组织到一起的文件夹(文件夹下有一个__init__.py文件,该文件夹称之为包(包:一系列py文件的结合体)) 4.使用C编写并连接到python解释器的内置模块 """
为什么用模块
""" 使用模块的原因 1.使用别人写好的模块(内置的,第三方的),可以极大地提升开发效率,并且通常情况下这些第三方模块的健壮性还比较好,功能也比较多 2.可以将自己写的项目分成多个py文件,多个文件使用相同方法的时候可以写到一个py文件中,然后以模块的形式导入直接调用(更高层面的代码复用) """
tips:现在是高效率社会,谁写的快,功能强大,bug少,就是NB,不是说都自己纯手撸出来才NB
模块引入
使用模块 一定要注意区分哪个是执行文件,哪个是被导入文件
import
使用import关键字导入模块,
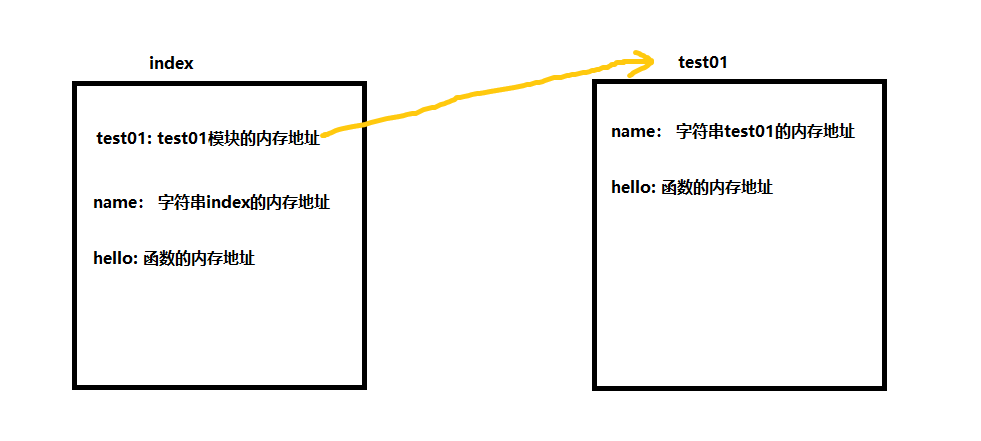
现有如下两个文件,执行index.py


print("this is test01") name = 'test01' def hello(): print("hello, i am from test01")
import test01 # 使用import 关键字导入模块 # this is test01 print("this is index") # this is index name = 'index' print(name) # index def hello(): print("hello, i am from index!") # hello, i am from index! hello() print(test01.hello()) # 先执行test01中的hello 方法,然后将返回值返回,print打印 # hello, i am from test01 # hello方法中打印的信息 # None # hello方法的返回值(没有返回值) print(test01.name) # test01 import test01 # 再次导入模块,并不会再次执行test01 模块中的代码
''' 执行index.py 文件,创建一个index 命名空间 执行index.py 的第一行代码 import test01 ,先查看index的名称空间中,没有指向test01这个名称空间的内容,所以进入到 test01文件,创建一个test01 名称空间 执行test01文件: 执行test01第一行代码,打印this is test01 执行test01第二行代码,在test01 的名称空间中存储一个变量name 与字符串test01内存地址的绑定关系(即变量名name) 执行test01第三行代码(忽略空行),定义一个函数hello,在test01的名称空间中存储hello 与其内存地址的绑定关系(跳过函数体,函数定义阶段不执行)(即函数名) 至此,test01执行完毕,返回index 的import那行语句 在index的名称空间中存储一个变量test01 执行test01这个名称空间的内存地址(即变量test01 指向了 test01) --> index的名称空间中有test01这么一个东西执行test01模块的名称空间 执行下一行代码,打印this is index 执行下一行代码,在index 的名称空间中存储一个变量name 与字符串index内存地址的绑定关系 执行下一行代码,将name 打印出来(在index 这个名称空间中找,找到了 name = 'index') 执行下一行代码,定义一个函数hello,在index名称空间中存储hello 与其内存地址的绑定关系 执行下一行代码(跳过了hello 的函数体代码),调用hello 函数(在index这个名称空间找,找到了hello方法,调用,在控制台打印了hello, i am from index!) 执行下一行代码,执行因函数加括号的执行优先级比较高,所以先调用函数,因指定了名称空间是test01 所以就去test01里面找hello函数,找到,然后打印hello, i am from test01 因test01中的hello函数没有返回值,所以打印了个None 执行下一行代码,打印test01名称空间中的name变量,字符串test01 执行下一行代码,import test01,此时index的名称空间中已经有test01的名称空间了,就不再执行test01.py内的代码了(python可以避免重复导入) '''
import小结
''' 多次导入同一模块不会再执行模块文件,会沿用第一次导入的成果(******) 使用import导入模块 访问模块名称空间中的名字统一句势:模块名.名字 特点: 1.指名道姓的访问模块中的名字 永远不会与执行文件中的名字冲突 2.你如果想访问模块中名字 必须用模块名.名字的方式 当模块名字比较复杂的情况下 可以给该模块名取别名 import check_.....login(很长的模块名) as check_login(别名) '''
import导入多个模块
import os, sys, time # 导入多个模块可以这样写,但不推荐 # 推荐写法 import os import sys import time
from ... import ...
''' 利用from...import...句式 缺点: 1.访问模块中的名字不需要加模块名前缀 2.在访问模块中的名字可能会与当前执行文件中的名字冲突 from md1 import * # 一次性将md1模块中的名字全部加载过来 不推荐使用 并且你根本不知道到底有哪些名字可以用 默认是找被导入模块里的__all__(这个列表的元素) '''
__all__
一般与 from ... import * 组合使用,指定被导入模块中可以被导入的名称(不写默认表示所有名称),限制导入者能够拿到的名称个数
__all__ = ['money', 'read1', 'read2'] ''' 用来限制 from test01 import * 所能获取到的内容,导入文件中无法直接使用 change() from test01 import change 依旧可以导入 change 函数,在导入文件中可以直接使用 change() import test01 在导入文件中可以直接使用 test01.change() ''' money = 1000 def read1(): print('md', money) def read2(): print('md模块') read1() def change(): global money money = 0 print("change func is running")
from test01 import * print(money) print(read1()) print(read2()) # print(change()) # 会报错,NameError: name 'change' is not defined # 1000 # md 1000 # None # md模块 # md 1000 # None
from test01 import change print(change()) # 虽然 test01 的 __all__ 中没有 change,但这里依旧可以使用,from test01 import change 把 chagne 函数导入过来了 # change func is running # None
import test01 print(test01.money) print(test01.read1()) print(test01.read2()) print(test01.change()) # 虽然 test01 的 __all__ 中没有 change,但通过 test01.change 的方式依旧访问到了 change() 函数 print(test01.money) # 1000 # md 1000 # None # md模块 # md 1000 # None # change func is running # None # 0
循环导入
循环导入问题(这里推荐一篇别人博客供参考 循环导入问题)
有如下三个文件,你不管执行哪个文件都会报错(因为它导入了还不存在的名称(变量)),例如: ImportError: cannot import name 'y'
# m1.py print('from m1.py') from m2 import x y = 'm1'
# m2.py print('from m2.py') from m1 import y x = 'm2'
# run.py import m1
画一幅图表示代码执行与名称空间的变化关系,即可知道为什么报错了
# 循环导入:不应该出现在程序里面 # 如果出现循环导入问题, 那么一定是你的程序设计的不合理 # 循环导入问题在程序设计阶段就应该避免
解决方式(最正确的方式是设计的时候避免它的出现)
方式一: # 将导入语句写在文件的最下方(在要用到导入模块之前)
# m1.py print('from m1.py') y = 'm1' from m2 import x
# m2.py print('from m2.py') x = 'm2' from m1 import y
方式二: # 在函数内部写导入语句(利用函数定义阶段不执行内部代码的特点,让其他变量在调用前被定义好)
# m1.py print('from m1.py') def func1(): from m2 import x print(x) y = 'm1'
# m2.py print('from m2.py') def func1(): from m1 import y print(y) x = 'm2'
虽然以上两种方式可以解决循环导入的问题,但还是尽量不要产生这个问题,设计的时候尽量避免
__name__
文件是被导入还是被执行的判断方法 意义所在参考文章 python文件的两种用途
# 当文件被当做执行文件执行的时候__name__打印的结果是__main__ # 当文件被当做模块导入的时候__name__打印的结果是模块名(没有后缀) if __name__ == '__main__': index1() index2() if __name__ == '__main__': # 快捷写法 main直接tab键即可 index1()
导入模块时的查找顺序
此处知识点案例推荐文章 模块的搜索路径
''' 模块的查找顺序 1.先从内存中已导入的模块中找 2.内置模块中找 3.从sys.path里面找(暂时理解成环境变量,依据当前文件来的) 是一个大列表,里面放了一堆文件路径,第一个路径永远是执行文件所在的文件夹 '''
验证(前两个顺序跳过,验证sys.path里查找)
创建下图所示的目录层次,并在对应文件中添加如下内容
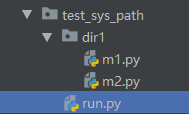
# run.py import sys print('执行文件查看的结果:', sys.path) from dir1 import m1
# m1.py import sys print('模块m1中查看的结果', sys.path) # import m2 from dir1 import m2 m2.f2()
# m2.py import sys print(sys.path) def f2(): print('from m2')
当你直接执行 run.py 的时候,你会发现文件并不会报错
当你直接执行 m1.py 的时候会直接报错,这是因为文件的搜索路径是以当前执行文件所在的路径为准的,你直接执行 m1.py 他就会在同级去找 dir1 目录,而他找不到,所以报错
此时如果你把 m1.py 中的 from dir1 import m2 改成 import m2 再次执行 m1.py 你就会发现他不会报错了
而你此时去执行 run.py就会报错,因为 run.py 导入 m1.py 的时候执行到了 import m2 这句代码,而在 run.py 的目录下去找 m2 模块又找不到了 (注意这个搜索起点的转变)
相对导入与绝对导入
# 一定要搞清楚谁是执行文件,谁是被导入文件(可利用 __name__ 的值是不是 "__main__" 来判断) # 注意:py文件名不应该与模块名(内置,第三方)冲突 --> 试试文件名冲突,取别名 # sys.path 里的值是以当前被执行文件(右键run)为准的
绝对导入
''' 绝对导入必须依据执行文件所在的文件夹路径为准 1.绝对导入无论在执行文件中还是被导入文件都适用 '''
相对导入
''' 相对导入 .代表当前路径 ..代表上一级路径 ...代表上上一级路径 '''
注意
''' 相对导入不能在执行文件中导入(即,用了相对导入,该文件就不能是执行文件了,只能是模块。。。) 相对导入只能在被导入的模块中使用,使用相对导入,就不需要考虑执行文件到底是谁,只需要知道模块与模块之间的路径关系 '''
相对导入的相对是针对执行文件而言的,不是以被导入的文件为基准
软件开发目录规范
为了提高程序的可读性与可维护性,我们应该为软件设计良好的目录结构,这与规范的编码风格同等重要,简而言之就是把软件代码分文件目录,拆开来写。
软件基本目录结构

''' 项目名 bin ..........执行文件 start.py --------项目启动文件 conf ..........里面放的是一些变量与值的对应关系,不常变动的值(常量) settings.py --------项目配置文件 core ..........核心逻辑代码 src.py --------项目核心逻辑文件 db ..........数据库相关信息 modles.py --------项目存储数据库 lib ..........一些公共的功能 common.py --------项目所用到的一些公共的功能 log ..........日志 记录用户行为 view.log --------项目的日志文件 readme.md ..........这款软件的介绍........... 如果把启动文件放在项目根目录,只需要BASE_DIR 改一下就行了 '''
各文件基本内容
''' 歩鄹: 1.拼接项目的根路径。放到项目的环境变量里 2.导入项目核心入口文件(core/src.py),加判断,在此文件作为执行文件被加载的时候运行项目核心入口文件(core/src.py)(被导入时不执行) ''' import os import sys # .................歩鄹一 # 这里是在拼接文件目录,因为不同操作系统表示文件路径的间隔符不一致,所以需要用到模块来拼接路径 BASE_DIR = os.path.dirname(os.path.dirname(__file__)) # # 如果是把软件的启动文件(start.py)放到了项目的根目录,则使用下面的路径 # BASE_DIR = os.path.dirname(__file__) # 将拼接好的路径放到 sys.path 中,方便后续import 模块的时候可以直接从项目根目录出发(查找顺序,找不到,然后找到了这里) sys.path.append(BASE_DIR) # .................歩鄹二 # 这里请忽略pycharm的报错,pycharm还不能做到这么智能地去识别这个模块存不存在,按照简单的规则去找找不到 from core import src if __name__ == '__main__': src.run()
''' 这里是程序的入口 在这里写一些项目的核心代码 # 可以先用空函数来罗列功能,把功能框架搭好,然后再慢慢去完善代码 ''' def register(): pass def login(): pass def shopping(): pass # 这个是start.py 文件导入的开始文件,必须和那边名字一样 def run(): print("run了") pass
import os import sys BASE_DIR = os.path.dirname(os.path.dirname(__file__)) # 如果start.py 是在项目根目录,则使用下方的 BASE_DIR # BASE_DIR = os.path.dirname(__file__) sys.path.append(BASE_DIR) # 其他配置信息
将上述三个文件写完,就可以直接在 start.py 右键运行将程序跑起来了,现阶段简单的部分其他文件夹用不太到
tips:pycharm会自动把项目根目录加到 sys.path 里面去,但我们还是要在 bin/start.py 里配置 BASE_DIR,因为软件写来是给别人用的(换了台电脑,位置什么变了,不用pycharm什么的,你也得确保它能跑起来)
通用方法编写(为方法加上过滤条件,需要登录才能购物),让其他方法也能用上这个登录验证,只需要改动一下 core/src.py 与 lib/common.py 即可,其他要的地方再导入
''' 给shopping方法添加了登录验证装饰器,需要登陆成功才能购物 ''' # 这里需要把通用模块里写好的登录验证倒过来,然后装饰器调用 from lib import common # 请忽略pycharm报错,写好运行一下你就知道没问题了 def register(): print("注册") pass def login(): while True: username = input("Please input your username>>>:").strip() pwd = input("Please input your password>>>:").strip() if username == 'jason' and pwd == '123': print("登录成功") login_status['is_login'] = True break print("您的账号或密码有误,请重新登陆!") # 这个是common 模块写的登录验证 @common.login_auth def shopping(): print('购物') login_status = { 'is_login': None } func_list = { '0': [register, '注册'], '1': [login, '登录'], '2': [shopping, '购物'], } # 这个是start.py 文件导入的开始文件,必须和那边名字一样 def run(): print("----功能清单如下----") for i in func_list: print(f"{i}. {func_list.get(i)[1]}") choice = input("请输入功能编号>>>:").strip() if choice in func_list: func_list.get(choice)[0]()
''' 这里编写登录验证装饰器 由于需要用到src.py 中的 login_status、login方法,所以要把 src 导入进来 ''' from core import src # 登录验证装饰器 def login_auth(func): def inner(*args, **kwargs): # 检查用户登录 if not src.login_status.get('is_login'): print("请先登录!") src.login() res = func(*args, **kwargs) return res return inner