MapReduce是大数据分布式计算框架,是大数据技术的一个核心。它主要有两个函数,Map() 和 Reduce()。直接使用MapReduce的这两个函数编程有些困难,所以Facebook推出了Hive。Hive支持使用 SQL 语法来进行大数据计算,比如说你可以写个 Select 语句进行数据查询,然后 Hive 会把 SQL 语句转化成 MapReduce 的计算程序。这样,熟悉数据库的数据分析师和工程师便可以无门槛地使用大数据进行数据分析和处理了。 但与此同时,Hive也把大数据分布式计算框架的核心知识点隐藏了。本文通过一个例子来解析一个Hive例子,将其还原到MapReduce函数,来理解MapReduce的核心思想与方法。
问题
分析如下 HiveQL,生成的 MapReduce 执行程序,map 函数输入是什么?输出是什么,reduce 函数输入是什么?输出是什么?
1 INSERT OVERWRITE TABLE pv_users 2 SELECT pv.pageid, u.age 3 FROM page_view pv 4 JOIN user u 5 ON (pv.userid = u.userid);
page_view 表和 user 表结构与数据示例如下
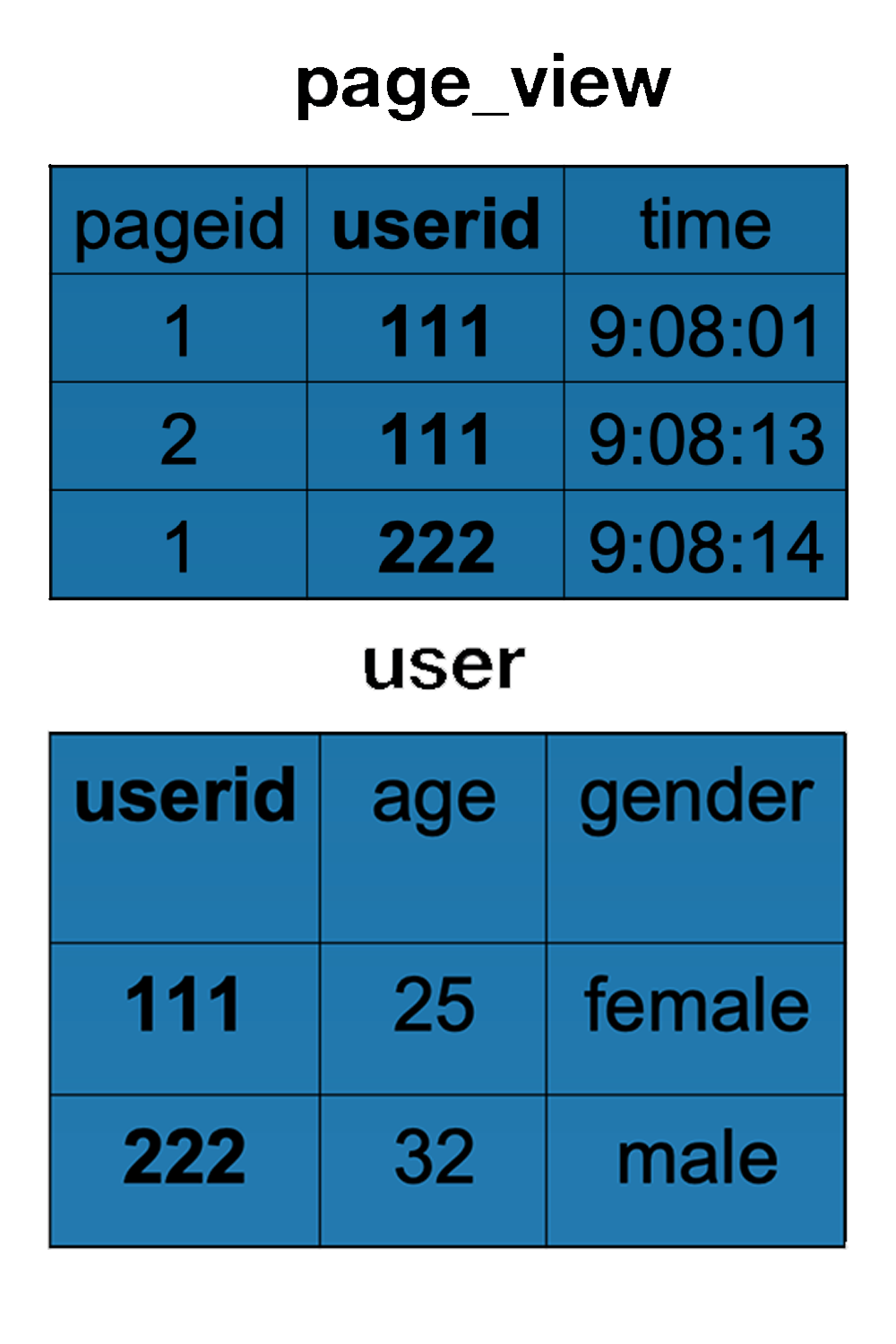
解析过程
该HiveQL语句是查询所有<pageid, age>的组合,而这两个信息分属不同的表,将这两者连接在一起的是userid。既然要处理两个表的数据,那么会有两个Map()函数,
- 第一个Map()函数统计page_view表。它的输入<key, value>中value是page_view的数据记录,输出的<key, value>中,key是userid,value是表名和pageid的组合;
- 第二个Map()函数统计user表。它的输入<key, value>中value是表记录,输出<key, value>中key是userid,value是表名和age的组合。
用userid做为Map()函数输出<key, value>中的key是一个关键信息,因为在Shuffle过程中需要用userid来将Map()的输出数据分类组合,然后传给Reduce()函数中。Reduce()函数的输入<key, values>中key是userid,values是来自于表1的pageid或者是来自于表2的age。Reduce()函数将这些信息整合,得到的输出<key, value>中value就是所有pageid和age的组合,也就是HiveQL查询想要得到的结果。至此,MapReduce过程结束,实现了HiveQL的查询结果。
总结
从上面的过程中可以看出,Map()函数将一组数据记录转化成一组KeyValue项,而Reduce()函数再将来源于所有Map()函数结果的KeyValue项聚合成一个值。以上面问题为例,假设有10个Map进程运行在10个不同的DB上,每个Map()输出都是每个userid的访问记录pageid和age;然后这个10个Map()结果都会以userid为key传给Reduce(),Reduce()将所有数据根据userid聚合,从而得出最终结果。